 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good is Your Wikipedia?
Nov 08, 2024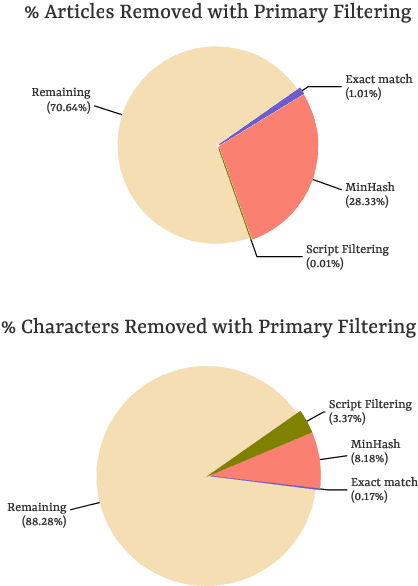

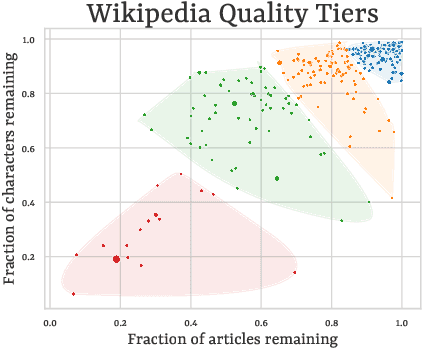
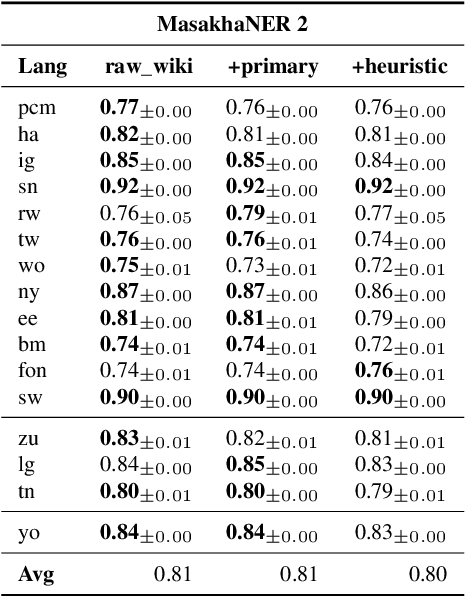
Wikipedia's perceived high quality and broad language coverage have established it as a fundamental resource in multilingual NLP. In the context of low-resource languages, however, these quality assumptions are increasingly being scrutinised. This paper critically examines the data quality of Wikipedia in a non-English setting by subjecting it to various quality filtering techniques, revealing widespread issues such as a high percentage of one-line articles and duplicate articles. We evaluate the downstream impact of quality filtering on Wikipedia and find that data quality pruning is an effective means for resource-efficient training without hurting performance, especially for low-resource languages. Moreover, we advocate for a shift in perspective from seeking a general definition of data quality towards a more language- and task-specific one. Ultimately, we aim for this study to serve as a guide to using Wikipedia for pretraining in a multilingual setting.
