 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
Towards a Universal NLG for Dialogue Systems and Simulators with Future Bridging
May 24, 2021
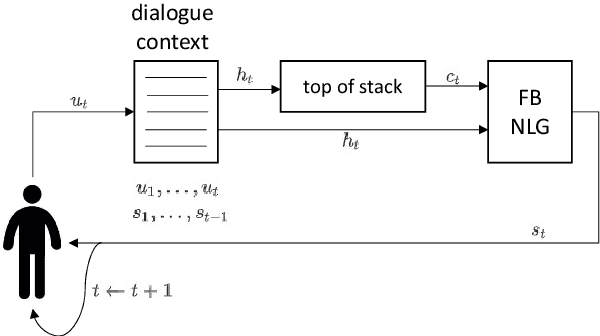


In a dialogue system pipeline, a natural language generation (NLG) unit converts the dialogue direction and content to a corresponding natural language realization. A recent trend for dialogue systems is to first pre-train on large datasets and then fine-tune in a supervised manner using datasets annotated with application-specific features. Though novel behaviours can be learned from custom annotation, the required effort severely bounds the quantity of the training set, and the application-specific nature limits the reuse. In light of the recent success of data-driven approaches, we propose the novel future bridging NLG (FBNLG) concept for dialogue systems and simulators. The critical step is for an FBNLG to accept a future user or system utterance to bridge the present context towards. Future bridging enables self supervised training over annotation-free datasets, decoupled the training of NLG from the rest of the system. An FBNLG, pre-trained with massive datasets, is expected to apply in classical or new dialogue scenarios with minimal adaptation effort. We evaluate a prototype FBNLG to show that future bridging can be a viable approach to a universal few-shot NLG for task-oriented and chit-chat dialogues.
Learning Robust Manipulation Skills with Guided Policy Search via Generative Motor Reflexes
Feb 19, 2019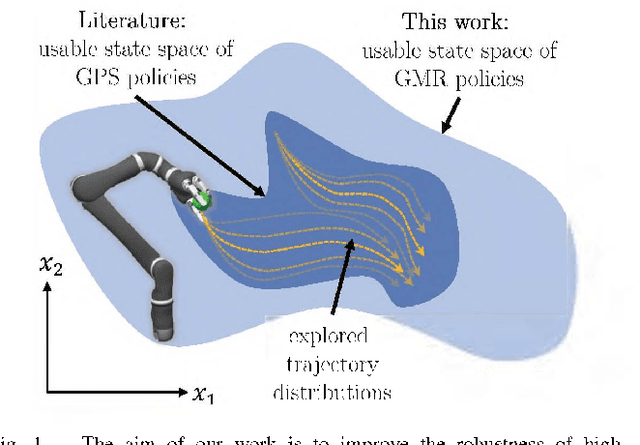
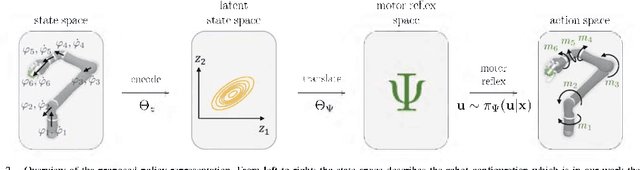


Guided Policy Search enables robots to learn control policies for complex manipulation tasks efficiently. Therein, the control policies are represented as high-dimensional neural networks which derive robot actions based on states. However, due to the small number of real-world trajectory samples in Guided Policy Search, the resulting neural networks are only robust in the neighbourhood of the trajectory distribution explored by real-world interactions. In this paper, we present a new policy representation called Generative Motor Reflexes, which is able to generate robust actions over a broader state space compared to previous methods. In contrast to prior state-action policies, Generative Motor Reflexes map states to parameters for a state-dependent motor reflex, which is then used to derive actions. Robustness is achieved by generating similar motor reflexes for many states. We evaluate the presented method in simulated and real-world manipulation tasks, including contact-rich peg-in-hole tasks. Using these evaluation tasks, we show that policies represented as Generative Motor Reflexes lead to robust manipulation skills also outside the explored trajectory distribution with less training needs compared to previous methods.