 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePheme: Efficient and Conversational Speech Generation
Jan 05, 2024In recent years, speech generation has seen remarkable progress, now achieving one-shot generation capability that is often virtually indistinguishable from real human voice. Integrating such advancements in speech generation with large language models might revolutionize a wide range of applications. However, certain applications, such as assistive conversational systems, require natural and conversational speech generation tools that also operate efficiently in real time. Current state-of-the-art models like VALL-E and SoundStorm, powered by hierarchical neural audio codecs, require large neural components and extensive training data to work well. In contrast, MQTTS aims to build more compact conversational TTS models while capitalizing on smaller-scale real-life conversational speech data. However, its autoregressive nature yields high inference latency and thus limits its real-time usage. In order to mitigate the current limitations of the state-of-the-art TTS models while capitalizing on their strengths, in this work we introduce the Pheme model series that 1) offers compact yet high-performing models, 2) allows for parallel speech generation of 3) natural conversational speech, and 4) it can be trained efficiently on smaller-scale conversational data, cutting data demands by more than 10x but still matching the quality of the autoregressive TTS models. We also show that through simple teacher-student distillation we can meet significant improvements in voice quality for single-speaker setups on top of pretrained Pheme checkpoints, relying solely on synthetic speech generated by much larger teacher models. Audio samples and pretrained models are available online.
$\textit{Dial BeInfo for Faithfulness}$: Improving Factuality of Information-Seeking Dialogue via Behavioural Fine-Tuning
Nov 16, 2023



Factuality is a crucial requirement in information seeking dialogue: the system should respond to the user's queries so that the responses are meaningful and aligned with the knowledge provided to the system. However, most modern large language models suffer from hallucinations, that is, they generate responses not supported by or contradicting the knowledge source. To mitigate the issue and increase faithfulness of information-seeking dialogue systems, we introduce BeInfo, a simple yet effective method that applies behavioural tuning to aid information-seeking dialogue. Relying on three standard datasets, we show that models tuned with BeInfo} become considerably more faithful to the knowledge source both for datasets and domains seen during BeInfo-tuning, as well as on unseen domains, when applied in a zero-shot manner. In addition, we show that the models with 3B parameters (e.g., Flan-T5) tuned with BeInfo demonstrate strong performance on data from real `production' conversations and outperform GPT4 when tuned on a limited amount of such realistic in-domain dialogues.
Knowledge-Aware Audio-Grounded Generative Slot Filling for Limited Annotated Data
Jul 04, 2023Manually annotating fine-grained slot-value labels for task-oriented dialogue (ToD) systems is an expensive and time-consuming endeavour. This motivates research into slot-filling methods that operate with limited amounts of labelled data. Moreover, the majority of current work on ToD is based solely on text as the input modality, neglecting the additional challenges of imperfect automatic speech recognition (ASR) when working with spoken language. In this work, we propose a Knowledge-Aware Audio-Grounded generative slot-filling framework, termed KA2G, that focuses on few-shot and zero-shot slot filling for ToD with speech input. KA2G achieves robust and data-efficient slot filling for speech-based ToD by 1) framing it as a text generation task, 2) grounding text generation additionally in the audio modality, and 3) conditioning on available external knowledge (e.g. a predefined list of possible slot values). We show that combining both modalities within the KA2G framework improves the robustness against ASR errors. Further, the knowledge-aware slot-value generator in KA2G, implemented via a pointer generator mechanism, particularly benefits few-shot and zero-shot learning. Experiments, conducted on the standard speech-based single-turn SLURP dataset and a multi-turn dataset extracted from a commercial ToD system, display strong and consistent gains over prior work, especially in few-shot and zero-shot setups.
NLU++: A Multi-Label, Slot-Rich, Generalisable Dataset for Natural Language Understanding in Task-Oriented Dialogue
May 05, 2022



We present NLU++, a novel dataset for natural language understanding (NLU) in task-oriented dialogue (ToD) systems, with the aim to provide a much more challenging evaluation environment for dialogue NLU models, up to date with the current application and industry requirements. NLU++ is divided into two domains (BANKING and HOTELS) and brings several crucial improvements over current commonly used NLU datasets. 1) NLU++ provides fine-grained domain ontologies with a large set of challenging multi-intent sentences, introducing and validating the idea of intent modules that can be combined into complex intents that convey complex user goals, combined with finer-grained and thus more challenging slot sets. 2) The ontology is divided into domain-specific and generic (i.e., domain-universal) intent modules that overlap across domains, promoting cross-domain reusability of annotated examples. 3) The dataset design has been inspired by the problems observed in industrial ToD systems, and 4) it has been collected, filtered and carefully annotated by dialogue NLU experts, yielding high-quality annotated data. Finally, we benchmark a series of current state-of-the-art NLU models on NLU++; the results demonstrate the challenging nature of the dataset, especially in low-data regimes, the validity of `intent modularisation', and call for further research on ToD NLU.
