 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLU++: A Multi-Label, Slot-Rich, Generalisable Dataset for Natural Language Understanding in Task-Oriented Dialogue
May 05, 2022



We present NLU++, a novel dataset for natural language understanding (NLU) in task-oriented dialogue (ToD) systems, with the aim to provide a much more challenging evaluation environment for dialogue NLU models, up to date with the current application and industry requirements. NLU++ is divided into two domains (BANKING and HOTELS) and brings several crucial improvements over current commonly used NLU datasets. 1) NLU++ provides fine-grained domain ontologies with a large set of challenging multi-intent sentences, introducing and validating the idea of intent modules that can be combined into complex intents that convey complex user goals, combined with finer-grained and thus more challenging slot sets. 2) The ontology is divided into domain-specific and generic (i.e., domain-universal) intent modules that overlap across domains, promoting cross-domain reusability of annotated examples. 3) The dataset design has been inspired by the problems observed in industrial ToD systems, and 4) it has been collected, filtered and carefully annotated by dialogue NLU experts, yielding high-quality annotated data. Finally, we benchmark a series of current state-of-the-art NLU models on NLU++; the results demonstrate the challenging nature of the dataset, especially in low-data regimes, the validity of `intent modularisation', and call for further research on ToD NLU.
EVI: Multilingual Spoken Dialogue Tasks and Dataset for Knowledge-Based Enrolment, Verification, and Identification
Apr 28, 2022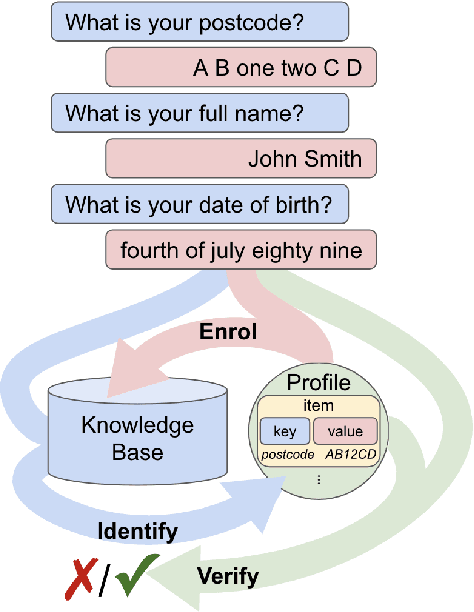
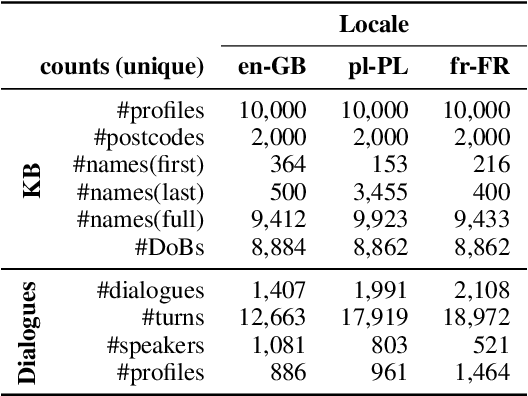
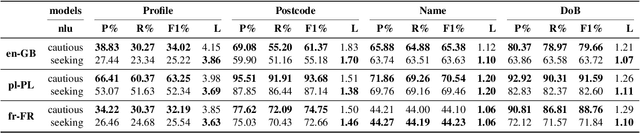
Knowledge-based authentication is crucial for task-oriented spoken dialogue systems that offer personalised and privacy-focused services. Such systems should be able to enrol (E), verify (V), and identify (I) new and recurring users based on their personal information, e.g. postcode, name, and date of birth. In this work, we formalise the three authentication tasks and their evaluation protocols, and we present EVI, a challenging spoken multilingual dataset with 5,506 dialogues in English, Polish, and French. Our proposed models set the first competitive benchmarks, explore the challenges of multilingual natural language processing of spoken dialogue, and set directions for future research.
ConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021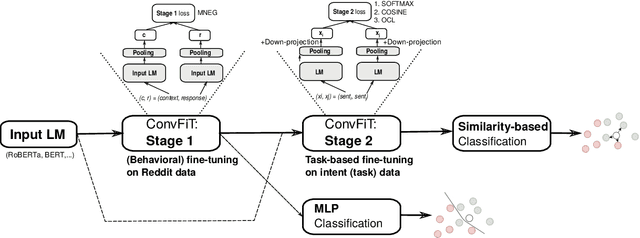

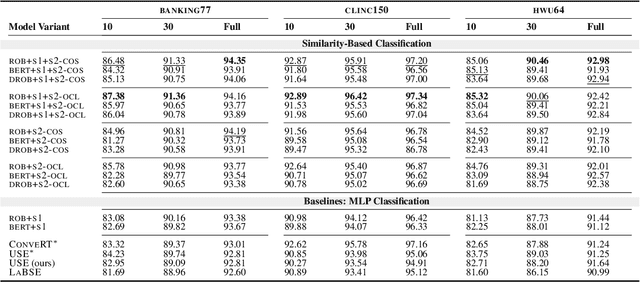
Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Efficient Intent Detection with Dual Sentence Encoders
Mar 10, 2020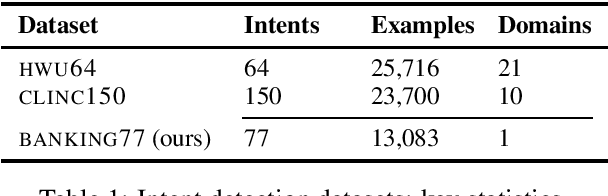

