 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Interaction of Belief Bias and Explanations
Jun 29, 2021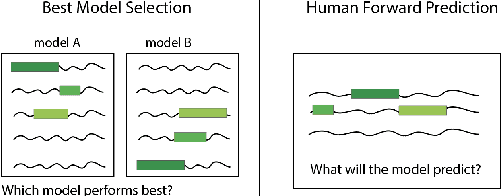
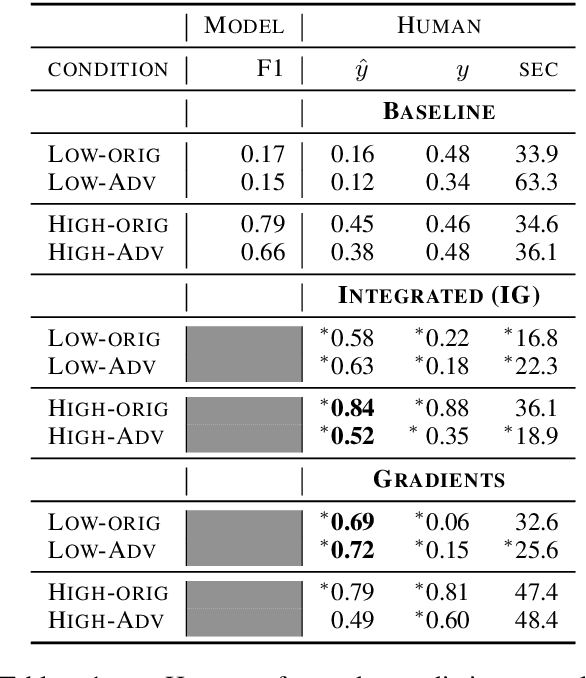

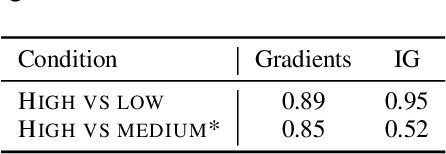
A myriad of explainability methods have been proposed in recent years, but there is little consensus on how to evaluate them. While automatic metrics allow for quick benchmarking, it isn't clear how such metrics reflect human interaction with explanations. Human evaluation is of paramount importance, but previous protocols fail to account for belief biases affecting human performance, which may lead to misleading conclusions. We provide an overview of belief bias, its role in human evaluation, and ideas for NLP practitioners on how to account for it. For two experimental paradigms, we present a case study of gradient-based explainability introducing simple ways to account for humans' prior beliefs: models of varying quality and adversarial examples. We show that conclusions about the highest performing methods change when introducing such controls, pointing to the importance of accounting for belief bias in evaluation.
Does injecting linguistic structure into language models lead to better alignment with brain recordings?
Jan 29, 2021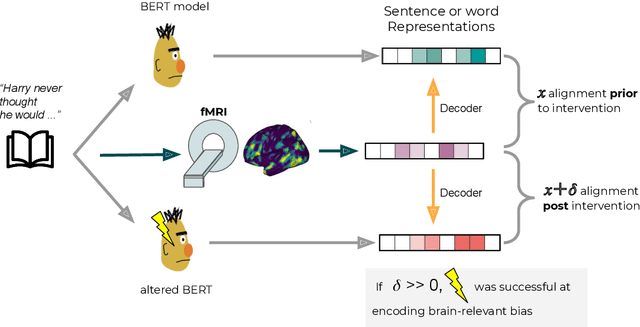
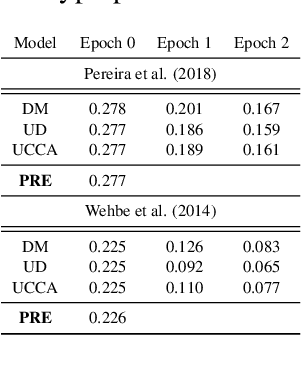
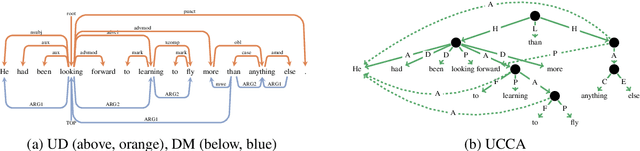
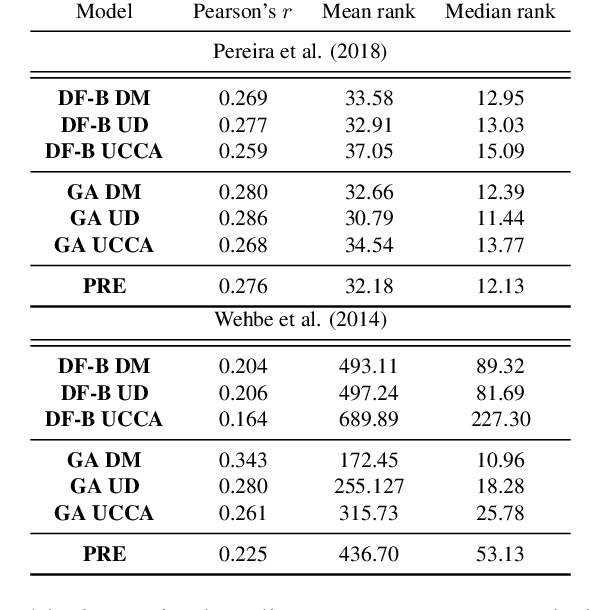
Neuroscientists evaluate deep neural networks for natural language processing as possible candidate models for how language is processed in the brain. These models are often trained without explicit linguistic supervision, but have been shown to learn some linguistic structure in the absence of such supervision (Manning et al., 2020), potentially questioning the relevance of symbolic linguistic theories in modeling such cognitive processes (Warstadt and Bowman, 2020). We evaluate across two fMRI datasets whether language models align better with brain recordings, if their attention is biased by annotations