 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Brains with Language Models: A Survey
Jun 08, 2023Over the years, many researchers have seemingly made the same observation: Brain and language model activations exhibit some structural similarities, enabling linear partial mappings between features extracted from neural recordings and computational language models. In an attempt to evaluate how much evidence has been accumulated for this observation, we survey over 30 studies spanning 10 datasets and 8 metrics. How much evidence has been accumulated, and what, if anything, is missing before we can draw conclusions? Our analysis of the evaluation methods used in the literature reveals that some of the metrics are less conservative. We also find that the accumulated evidence, for now, remains ambiguous, but correlations with model size and quality provide grounds for cautious optimism.
Large Language Models Converge on Brain-Like Word Representations
Jun 02, 2023One of the greatest puzzles of all time is how understanding arises from neural mechanics. Our brains are networks of billions of biological neurons transmitting chemical and electrical signals along their connections. Large language models are networks of millions or billions of digital neurons, implementing functions that read the output of other functions in complex networks. The failure to see how meaning would arise from such mechanics has led many cognitive scientists and philosophers to various forms of dualism -- and many artificial intelligence researchers to dismiss large language models as stochastic parrots or jpeg-like compressions of text corpora. We show that human-like representations arise in large language models. Specifically, the larger neural language models get, the more their representations are structurally similar to neural response measurements from brain imaging.
Word Order Does Matter (And Shuffled Language Models Know It)
Mar 21, 2022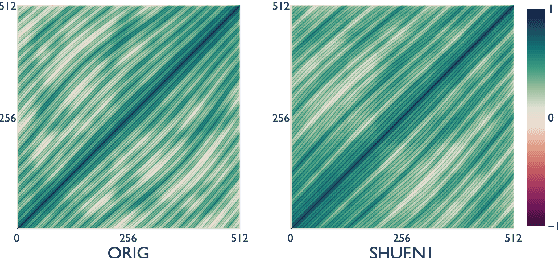
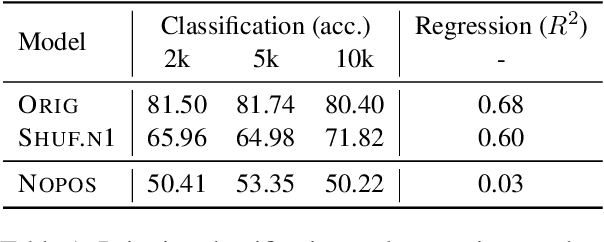
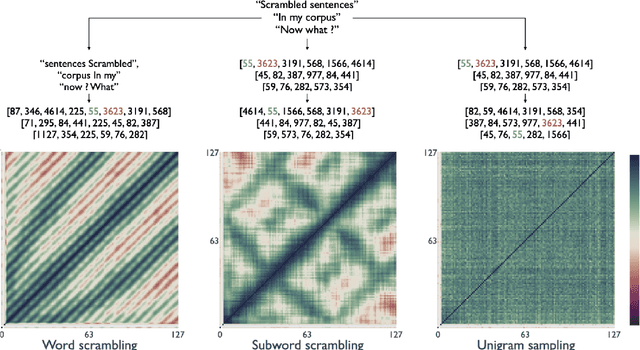
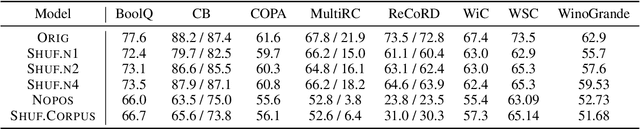
Recent studies have shown that language models pretrained and/or fine-tuned on randomly permuted sentences exhibit competitive performance on GLUE, putting into question the importance of word order information. Somewhat counter-intuitively, some of these studies also report that position embeddings appear to be crucial for models' good performance with shuffled text. We probe these language models for word order information and investigate what position embeddings learned from shuffled text encode, showing that these models retain information pertaining to the original, naturalistic word order. We show this is in part due to a subtlety in how shuffling is implemented in previous work -- before rather than after subword segmentation. Surprisingly, we find even Language models trained on text shuffled after subword segmentation retain some semblance of information about word order because of the statistical dependencies between sentence length and unigram probabilities. Finally, we show that beyond GLUE, a variety of language understanding tasks do require word order information, often to an extent that cannot be learned through fine-tuning.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.