EVI: Multilingual Spoken Dialogue Tasks and Dataset for Knowledge-Based Enrolment, Verification, and Identification
Apr 28, 2022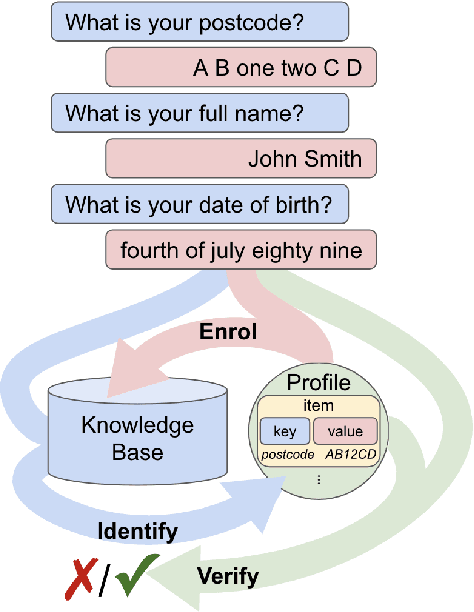
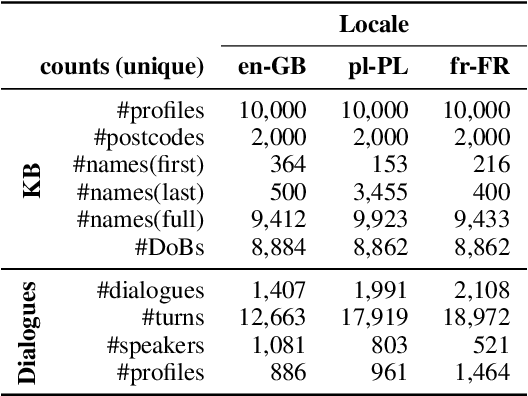
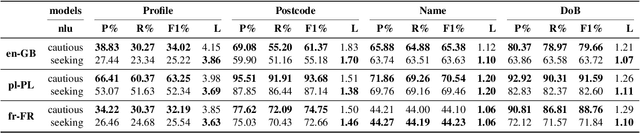
Knowledge-based authentication is crucial for task-oriented spoken dialogue systems that offer personalised and privacy-focused services. Such systems should be able to enrol (E), verify (V), and identify (I) new and recurring users based on their personal information, e.g. postcode, name, and date of birth. In this work, we formalise the three authentication tasks and their evaluation protocols, and we present EVI, a challenging spoken multilingual dataset with 5,506 dialogues in English, Polish, and French. Our proposed models set the first competitive benchmarks, explore the challenges of multilingual natural language processing of spoken dialogue, and set directions for future research.
Improved and Efficient Conversational Slot Labeling through Question Answering
Apr 05, 2022
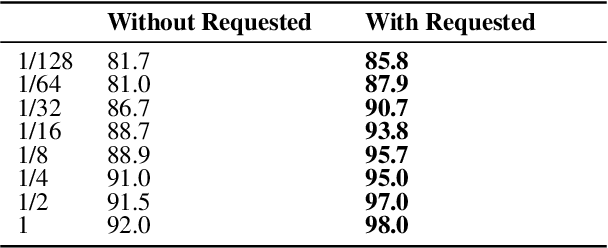
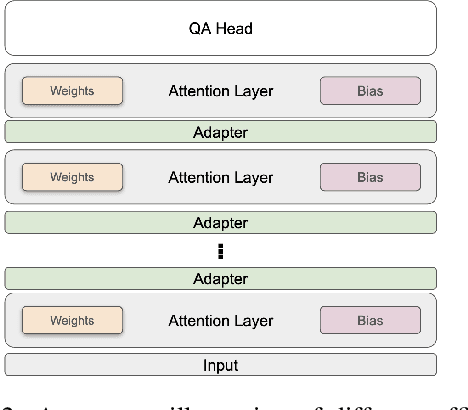
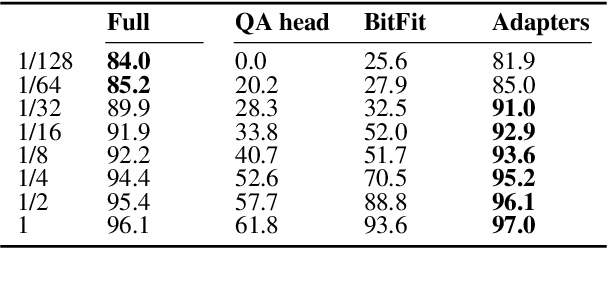
Transformer-based pretrained language models (PLMs) offer unmatched performance across the majority of natural language understanding (NLU) tasks, including a body of question answering (QA) tasks. We hypothesize that improvements in QA methodology can also be directly exploited in dialog NLU; however, dialog tasks must be \textit{reformatted} into QA tasks. In particular, we focus on modeling and studying \textit{slot labeling} (SL), a crucial component of NLU for dialog, through the QA optics, aiming to improve both its performance and efficiency, and make it more effective and resilient to working with limited task data. To this end, we make a series of contributions: 1) We demonstrate how QA-tuned PLMs can be applied to the SL task, reaching new state-of-the-art performance, with large gains especially pronounced in such low-data regimes. 