from syntactic or semantic formalisms. Using structure from dependency or minimal recursion semantic annotations, we find alignments improve significantly for one of the datasets. For another dataset, we see more mixed results. We present an extensive analysis of these results. Our proposed approach enables the evaluation of more targeted hypotheses about the composition of meaning in the brain, expanding the range of possible scientific inferences a neuroscientist could make, and opens up new opportunities for cross-pollination between computational neuroscience and linguistics.
Human Evaluation of Spoken vs. Visual Explanations for Open-Domain QA
Dec 30, 2020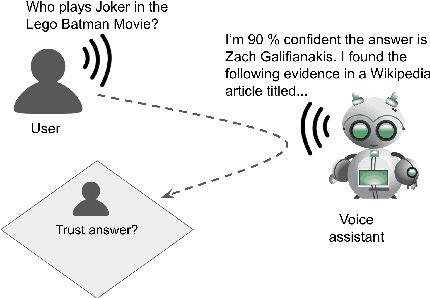
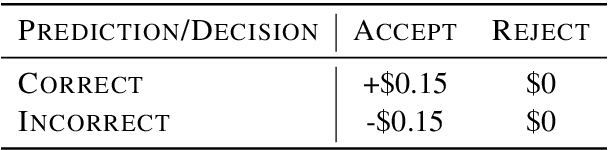


While research on explaining predictions of open-domain QA systems (ODQA) to users is gaining momentum, most works have failed to evaluate the extent to which explanations improve user trust. While few works evaluate explanations using user studies, they employ settings that may deviate from the end-user's usage in-the-wild: ODQA is most ubiquitous in voice-assistants, yet current research only evaluates explanations using a visual display, and may erroneously extrapolate conclusions about the most performant explanations to other modalities. To alleviate these issues, we conduct user studies that measure whether explanations help users correctly decide when to accept or reject an ODQA system's answer. Unlike prior work, we control for explanation modality, e.g., whether they are communicated to users through a spoken or visual interface, and contrast effectiveness across modalities. Our results show that explanations derived from retrieved evidence passages can outperform strong baselines (calibrated confidence) across modalities but the best explanation strategy in fact changes with the modality. We show common failure cases of current explanations, emphasize end-to-end evaluation of explanations, and caution against evaluating them in proxy modalities that are different from deployment.