Connecting Neural Response measurements & Computational Models of language: a non-comprehensive guide
Mar 10, 2022
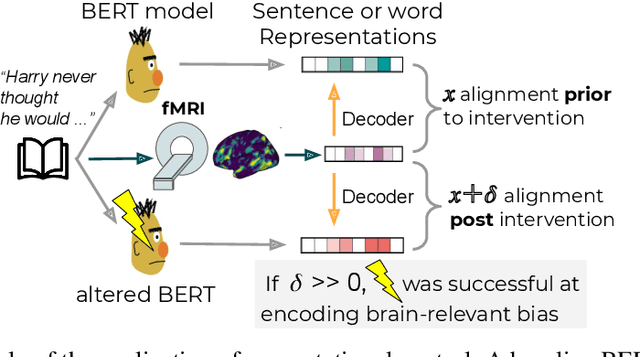
Understanding the neural basis of language comprehension in the brain has been a long-standing goal of various scientific research programs. Recent advances in language modelling and in neuroimaging methodology promise potential improvements in both the investigation of language's neurobiology and in the building of better and more human-like language models. This survey traces a line from early research linking Event Related Potentials and complexity measures derived from simple language models to contemporary studies employing Artificial Neural Network models trained on large corpora in combination with neural response recordings from multiple modalities using naturalistic stimuli.
Do We Still Need Automatic Speech Recognition for Spoken Language Understanding?
Nov 29, 2021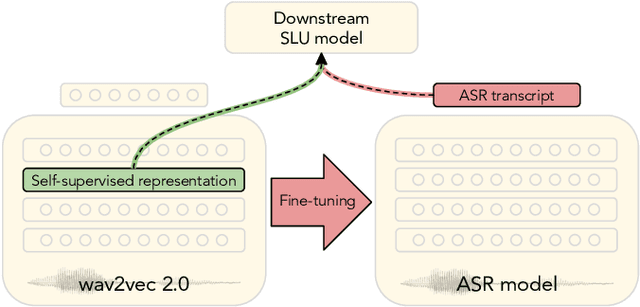

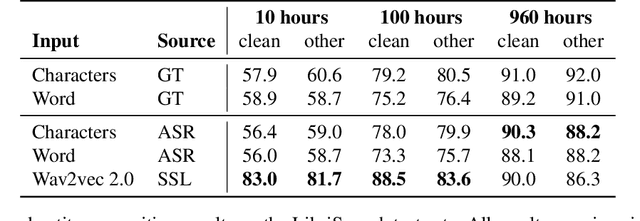
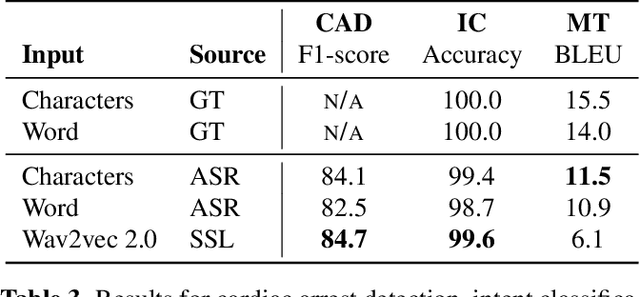
Spoken language understanding (SLU) tasks are usually solved by first transcribing an utterance with automatic speech recognition (ASR) and then feeding the output to a text-based model. Recent advances in self-supervised representation learning for speech data have focused on improving the ASR component. We investigate whether representation learning for speech has matured enough to replace ASR in SLU. We compare learned speech features from wav2vec 2.0, state-of-the-art ASR transcripts, and the ground truth text as input for a novel speech-based named entity recognition task, a cardiac arrest detection task on real-world emergency calls and two existing SLU benchmarks. We show that learned speech features are superior to ASR transcripts on three classification tasks. For machine translation, ASR transcripts are still the better choice. We highlight the intrinsic robustness of wav2vec 2.0 representations to out-of-vocabulary words as key to better performance.