Word Order Does Matter (And Shuffled Language Models Know It)
Mar 21, 2022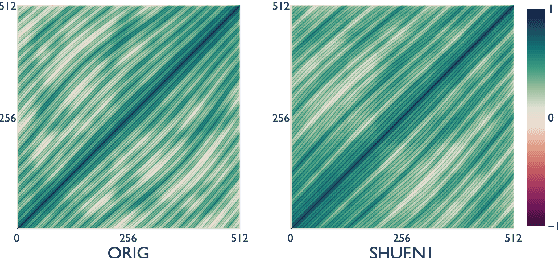
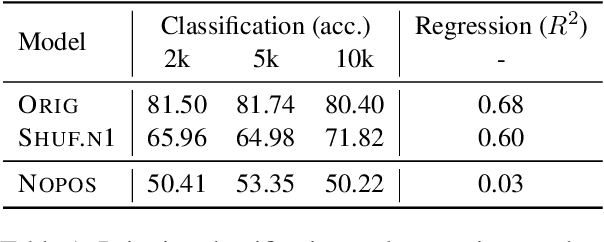
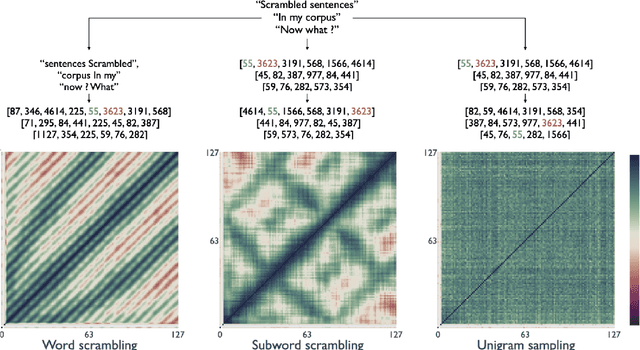
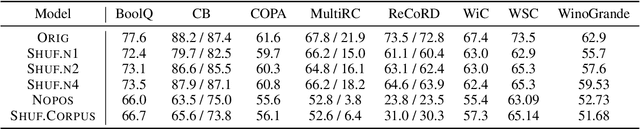
Recent studies have shown that language models pretrained and/or fine-tuned on randomly permuted sentences exhibit competitive performance on GLUE, putting into question the importance of word order information. Somewhat counter-intuitively, some of these studies also report that position embeddings appear to be crucial for models' good performance with shuffled text. We probe these language models for word order information and investigate what position embeddings learned from shuffled text encode, showing that these models retain information pertaining to the original, naturalistic word order. We show this is in part due to a subtlety in how shuffling is implemented in previous work -- before rather than after subword segmentation. Surprisingly, we find even Language models trained on text shuffled after subword segmentation retain some semblance of information about word order because of the statistical dependencies between sentence length and unigram probabilities. Finally, we show that beyond GLUE, a variety of language understanding tasks do require word order information, often to an extent that cannot be learned through fine-tuning.
Schrödinger's Tree -- On Syntax and Neural Language Models
Oct 17, 2021In the last half-decade, the field of natural language processing (NLP) has undergone two major transitions: the switch to neural networks as the primary modeling paradigm and the homogenization of the training regime (pre-train, then fine-tune). Amidst this process, language models have emerged as NLP's workhorse, displaying increasingly fluent generation capabilities and proving to be an indispensable means of knowledge transfer downstream. Due to the otherwise opaque, black-box nature of such models, researchers have employed aspects of linguistic theory in order to characterize their behavior. Questions central to syntax -- the study of the hierarchical structure of language -- have factored heavily into such work, shedding invaluable insights about models' inherent biases and their ability to make human-like generalizations. In this paper, we attempt to take