Type B Reflexivization as an Unambiguous Testbed for Multilingual Multi-Task Gender Bias
Sep 28, 2020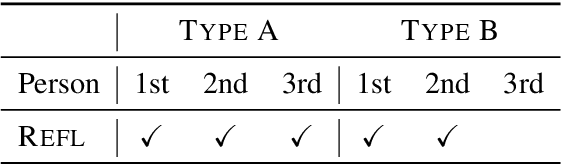
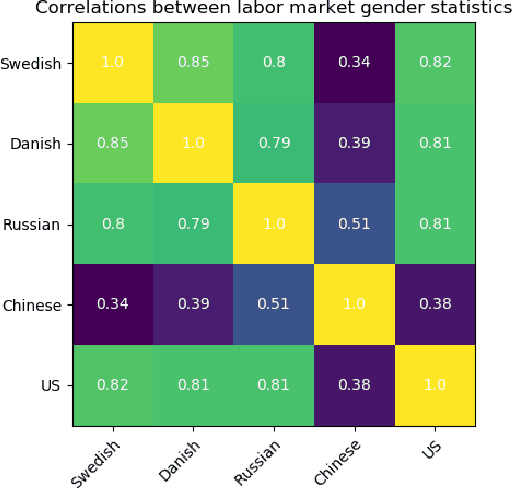


The one-sided focus on English in previous studies of gender bias in NLP misses out on opportunities in other languages: English challenge datasets such as GAP and WinoGender highlight model preferences that are "hallucinatory", e.g., disambiguating gender-ambiguous occurrences of 'doctor' as male doctors. We show that for languages with type B reflexivization, e.g., Swedish and Russian, we can construct multi-task challenge datasets for detecting gender bias that lead to unambiguously wrong model predictions: In these languages, the direct translation of 'the doctor removed his mask' is not ambiguous between a coreferential reading and a disjoint reading. Instead, the coreferential reading requires a non-gendered pronoun, and the gendered, possessive pronouns are anti-reflexive. We present a multilingual, multi-task challenge dataset, which spans four languages and four NLP tasks and focuses only on this phenomenon. We find evidence for gender bias across all task-language combinations and correlate model bias with national labor market statistics.
Retrieval-based Goal-Oriented Dialogue Generation
Sep 30, 2019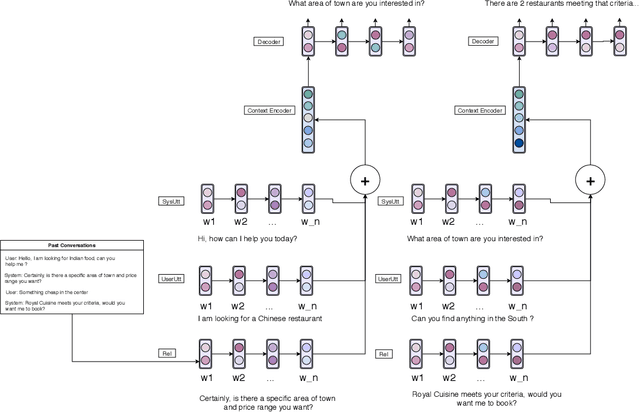

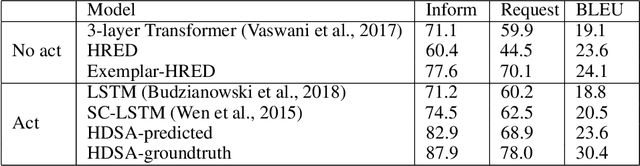
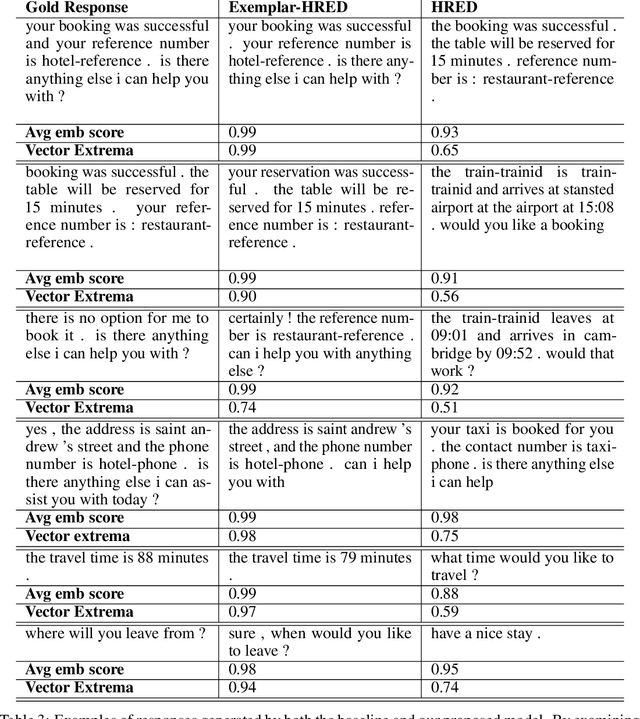
Most research on dialogue has focused either on dialogue generation for openended chit chat or on state tracking for goal-directed dialogue. In this work, we explore a hybrid approach to goal-oriented dialogue generation that combines retrieval from past history with a hierarchical, neural