Do Language Models Know the Way to Rome?
Sep 16, 2021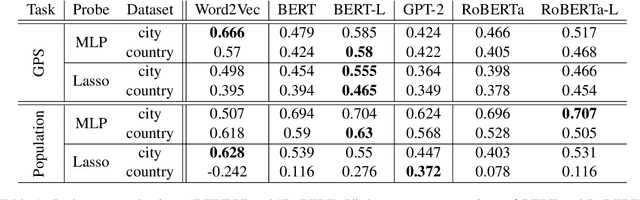
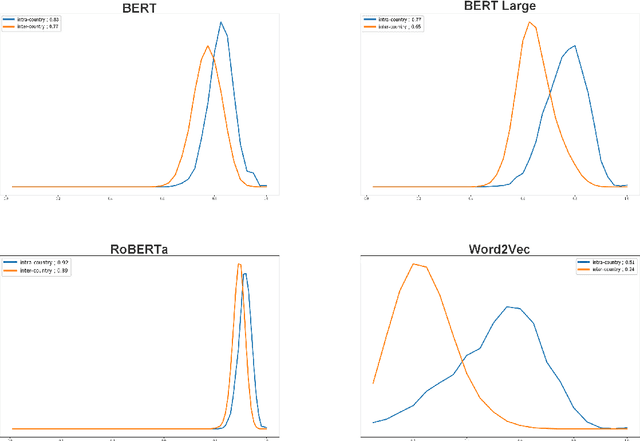

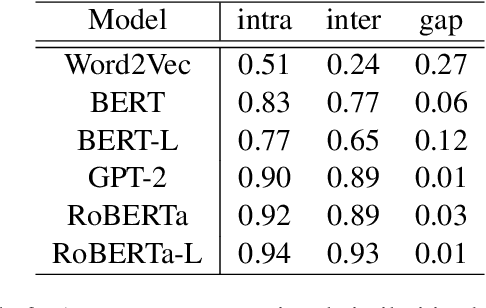
The global geometry of language models is important for a range of applications, but language model probes tend to evaluate rather local relations, for which ground truths are easily obtained. In this paper we exploit the fact that in geography, ground truths are available beyond local relations. In a series of experiments, we evaluate the extent to which language model representations of city and country names are isomorphic to real-world geography, e.g., if you tell a language model where Paris and Berlin are, does it know the way to Rome? We find that language models generally encode limited geographic information, but with larger models performing the best, suggesting that geographic knowledge can be induced from higher-order co-occurrence statistics.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021

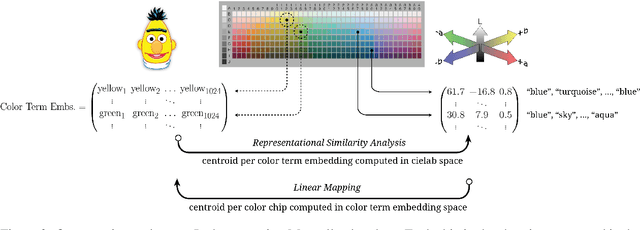
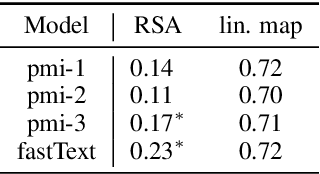
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
Does injecting linguistic structure into language models lead to better alignment with brain recordings?