stock of this growing body of literature. In doing so, we observe a lack of clarity across numerous dimensions, which influences the hypotheses that researchers form, as well as the conclusions they draw from their findings. To remedy this, we urge researchers make careful considerations when investigating coding properties, selecting representations, and evaluating via downstream tasks. Furthermore, we outline the implications of the different types of research questions exhibited in studies on syntax, as well as the inherent pitfalls of aggregate metrics. Ultimately, we hope that our discussion adds nuance to the prospect of studying language models and paves the way for a less monolithic perspective on syntax in this context.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021

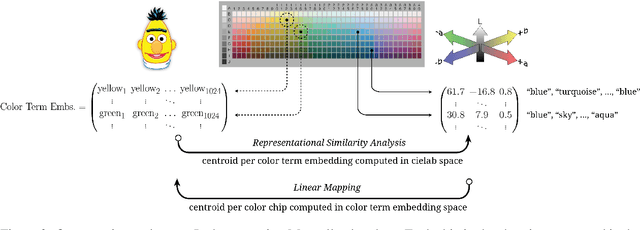
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
Attention Can Reflect Syntactic Structure (If You Let It)
Jan 26, 2021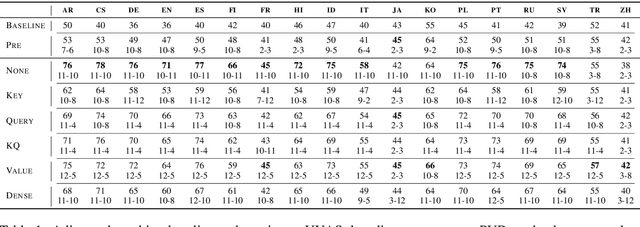
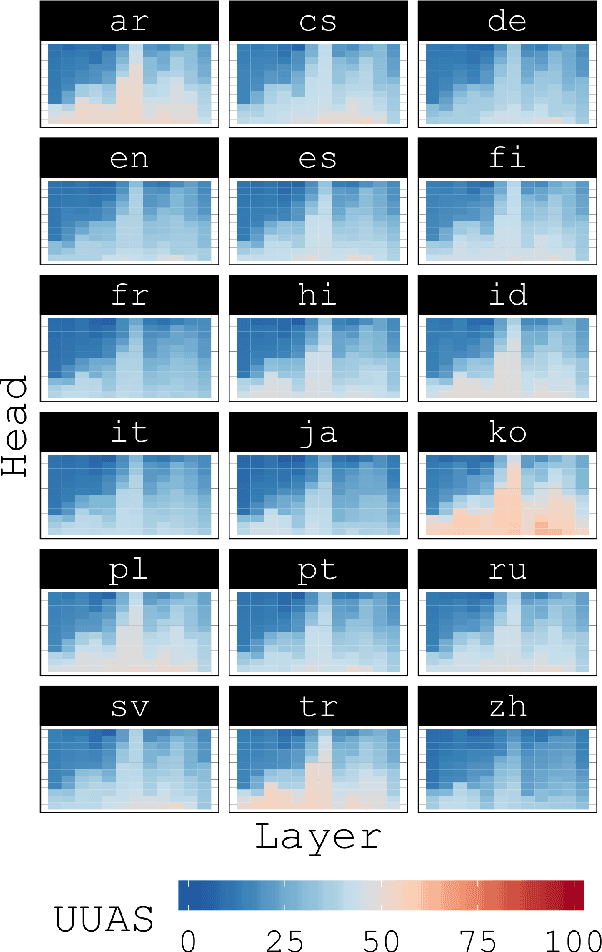
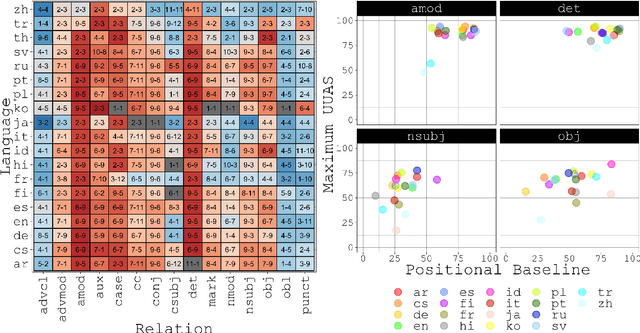
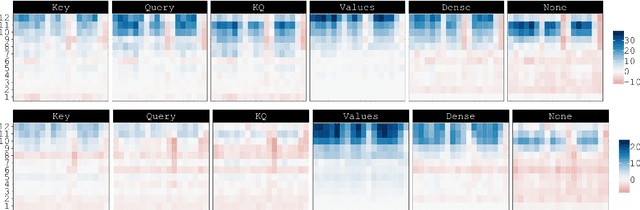
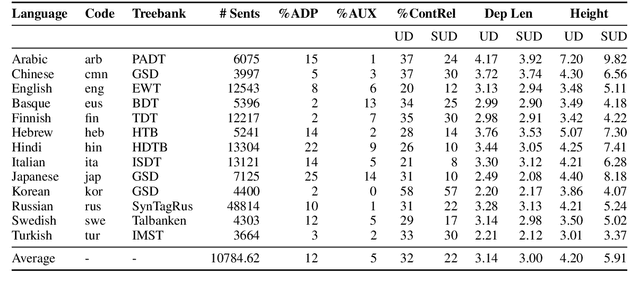
Since the popularization of the Transformer as a general-purpose feature encoder for NLP, many studies have attempted to decode linguistic structure from its novel multi-head attention mechanism. However, much of such work focused almost exclusively on English -- a language with rigid word order and a lack of inflectional morphology. In this study, we present decoding experiments for multilingual BERT across 18 languages in order to test the generalizability of the claim that dependency syntax is reflected in attention patterns. We show that full trees can be decoded above baseline accuracy from single attention heads, and that individual relations are often tracked by the same heads across languages. Furthermore, in an attempt to address recent debates about the status of attention as an explanatory mechanism, we experiment with fine-tuning mBERT on a supervised parsing objective while freezing different series of parameters. Interestingly, in steering the objective to learn explicit linguistic structure, we find much of the same structure represented in the resulting attention patterns, with interesting differences with respect to which parameters are frozen.