encoder-decoder architecture. We evaluate this approach in the customer support domain using the Multiwoz dataset (Budzianowski et al., 2018). We show that adding this retrieval step to a hierarchical, neural encoder-decoder architecture leads to significant improvements, including responses that are rated more appropriate and fluent by human evaluators. Finally, we compare our retrieval-based model to various semantically conditioned models explicitly using past dialog act information, and find that our proposed model is competitive with the current state of the art (Chen et al., 2019), while not requiring explicit labels about past machine acts.
Domain Transfer in Dialogue Systems without Turn-Level Supervision
Sep 16, 2019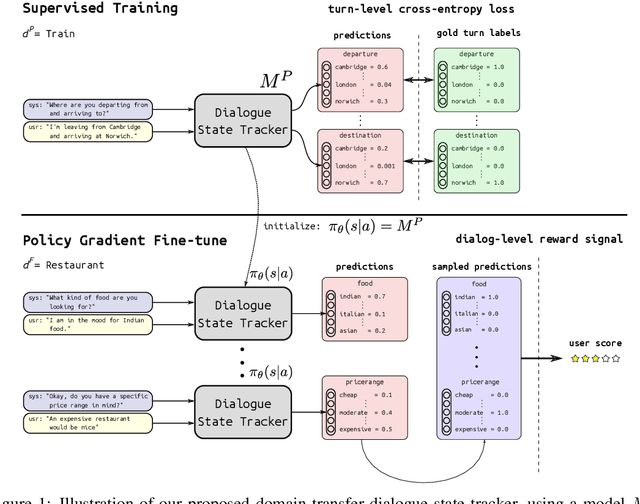
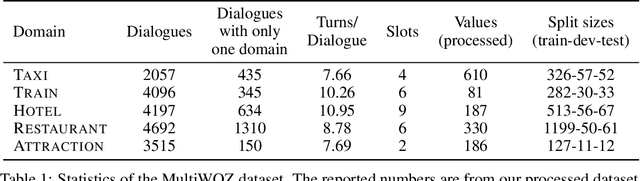
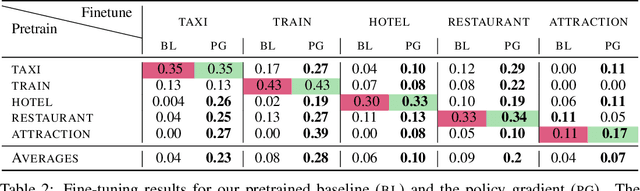
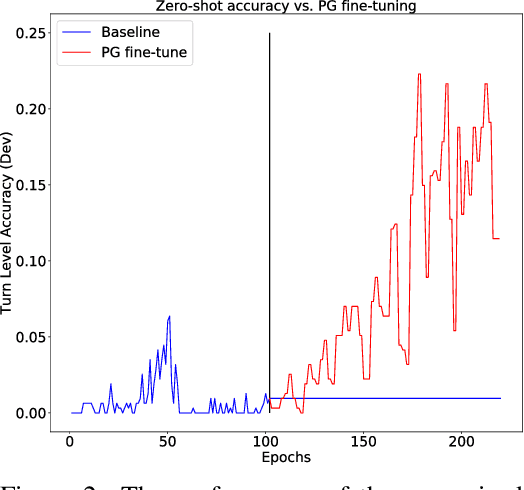
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent throughout the conversation. State-of-the-art DST models are typically trained in a supervised manner from manual annotations at the turn level. However, these annotations are costly to obtain, which makes it difficult to create accurate dialogue systems for new domains. To address these limitations, we propose a method, based on reinforcement learning, for transferring DST models to new domains without turn-level supervision. Across several domains, our experiments show that this method quickly adapts off-the-shelf models to new domains and performs on par with models trained with turn-level supervision. We also show our method can improve models trained using turn-level supervision by subsequent fine-tuning optimization toward dialog-level rewards.