2) We propose to leverage contextual information, required to tackle ambiguous values, simply through natural language. 3) Efficiency and compactness of QA-oriented fine-tuning are boosted through the use of lightweight yet effective adapter modules. 4) Trading-off some of the quality of QA datasets for their size, we experiment with larger automatically generated QA datasets for QA-tuning, arriving at even higher performance. Finally, our analysis suggests that our novel QA-based slot labeling models, supported by the PLMs, reach a performance ceiling in high-data regimes, calling for more challenging and more nuanced benchmarks in future work.
ConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021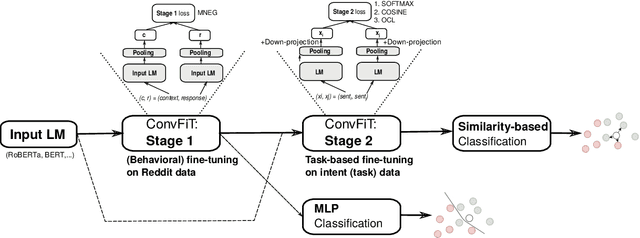
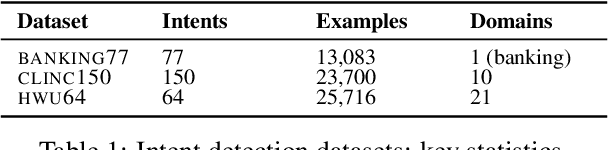

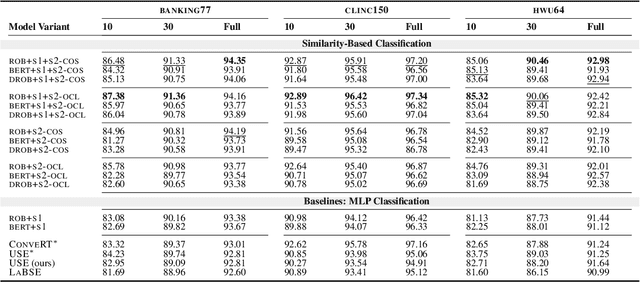
Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Semi-supervised Bootstrapping of Dialogue State Trackers for Task Oriented Modelling
Nov 26, 2019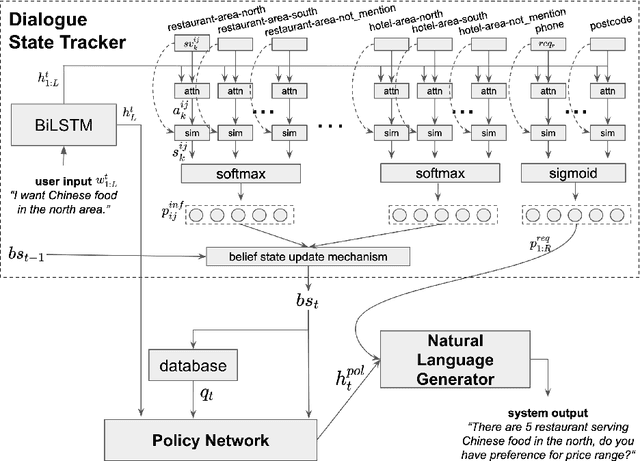

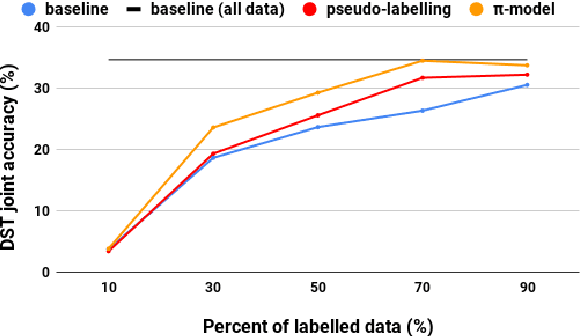
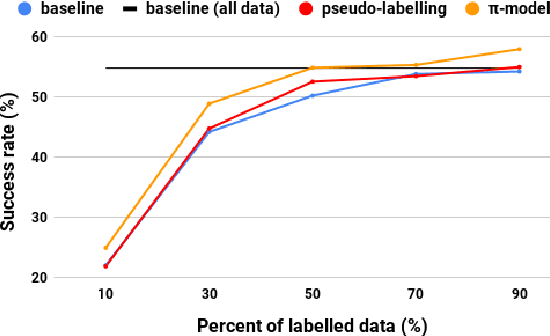
Dialogue systems benefit greatly from optimizing on detailed annotations, such as transcribed utterances, internal dialogue state representations and dialogue act labels. However, collecting these annotations is expensive and time-consuming, holding back development in the area of dialogue modelling. In this paper, we investigate semi-supervised learning methods that are able to reduce the amount of required intermediate labelling. We find that by leveraging un-annotated data instead, the amount of turn-level