 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Bootstrapping of Dialogue State Trackers for Task Oriented Modelling
Paper and Code
Nov 26, 2019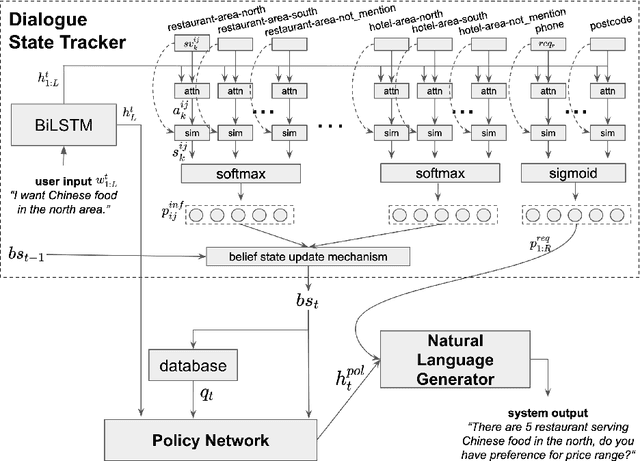

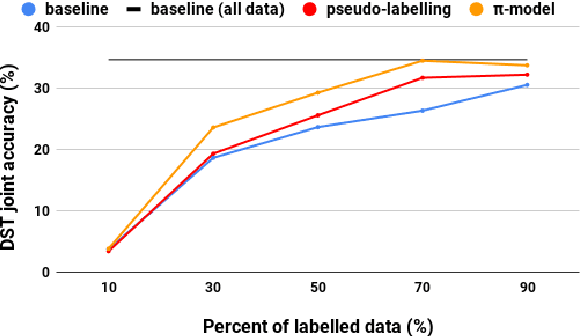
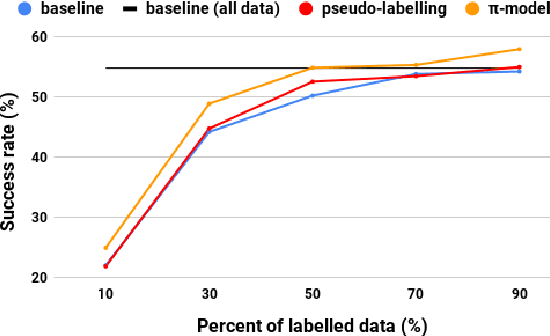
Dialogue systems benefit greatly from optimizing on detailed annotations, such as transcribed utterances, internal dialogue state representations and dialogue act labels. However, collecting these annotations is expensive and time-consuming, holding back development in the area of dialogue modelling. In this paper, we investigate semi-supervised learning methods that are able to reduce the amount of required intermediate labelling. We find that by leveraging un-annotated data instead, the amount of turn-level annotations of dialogue state can be significantly reduced when building a neural dialogue system. Our analysis on the MultiWOZ corpus, covering a range of domains and topics, finds that annotations can be reduced by up to 30\% while maintaining equivalent system performance. We also describe and evaluate the first end-to-end dialogue model created for the MultiWOZ corpus.