 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel Speech Enhancement by Raw Waveform-mapping using Fully Convolutional Networks
Paper and Code

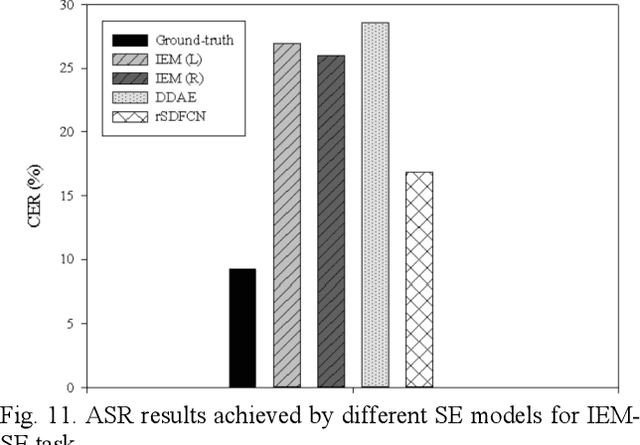


In recent years, waveform-mapping-based speech enhancement (SE) methods have garnered significant attention. These methods generally use a deep learning model to directly process and reconstruct speech waveforms. Because both the input and output are in waveform format, the waveform-mapping-based SE methods can overcome the distortion caused by imperfect phase estimation, which may be encountered in spectral-mapping-based SE systems. So far, most waveform-mapping-based SE methods have focused on single-channel tasks. In this paper, we propose a novel fully convolutional network (FCN) with Sinc and dilated convolutional layers (termed SDFCN) for multichannel SE that operates in the time domain. We also propose an extended version of SDFCN, called the residual SDFCN (termed rSDFCN). The proposed methods are evaluated on two multichannel SE tasks, namely the dual-channel inner-ear microphones SE task and the distributed microphones SE task. The experimental results confirm the outstanding denoising capability of the proposed SE systems on both tasks and the benefits of using the residual architecture on the overall SE performance.