annotations of dialogue state can be significantly reduced when building a neural dialogue system. Our analysis on the MultiWOZ corpus, covering a range of domains and topics, finds that annotations can be reduced by up to 30\% while maintaining equivalent system performance. We also describe and evaluate the first end-to-end dialogue model created for the MultiWOZ corpus.
Tree-Structured Semantic Encoder with Knowledge Sharing for Domain Adaptation in Natural Language Generation
Oct 02, 2019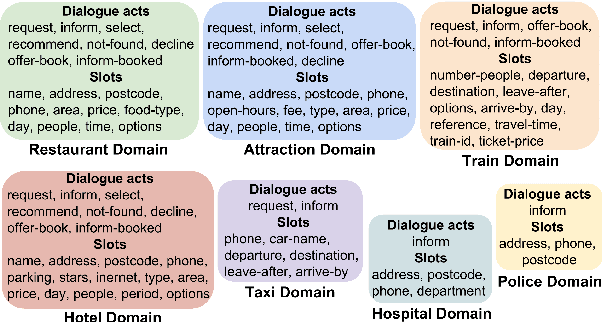
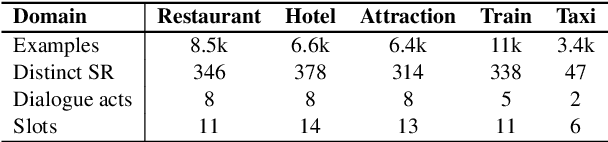
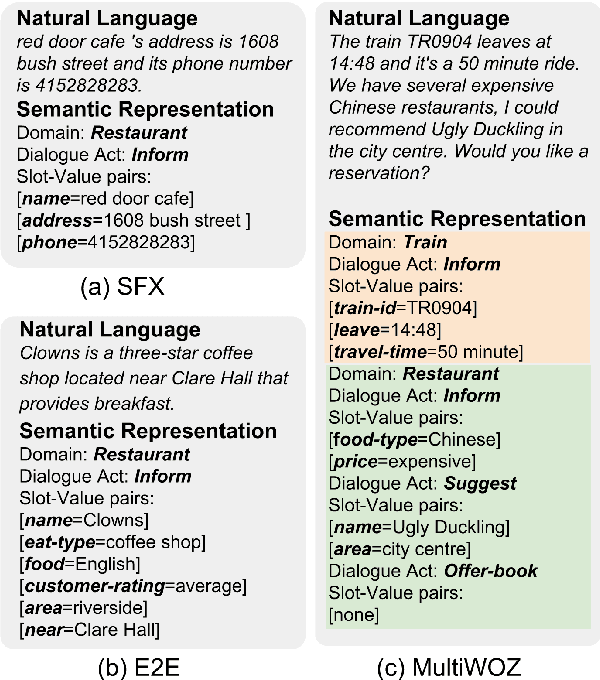
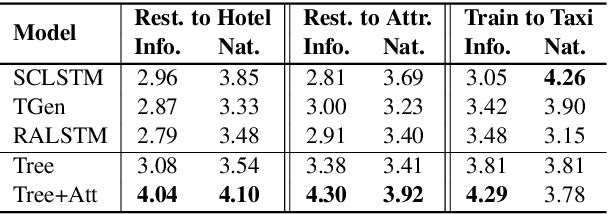
Domain adaptation in natural language generation (NLG) remains challenging because of the high complexity of input semantics across domains and limited data of a target domain. This is particularly the case for dialogue systems, where we want to be able to seamlessly include new domains into the conversation. Therefore, it is crucial for generation models to share knowledge across domains for the effective adaptation from one domain to another. In this study, we exploit a tree-structured semantic encoder to capture the internal structure of complex semantic representations required for multi-domain dialogues in order to facilitate knowledge sharing across domains. In addition, a layer-wise attention mechanism between the tree encoder and the decoder is adopted to further improve the model's capability. The automatic evaluation results show that our model outperforms previous methods in terms of the BLEU score and the slot error rate, in particular when the adaptation data is limited. In subjective evaluation, human judges tend to prefer the sentences generated by our model, rating them more highly on informativeness and naturalness than other systems.