Jan 29, 2021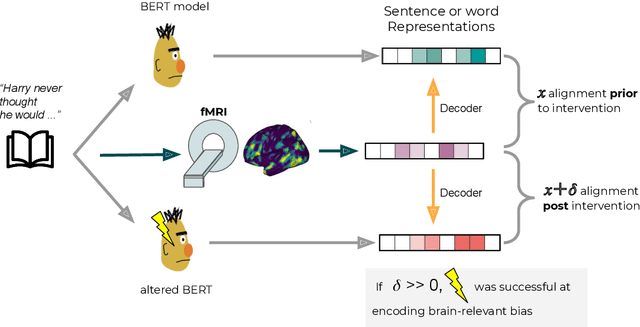
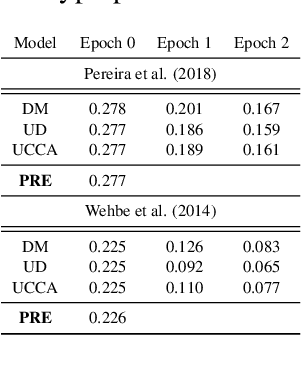
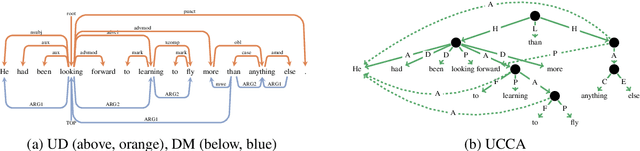
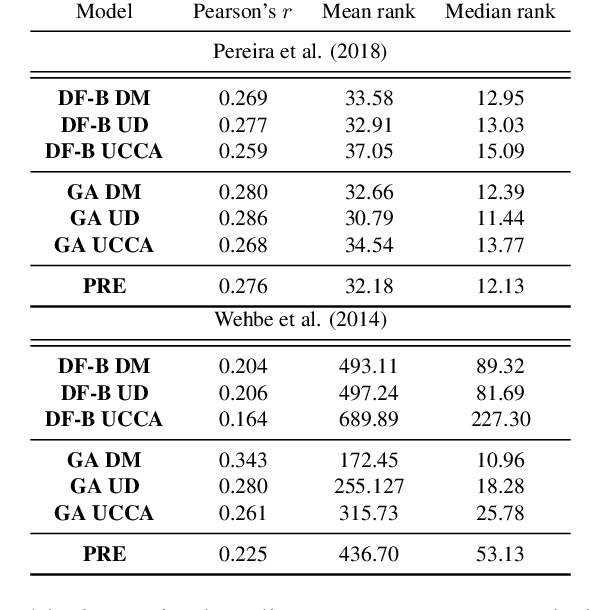
Neuroscientists evaluate deep neural networks for natural language processing as possible candidate models for how language is processed in the brain. These models are often trained without explicit linguistic supervision, but have been shown to learn some linguistic structure in the absence of such supervision (Manning et al., 2020), potentially questioning the relevance of symbolic linguistic theories in modeling such cognitive processes (Warstadt and Bowman, 2020). We evaluate across two fMRI datasets whether language models align better with brain recordings, if their attention is biased by annotations from syntactic or semantic formalisms. Using structure from dependency or minimal recursion semantic annotations, we find alignments improve significantly for one of the datasets. For another dataset, we see more mixed results. We present an extensive analysis of these results. Our proposed approach enables the evaluation of more targeted hypotheses about the composition of meaning in the brain, expanding the range of possible scientific inferences a neuroscientist could make, and opens up new opportunities for cross-pollination between computational neuroscience and linguistics.