Køpsala: Transition-Based Graph Parsing via Efficient Training and Effective Encoding
Jun 02, 2020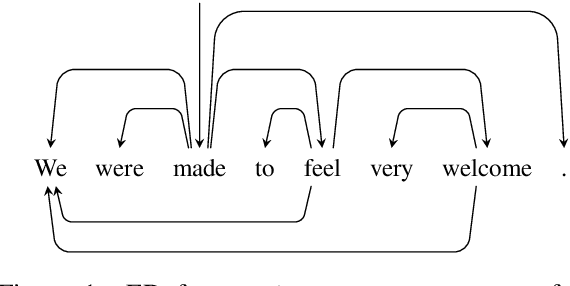
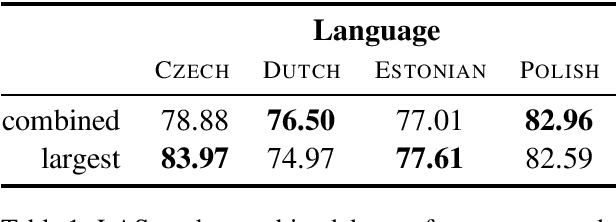

We present K{\o}psala, the Copenhagen-Uppsala system for the Enhanced Universal Dependencies Shared Task at IWPT 2020. Our system is a pipeline consisting of off-the-shelf models for everything but enhanced graph parsing, and for the latter, a transition-based graph parser adapted from Che et al. (2019). We train a single enhanced parser model per language, using gold sentence splitting and tokenization for training, and rely only on tokenized surface forms and multilingual BERT for encoding. While a bug introduced just before submission resulted in a severe drop in precision, its post-submission fix would bring us to 4th place in the official ranking, according to average ELAS. Our parser demonstrates that a unified pipeline is effective for both Meaning Representation Parsing and Enhanced Universal Dependencies.
Do Neural Language Models Show Preferences for Syntactic Formalisms?
Apr 29, 2020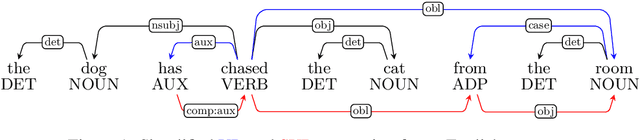


Recent work on the interpretability of deep neural language models has concluded that many properties of natural language syntax are encoded in their representational spaces. However, such studies often suffer from limited scope by focusing on a single language and a single linguistic formalism. In this study, we aim to investigate the extent to which the semblance of syntactic structure captured by language models adheres to a surface-syntactic or deep syntactic style of analysis, and whether the patterns are consistent across different languages. We apply a probe for extracting directed dependency trees to BERT and ELMo models trained on 13 different languages, probing for two different syntactic annotation styles: Universal Dependencies (UD), prioritizing deep syntactic relations, and Surface-Syntactic Universal Dependencies (SUD), focusing on surface structure. We find that both models exhibit a preference for UD over SUD - with interesting variations across languages and layers - and that the strength of this preference is correlated with differences in tree shape.