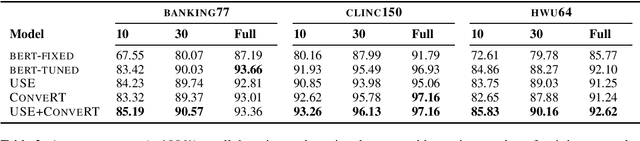

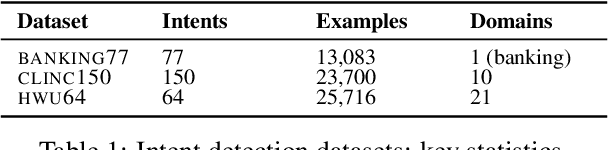
Building conversational systems in new domains and with added functionality requires resource-efficient models that work under low-data regimes (i.e., in few-shot setups). Motivated by these requirements, we introduce intent detection methods backed by pretrained dual sentence encoders such as USE and ConveRT. We demonstrate the usefulness and wide applicability of the proposed intent detectors, showing that: 1) they outperform intent detectors based on fine-tuning the full BERT-Large model or using BERT as a fixed black-box encoder on three diverse intent detection data sets; 2) the gains are especially pronounced in few-shot setups (i.e., with only 10 or 30 annotated examples per intent); 3) our intent detectors can be trained in a matter of minutes on a single CPU; and 4) they are stable across different hyperparameter settings. In hope of facilitating and democratizing research focused on intention detection, we release our code, as well as a new challenging single-domain intent detection dataset comprising 13,083 annotated examples over 77 intents.
ConveRT: Efficient and Accurate Conversational Representations from Transformers
Nov 09, 2019


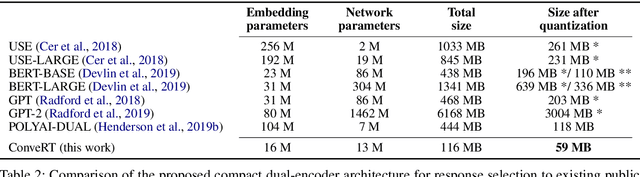
General-purpose pretrained sentence encoders such as BERT are not ideal for real-world conversational AI applications; they are computationally heavy, slow, and expensive to train. We propose ConveRT (Conversational Representations from Transformers), a faster, more compact dual sentence encoder specifically optimized for dialog tasks. We pretrain using a retrieval-based response selection task, effectively leveraging quantization and subword-level parameterization in the dual encoder to build a lightweight memory- and energy-efficient model. In our evaluation, we show that ConveRT achieves state-of-the-art performance across widely established response selection tasks. We also demonstrate that the use of extended dialog history as context yields further performance gains. Finally, we show that pretrained representations from the proposed encoder can be transferred to the intent classification task, yielding strong results across three diverse data sets. ConveRT trains substantially faster than standard sentence encoders or previous state-of-the-art dual encoders. With its reduced size and superior performance, we believe this model promises wider portability and scalability for Conversational AI applications.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019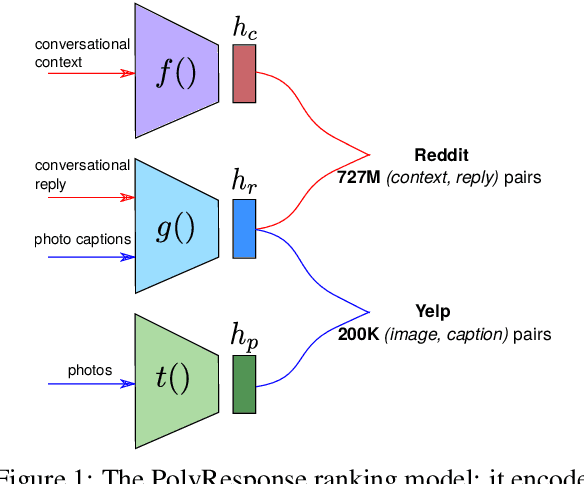
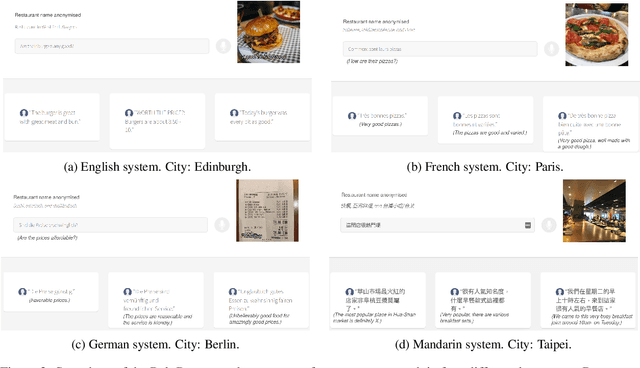
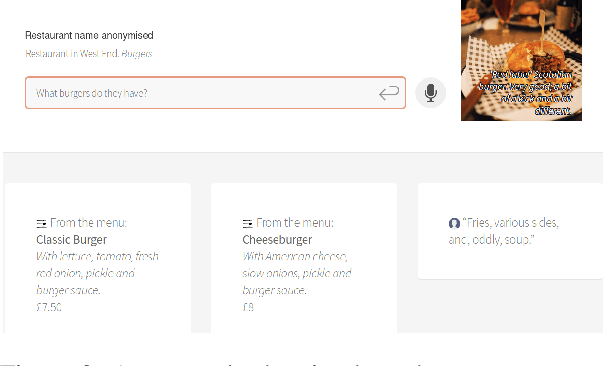
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

