 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreeze-7B Technical Report
Mar 05, 2024Breeze-7B is an open-source language model based on Mistral-7B, designed to address the need for improved language comprehension and chatbot-oriented capabilities in Traditional Chinese. This technical report provides an overview of the additional pretraining, finetuning, and evaluation stages for the Breeze-7B model. The Breeze-7B family of base and chat models exhibits good performance on language comprehension and chatbot-oriented tasks, reaching the top in several benchmarks among models comparable in its complexity class.
Advancing the Evaluation of Traditional Chinese Language Models: Towards a Comprehensive Benchmark Suite
Oct 02, 2023
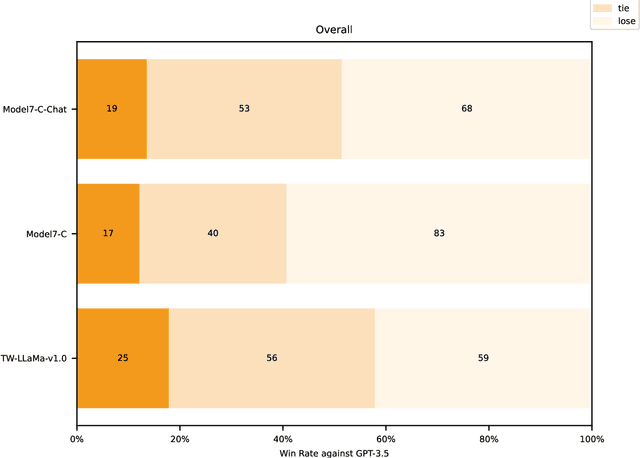
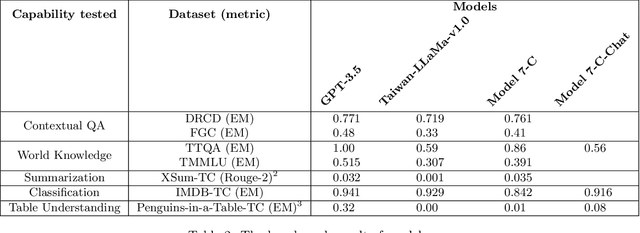
The evaluation of large language models is an essential task in the field of language understanding and generation. As language models continue to advance, the need for effective benchmarks to assess their performance has become imperative. In the context of Traditional Chinese, there is a scarcity of comprehensive and diverse benchmarks to evaluate the capabilities of language models, despite the existence of certain benchmarks such as DRCD, TTQA, CMDQA, and FGC dataset. To address this gap, we propose a novel set of benchmarks that leverage existing English datasets and are tailored to evaluate language models in Traditional Chinese. These benchmarks encompass a wide range of tasks, including contextual question-answering, summarization, classification, and table understanding. The proposed benchmarks offer a comprehensive evaluation framework, enabling the assessment of language models' capabilities across different tasks. In this paper, we evaluate the performance of GPT-3.5, Taiwan-LLaMa-v1.0, and Model 7-C, our proprietary model, on these benchmarks. The evaluation results highlight that our model, Model 7-C, achieves performance comparable to GPT-3.5 with respect to a part of the evaluated capabilities. In an effort to advance the evaluation of language models in Traditional Chinese and stimulate further research in this field, we have open-sourced our benchmark and opened the model for trial.
Extending the Pre-Training of BLOOM for Improved Support of Traditional Chinese: Models, Methods and Results
Mar 08, 2023In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
Learning Coded Apertures for Time-Division Multiplexing Light Field Display
Aug 02, 2021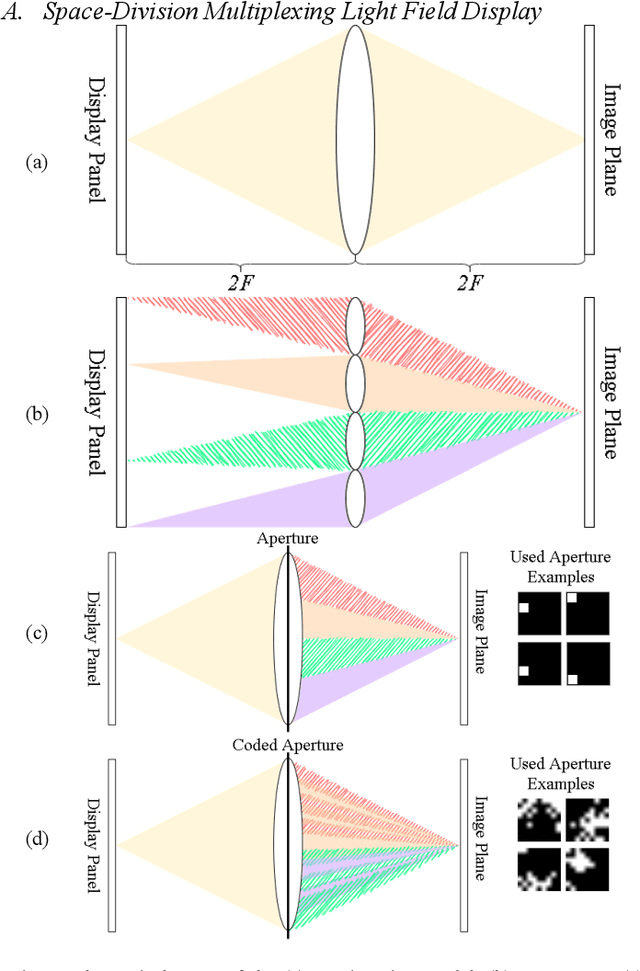