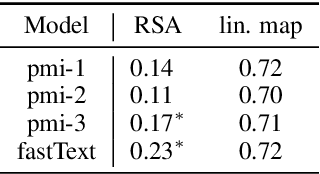
Higher-order Comparisons of Sentence Encoder Representations
Sep 05, 2019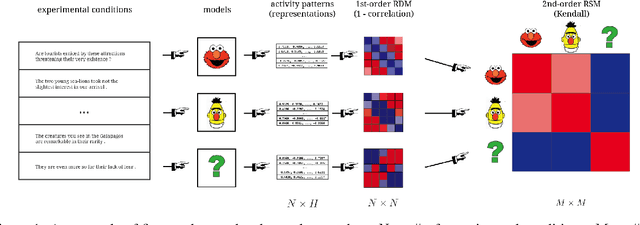

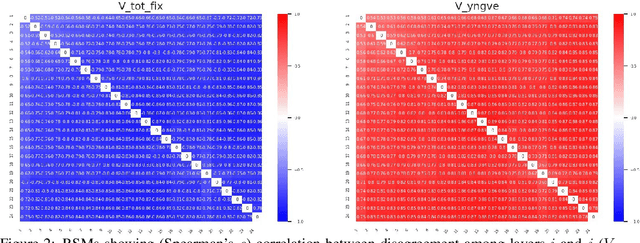
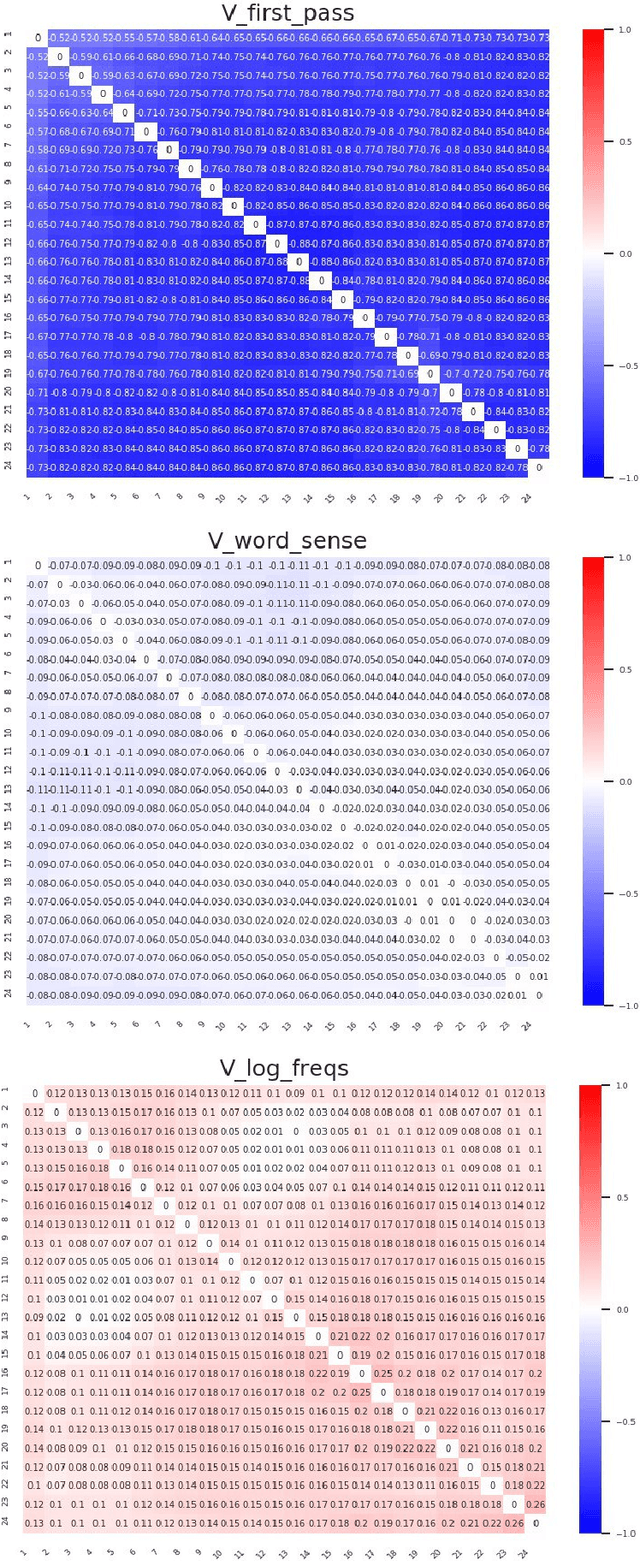
Representational Similarity Analysis (RSA) is a technique developed by neuroscientists for comparing activity patterns of different measurement modalities (e.g., fMRI, electrophysiology, behavior). As a framework, RSA has several advantages over existing approaches to interpretation of language encoders based on probing or diagnostic classification: namely, it does not require large training samples, is not prone to overfitting, and it enables a more transparent comparison between the representational geometries of different models and modalities. We demonstrate the utility of RSA by establishing a previously unknown correspondence between widely-employed pretrained language encoders and human processing difficulty via eye-tracking data, showcasing its potential in the interpretability toolbox for neural models
Deep Contextualized Word Embeddings in Transition-Based and Graph-Based Dependency Parsing -- A Tale of Two Parsers Revisited
Aug 27, 2019


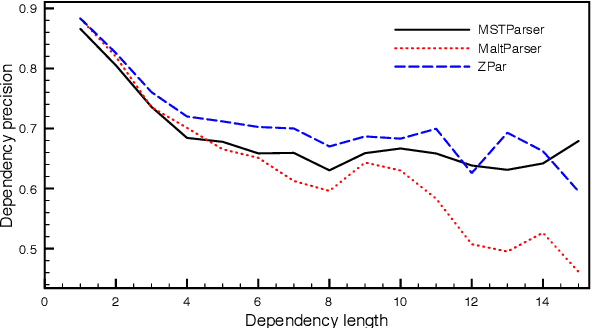
Transition-based and graph-based dependency parsers have previously been shown to have complementary strengths and weaknesses: transition-based parsers exploit rich structural features but suffer from error propagation, while graph-based parsers benefit from global optimization but have restricted feature scope. In this paper, we show that, even though some