 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Flow Transformer
May 20, 2025Transformers, the standard implementation for large language models (LLMs), typically consist of tens to hundreds of discrete layers. While more layers can lead to better performance, this approach has been challenged as far from efficient, especially given the superiority of continuous layers demonstrated by diffusion and flow-based models for image generation. We propose the Latent Flow Transformer (LFT), which replaces a block of layers with a single learned transport operator trained via flow matching, offering significant compression while maintaining compatibility with the original architecture. Additionally, we address the limitations of existing flow-based methods in \textit{preserving coupling} by introducing the Flow Walking (FW) algorithm. On the Pythia-410M model, LFT trained with flow matching compresses 6 of 24 layers and outperforms directly skipping 2 layers (KL Divergence of LM logits at 0.407 vs. 0.529), demonstrating the feasibility of this design. When trained with FW, LFT further distills 12 layers into one while reducing the KL to 0.736 surpassing that from skipping 3 layers (0.932), significantly narrowing the gap between autoregressive and flow-based generation paradigms.
Extending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
Tree-Structured Semantic Encoder with Knowledge Sharing for Domain Adaptation in Natural Language Generation
Oct 02, 2019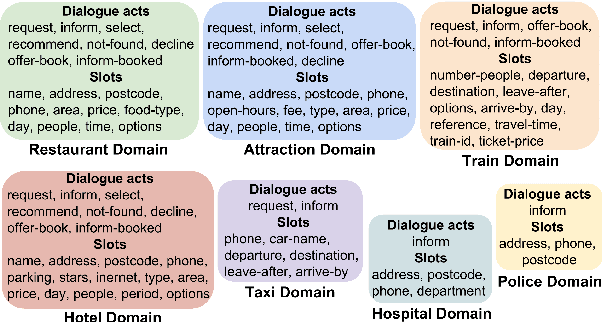
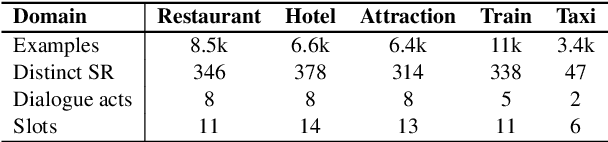
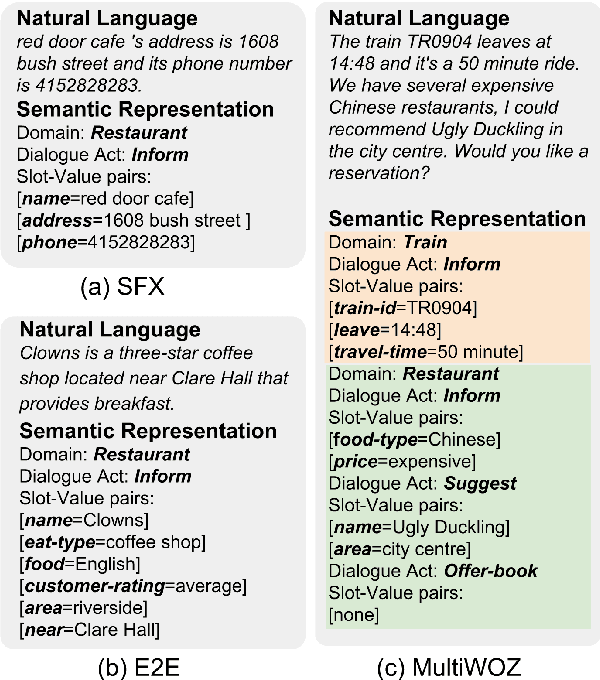
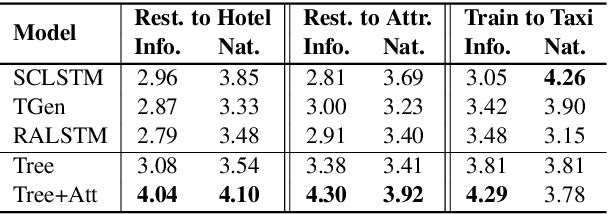
Domain adaptation in natural language generation (NLG) remains challenging because of the high complexity of input semantics across domains and limited data of a target domain. This is particularly the case for dialogue systems, where we want to be able to seamlessly include new domains into the conversation. Therefore, it is crucial for generation models to share knowledge across domains for the effective adaptation from one domain to another. In this study, we exploit a tree-structured semantic encoder to capture the internal structure of complex semantic representations required for multi-domain dialogues in order to facilitate knowledge sharing across domains. In addition, a layer-wise attention mechanism between the tree encoder and the decoder is adopted to further improve the model's capability. The automatic evaluation results show that our model outperforms previous methods in terms of the BLEU score and the slot error rate, in particular when the adaptation data is limited. In subjective evaluation, human judges tend to prefer the sentences generated by our model, rating them more highly on informativeness and naturalness than other systems.