Domain Transfer in Dialogue Systems without Turn-Level Supervision
Sep 16, 2019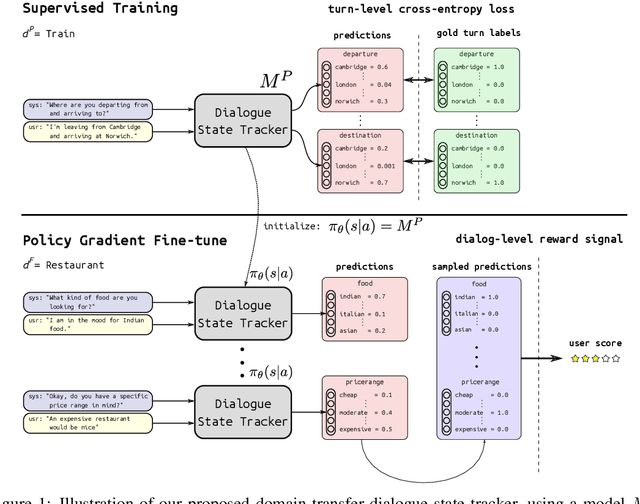
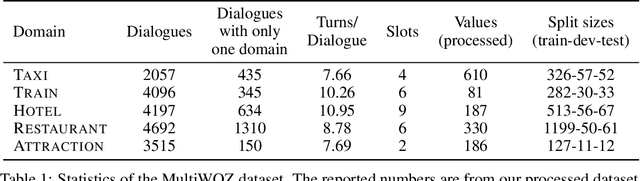
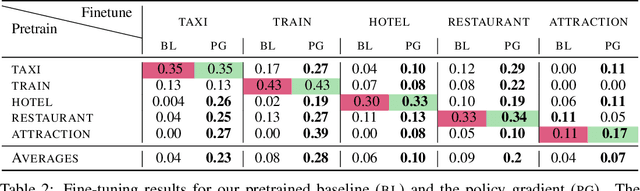
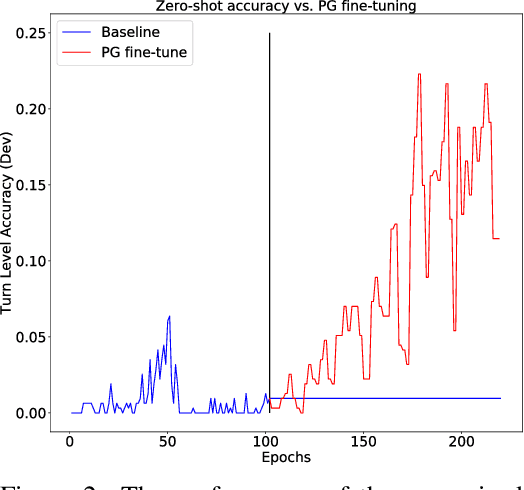
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent throughout the conversation. State-of-the-art DST models are typically trained in a supervised manner from manual annotations at the turn level. However, these annotations are costly to obtain, which makes it difficult to create accurate dialogue systems for new domains. To address these limitations, we propose a method, based on reinforcement learning, for transferring DST models to new domains without turn-level supervision. Across several domains, our experiments show that this method quickly adapts off-the-shelf models to new domains and performs on par with models trained with turn-level supervision. We also show our method can improve models trained using turn-level supervision by subsequent fine-tuning optimization toward dialog-level rewards.