details of the picture have changed after the switch to neural networks and continuous representations, the basic trade-off between rich features and global optimization remains essentially the same. Moreover, we show that deep contextualized word embeddings, which allow parsers to pack information about global sentence structure into local feature representations, benefit transition-based parsers more than graph-based parsers, making the two approaches virtually equivalent in terms of both accuracy and error profile. We argue that the reason is that these representations help prevent search errors and thereby allow transition-based parsers to better exploit their inherent strength of making accurate local decisions. We support this explanation by an error analysis of parsing experiments on 13 languages.
What can we learn from Semantic Tagging?
Aug 29, 2018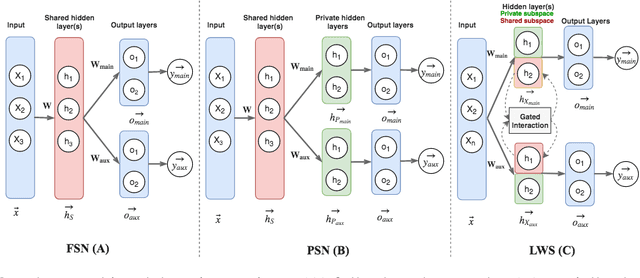
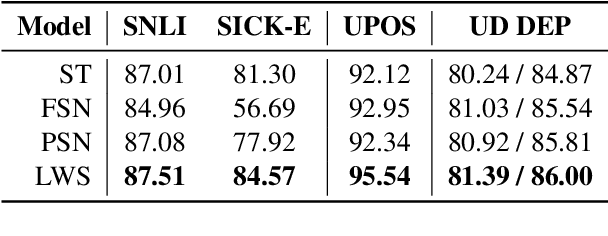

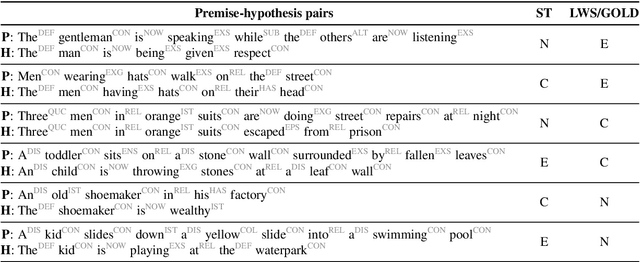
We investigate the effects of multi-task learning using the recently introduced task of semantic tagging. We employ semantic tagging as an auxiliary task for three different NLP tasks: part-of-speech tagging, Universal Dependency parsing, and Natural Language Inference. We compare full neural network sharing, partial neural network sharing, and what we term the learning what to share setting where negative transfer between tasks is less likely. Our findings show considerable improvements for all tasks, particularly in the learning what to share setting, which shows consistent gains across all tasks.