Attention Can Reflect Syntactic Structure (If You Let It)
Jan 26, 2021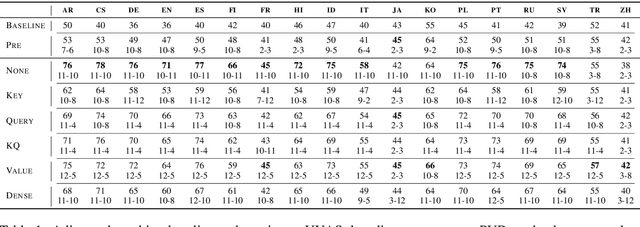
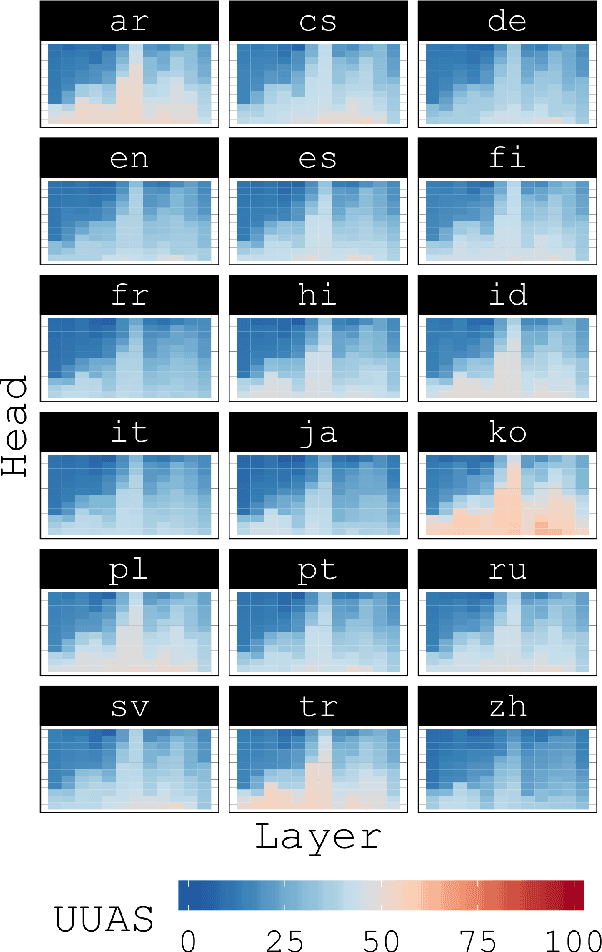
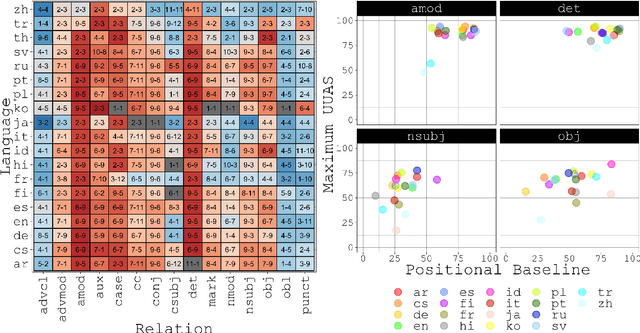
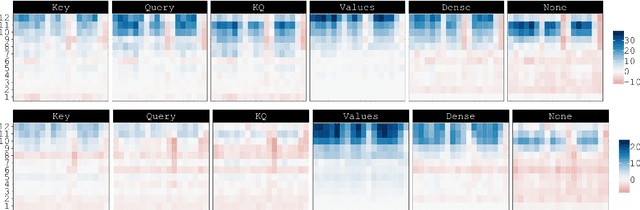
Since the popularization of the Transformer as a general-purpose feature encoder for NLP, many studies have attempted to decode linguistic structure from its novel multi-head attention mechanism. However, much of such work focused almost exclusively on English -- a language with rigid word order and a lack of inflectional morphology. In this study, we present decoding experiments for multilingual BERT across 18 languages in order to test the generalizability of the claim that dependency syntax is reflected in attention patterns. We show that full trees can be decoded above baseline accuracy from single attention heads, and that individual relations are often tracked by the same heads across languages. Furthermore, in an attempt to address recent debates about the status of attention as an explanatory mechanism, we experiment with fine-tuning mBERT on a supervised parsing objective while freezing different series of parameters. Interestingly, in steering the objective to learn explicit linguistic structure, we find much of the same structure represented in the resulting attention patterns, with interesting differences with respect to which parameters are frozen.