Rewarding Coreference Resolvers for Being Consistent with World Knowledge
Sep 05, 2019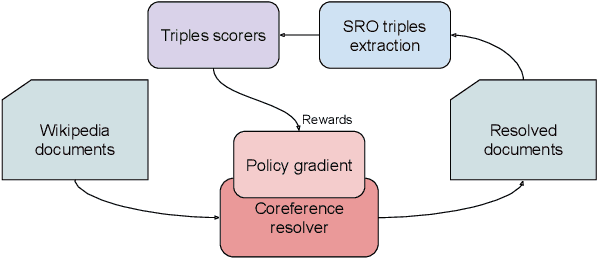
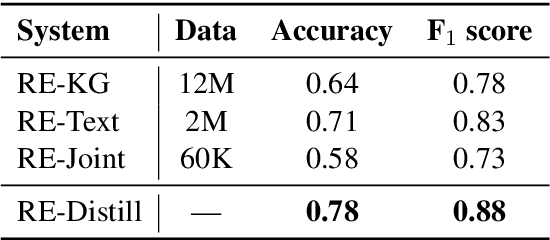
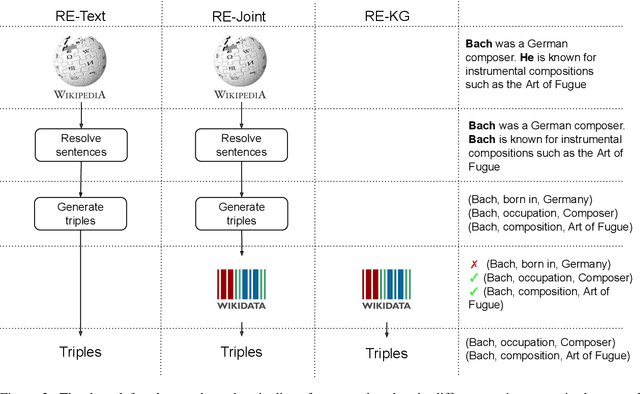
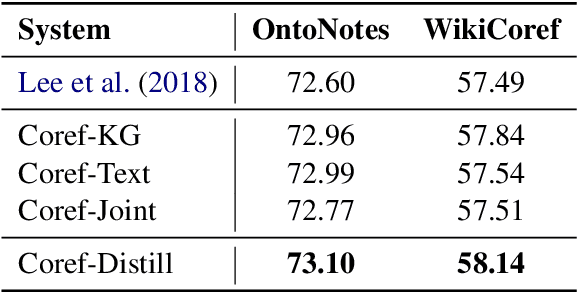
Unresolved coreference is a bottleneck for relation extraction, and high-quality coreference resolvers may produce an output that makes it a lot easier to extract knowledge triples. We show how to improve coreference resolvers by forwarding their input to a relation extraction system and reward the resolvers for producing triples that are found in knowledge bases. Since relation extraction systems can rely on different forms of supervision and be biased in different ways, we obtain the best performance, improving over the state of the art, using multi-task reinforcement learning.