 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKForge: LLM-Driven Cross-Platform Kernel Generation for AI Accelerators
Jun 01, 2026Production inference increasingly targets a heterogeneous mix of accelerators. Agentic pipelines interleave reasoning, tool calls, and multi-agent coordination, each with distinct compute and memory profiles. For optimal efficiency, each stage should run on the accelerator best suited to it. This creates a systems challenge: each pipeline now requires high-performance kernels across a growing set of hardware backends and programming models. Writing these kernels by hand is time-consuming, demands deep low-level expertise, and does not scale as kernel complexity grows. Recently, Large Language Models (LLMs) have been leveraged for automatic kernel generation, but challenges in low-level code generation and cross-backend generalization persist. We present KForge, a cross-platform framework built around an iterative refinement loop driven by two collaborating LLM-based agents: a generation agent that produces and progressively refines kernels using compilation and correctness feedback, and a performance-analysis agent that interprets profiling data, from programmatic APIs to GUI-based tools, and emits recommendations that steer the next round of synthesis. The loop alternates between functional passes, which drive a candidate to correctness, and optimization passes, which close the performance gap to hand-tuned baselines. We evaluate KForge on two backends with very different baseline reference availability. On NVIDIA B200, KForge achieves a 2.12$\%$ improvement in end-to-end throughput compared to TensorRT-LLM on the gpt-oss-20b inference speed benchmark. On Intel Arc B580, KForge generates Triton kernels achieving a 5.13$\times$ geometric mean speedup over the faster of PyTorch eager and torch.compile on 37 GEMM + tail-ops workloads from KernelBench Level 2, primarily via operator fusion and mixed-precision execution.
KForge: Program Synthesis for Diverse AI Hardware Accelerators
Nov 17, 2025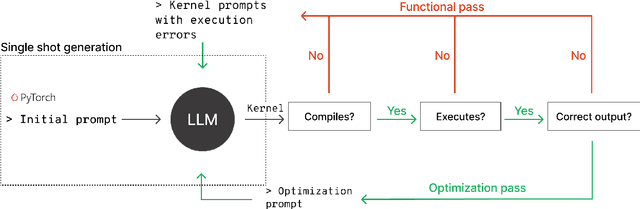

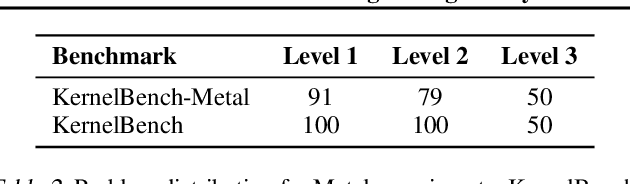
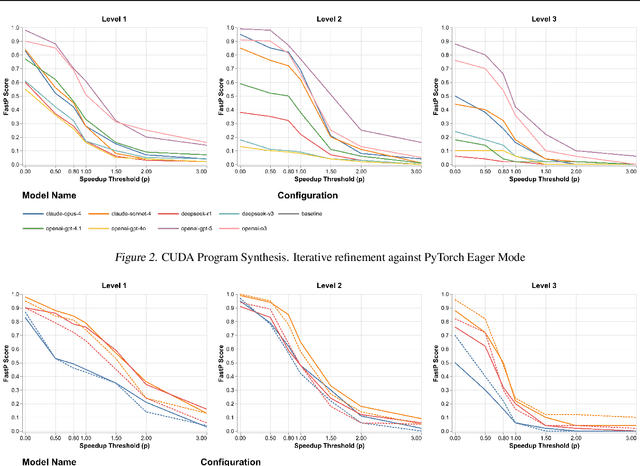
GPU kernels are critical for ML performance but difficult to optimize across diverse accelerators. We present KForge, a platform-agnostic framework built on two collaborative LLM-based agents: a generation agent that produces and iteratively refines programs through compilation and correctness feedback, and a performance analysis agent that interprets profiling data to guide optimization. This agent-based architecture requires only a single-shot example to target new platforms. We make three key contributions: (1) introducing an iterative refinement system where the generation agent and performance analysis agent collaborate through functional and optimization passes, interpreting diverse profiling data (from programmatic APIs to GUI-based tools) to generate actionable recommendations that guide program synthesis for arbitrary accelerators; (2) demonstrating that the generation agent effectively leverages cross-platform knowledge transfer, where a reference implementation from one architecture substantially improves generation quality for different hardware targets; and (3) validating the platform-agnostic nature of our approach by demonstrating effective program synthesis across fundamentally different parallel computing platforms: NVIDIA CUDA and Apple Metal.
Transcribe, Align and Segment: Creating speech datasets for low-resource languages
Jun 18, 2024In this work, we showcase a cost-effective method for generating training data for speech processing tasks. First, we transcribe unlabeled speech using a state-of-the-art Automatic Speech Recognition (ASR) model. Next, we align generated transcripts with the audio and apply segmentation on short utterances. Our focus is on ASR for low-resource languages, such as Ukrainian, using podcasts as a source of unlabeled speech. We release a new dataset UK-PODS that features modern conversational Ukrainian language. It contains over 50 hours of text audio-pairs as well as uk-pods-conformer, a 121 M parameters ASR model that is trained on MCV-10 and UK-PODS and achieves 3x reduction of Word Error Rate (WER) on podcasts comparing to publically available uk-nvidia-citrinet while maintaining comparable WER on MCV-10 test split. Both dataset UK-PODS https://huggingface.co/datasets/taras-sereda/uk-pods and ASR uk-pods-conformer https://huggingface.co/taras-sereda/uk-pods-conformer are available on the hugging-face hub.
Pheme: Efficient and Conversational Speech Generation
Jan 05, 2024In recent years, speech generation has seen remarkable progress, now achieving one-shot generation capability that is often virtually indistinguishable from real human voice. Integrating such advancements in speech generation with large language models might revolutionize a wide range of applications. However, certain applications, such as assistive conversational systems, require natural and conversational speech generation tools that also operate efficiently in real time. Current state-of-the-art models like VALL-E and SoundStorm, powered by hierarchical neural audio codecs, require large neural components and extensive training data to work well. In contrast, MQTTS aims to build more compact conversational TTS models while capitalizing on smaller-scale real-life conversational speech data. However, its autoregressive nature yields high inference latency and thus limits its real-time usage. In order to mitigate the current limitations of the state-of-the-art TTS models while capitalizing on their strengths, in this work we introduce the Pheme model series that 1) offers compact yet high-performing models, 2) allows for parallel speech generation of 3) natural conversational speech, and 4) it can be trained efficiently on smaller-scale conversational data, cutting data demands by more than 10x but still matching the quality of the autoregressive TTS models. We also show that through simple teacher-student distillation we can meet significant improvements in voice quality for single-speaker setups on top of pretrained Pheme checkpoints, relying solely on synthetic speech generated by much larger teacher models. Audio samples and pretrained models are available online.