 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
InverseMV: Composing Piano Scores with a Convolutional Video-Music Transformer
Dec 31, 2021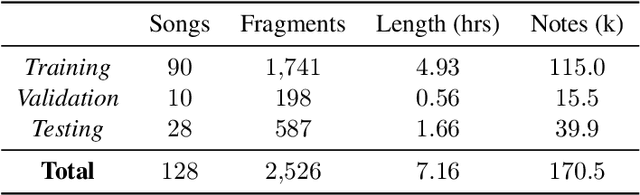
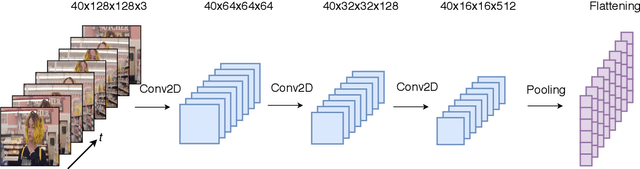
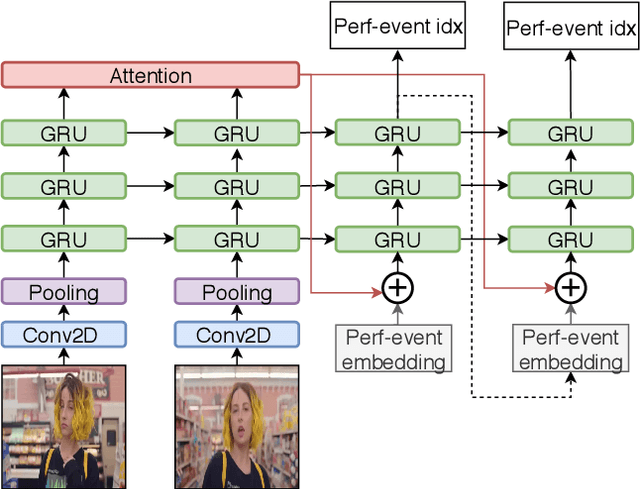

Many social media users prefer consuming content in the form of videos rather than text. However, in order for content creators to produce videos with a high click-through rate, much editing is needed to match the footage to the music. This posts additional challenges for more amateur video makers. Therefore, we propose a novel attention-based model VMT (Video-Music Transformer) that automatically generates piano scores from video frames. Using music generated from models also prevent potential copyright infringements that often come with using existing music. To the best of our knowledge, there is no work besides the proposed VMT that aims to compose music for video. Additionally, there lacks a dataset with aligned video and symbolic music. We release a new dataset composed of over 7 hours of piano scores with fine alignment between pop music videos and MIDI files. We conduct experiments with human evaluation on VMT, SeqSeq model (our baseline), and the original piano version soundtrack. VMT achieves consistent improvements over the baseline on music smoothness and video relevance. In particular, with the relevance scores and our case study, our model has shown the capability of multimodality on frame-level actors' movement for music generation. Our VMT model, along with the new dataset, presents a promising research direction toward composing the matching soundtrack for videos. We have released our code at https://github.com/linchintung/VMT