Addressing Objects and Their Relations: The Conversational Entity Dialogue Model
Jan 05, 2019



Statistical spoken dialogue systems usually rely on a single- or multi-domain dialogue model that is restricted in its capabilities of modelling complex dialogue structures, e.g., relations. In this work, we propose a novel dialogue model that is centred around entities and is able to model relations as well as multiple entities of the same type. We demonstrate in a prototype implementation benefits of relation modelling on the dialogue level and show that a trained policy using these relations outperforms the multi-domain baseline. Furthermore, we show that by modelling the relations on the dialogue level, the system is capable of processing relations present in the user input and even learns to address them in the system response.
Variational Cross-domain Natural Language Generation for Spoken Dialogue Systems
Dec 20, 2018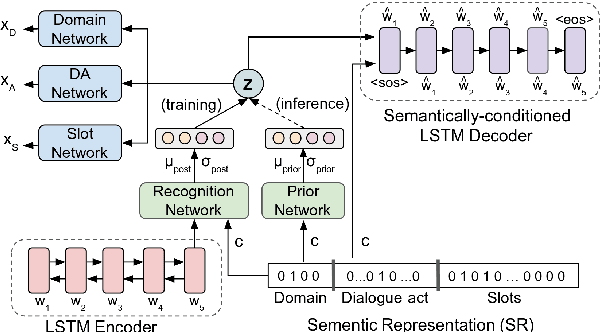

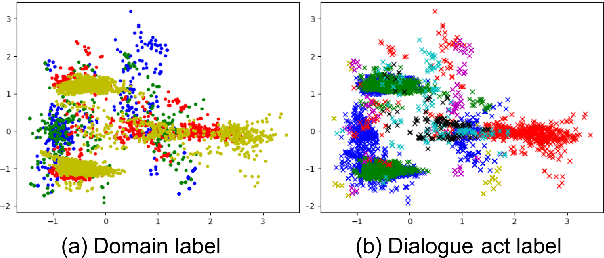
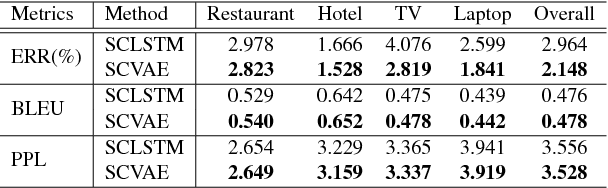
Cross-domain natural language generation (NLG) is still a difficult task within spoken dialogue modelling. Given a semantic representation provided by the dialogue manager, the language generator should generate sentences that convey desired information. Traditional template-based generators can produce sentences with all necessary information, but these sentences are not sufficiently diverse. With RNN-based models, the diversity of the generated sentences can be high, however, in the process some information is lost. In this work, we improve an RNN-based generator by considering latent information at the sentence level during generation using the conditional variational autoencoder architecture. We demonstrate that our model outperforms the original RNN-based generator, while yielding highly diverse sentences. In addition, our model performs better when the training data is limited.
Interactive Spoken Content Retrieval by Deep Reinforcement Learning
Sep 16, 2016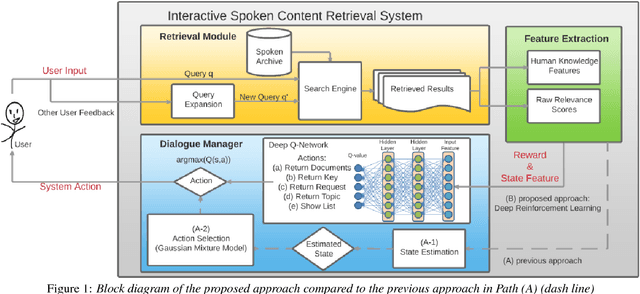
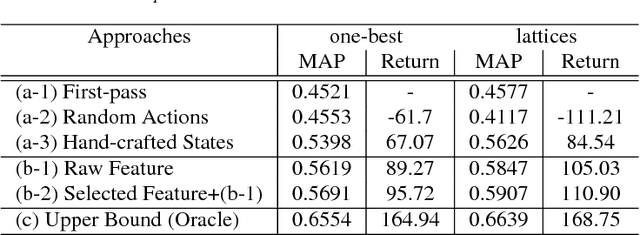
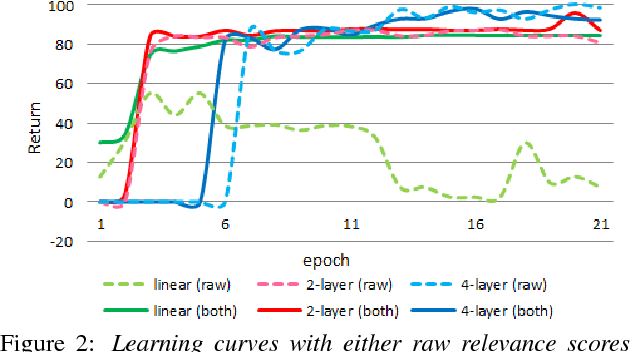
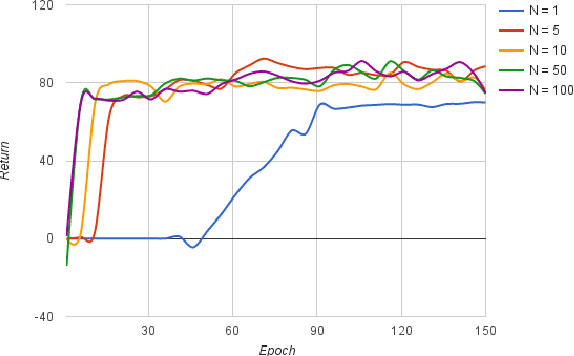