Conventional stereoscopic displays suffer from vergence-accommodation conflict and cause visual fatigue. Integral-imaging-based displays resolve the problem by directly projecting the sub-aperture views of a light field into the eyes using a microlens array or a similar structure. However, such displays have an inherent trade-off between angular and spatial resolutions. In this paper, we propose a novel coded time-division multiplexing technique that projects encoded sub-aperture views to the eyes of a viewer with correct cues for vergence-accommodation reflex. Given sparse light field sub-aperture views, our pipeline can provide a perception of high-resolution refocused images with minimal aliasing by jointly optimizing the sub-aperture views for display and the coded aperture pattern. This is achieved via deep learning in an end-to-end fashion by simulating light transport and image formation with Fourier optics. To our knowledge, this work is among the first that optimize the light field display pipeline with deep learning. We verify our idea with objective image quality metrics (PSNR and SSIM) and perform an extensive study on various customizable design variables in our display pipeline. Experimental results show that light fields displayed using the proposed technique indeed have higher quality than that of baseline display designs.
Light Field Synthesis by Training Deep Network in the Refocused Image Domain
Nov 07, 2019

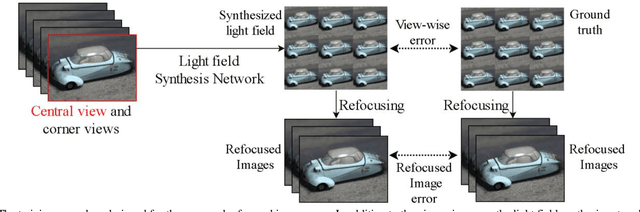

Light field imaging, which captures spatio-angular information of incident light on image sensor, enables many interesting applications like image refocusing and augmented reality. However, due to the limited sensor resolution, a trade-off exists between the spatial and angular resolution. To increase the angular resolution, view synthesis techniques have been adopted to generate new views from existing views. However, traditional learning-based view synthesis mainly considers the image quality of each view of the light field and neglects the quality of the refocused images. In this paper, we propose a new loss function called refocused image error (RIE) to address the issue. The main idea is that the image quality of the synthesized light field should be optimized in the refocused image domain because it is where the light field is perceived. We analyze the behavior of RIL in the spectral domain and test the performance of our approach against previous approaches on both real and software-rendered light field datasets using objective assessment metrics such as MSE, MAE, PSNR, SSIM, and GMSD. Experimental results show that the light field generated by our method results in better refocused images than previous methods.
Multichannel Speech Enhancement by Raw Waveform-mapping using Fully Convolutional Networks
Sep 26, 2019
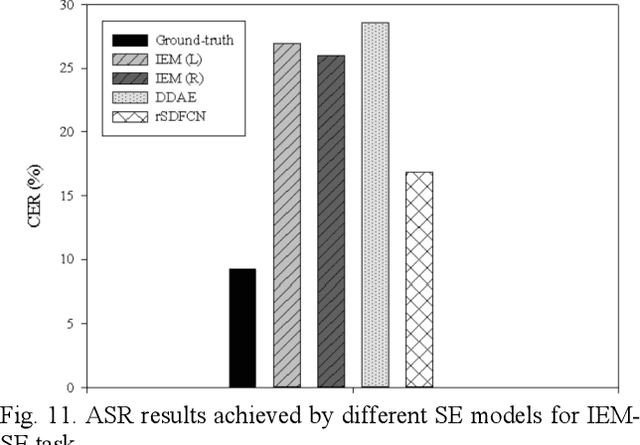


In recent years, waveform-mapping-based speech enhancement (SE) methods have garnered significant attention. These methods generally use a deep learning model to directly process and reconstruct speech waveforms. Because both the input and output are in waveform format, the waveform-mapping-based SE methods can overcome the distortion caused by imperfect phase estimation, which may be encountered in spectral-mapping-based SE systems. So far, most waveform-mapping-based SE methods have focused on single-channel tasks. In this paper, we propose a novel fully convolutional network (FCN) with Sinc and dilated convolutional layers (termed SDFCN) for multichannel SE that operates in the time domain. We also propose an extended version of SDFCN, called the residual SDFCN (termed rSDFCN). The proposed methods are evaluated on two multichannel SE tasks, namely the dual-channel inner-ear microphones SE task and the distributed microphones SE task. The experimental results confirm the outstanding denoising capability of the proposed SE systems on both tasks and the benefits of using the residual architecture on the overall SE performance.