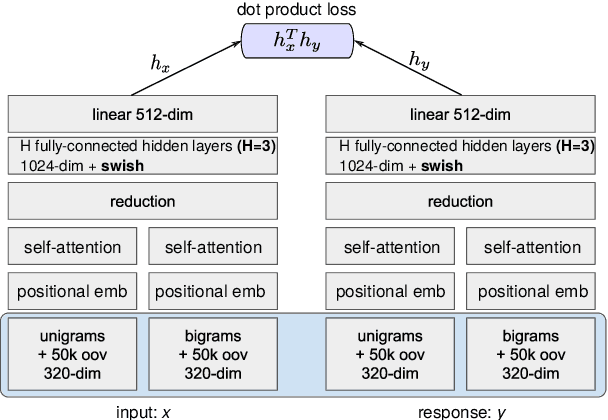

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

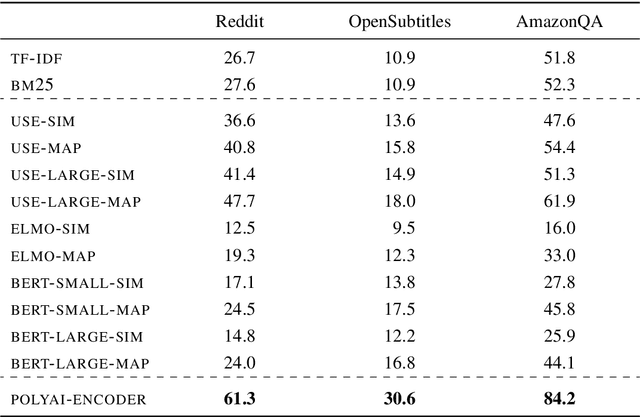

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
Addressing Objects and Their Relations: The Conversational Entity Dialogue Model
Jan 05, 2019



Statistical spoken dialogue systems usually rely on a single- or multi-domain dialogue model that is restricted in its capabilities of modelling complex dialogue structures, e.g., relations. In this work, we propose a novel dialogue model that is centred around entities and is able to model relations as well as multiple entities of the same type. We demonstrate in a prototype implementation benefits of relation modelling on the dialogue level and show that a trained policy using these relations outperforms the multi-domain baseline. Furthermore, we show that by modelling the relations on the dialogue level, the system is capable of processing relations present in the user input and even learns to address them in the system response.
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
Sep 29, 2018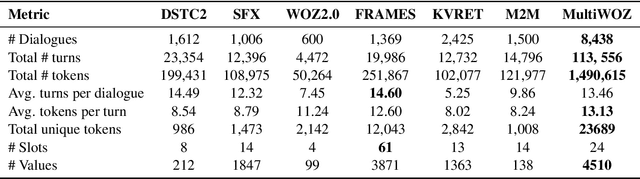


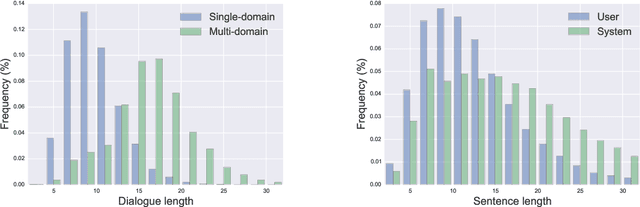
Even though machine learning has become the major scene in dialogue research community, the real breakthrough has been blocked by the scale of data available. To address this fundamental obstacle, we introduce the Multi-Domain Wizard-of-Oz dataset (MultiWOZ), a fully-labeled collection of human-human written conversations spanning over multiple domains and topics. At a size of $10$k dialogues, it is at least one order of magnitude larger than all previous annotated task-oriented corpora. The contribution of this work apart from the open-sourced dataset labelled with dialogue belief states and dialogue actions is two-fold: firstly, a detailed description of the data collection procedure along with a summary of data structure and analysis is provided. The proposed data-collection pipeline is entirely based on crowd-sourcing without the need of hiring professional annotators; secondly, a set of benchmark results of belief tracking, dialogue act and response generation is reported, which shows the usability of the data and sets a baseline for future studies.