User-machine interaction is important for spoken content retrieval. For text content retrieval, the user can easily scan through and select on a list of retrieved item. This is impossible for spoken content retrieval, because the retrieved items are difficult to show on screen. Besides, due to the high degree of uncertainty for speech recognition, the retrieval results can be very noisy. One way to counter such difficulties is through user-machine interaction. The machine can take different actions to interact with the user to obtain better retrieval results before showing to the user. The suitable actions depend on the retrieval status, for example requesting for extra information from the user, returning a list of topics for user to select, etc. In our previous work, some hand-crafted states estimated from the present retrieval results are used to determine the proper actions. In this paper, we propose to use Deep-Q-Learning techniques instead to determine the machine actions for interactive spoken content retrieval. Deep-Q-Learning bypasses the need for estimation of the hand-crafted states, and directly determine the best action base on the present retrieval status even without any human knowledge. It is shown to achieve significantly better performance compared with the previous hand-crafted states.
A Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) for Unsupervised Discovery of Linguistic Units and Generation of High Quality Features
Jun 07, 2015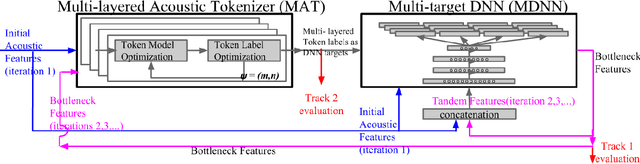
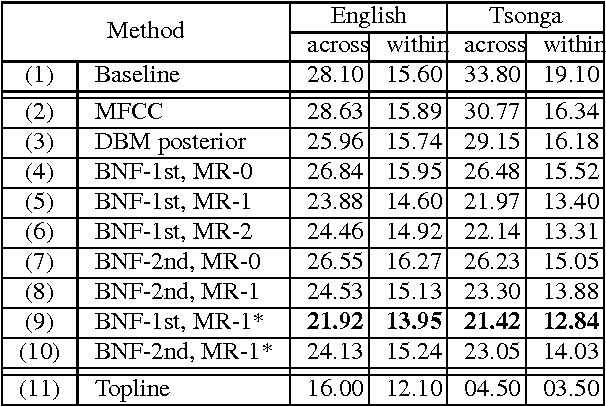
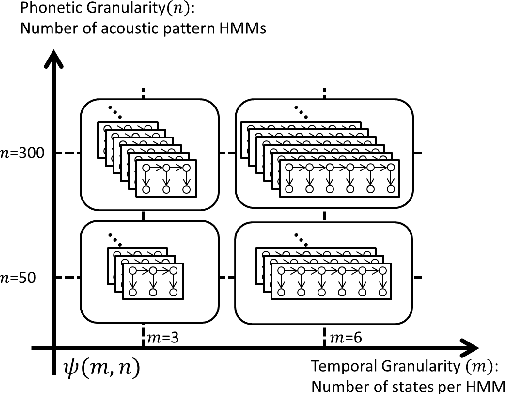
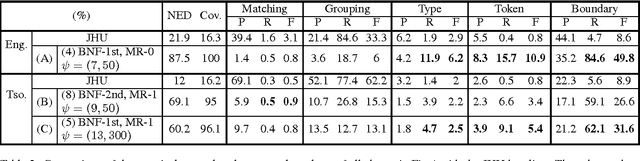
This paper summarizes the work done by the authors for the Zero Resource Speech Challenge organized in the technical program of Interspeech 2015. The goal of the challenge is to discover linguistic units directly from unlabeled speech data. The Multi-layered Acoustic Tokenizer (MAT) proposed in this work automatically discovers multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters that describe the model configuration. These sets of acoustic tokens carry different characteristics of the given corpus and the language behind thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target DNN (MDNN) trained on low-level acoustic features. Bottleneck features extracted from the MDNN are used as feedback for the MAT and the MDNN itself. We call this iterative system the Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) which generates high quality features for track 1 of the challenge and acoustic tokens for track 2 of the challenge.