 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Baselines for Measuring and Predicting the Music Piece Memorability
May 21, 2024Nowadays, humans are constantly exposed to music, whether through voluntary streaming services or incidental encounters during commercial breaks. Despite the abundance of music, certain pieces remain more memorable and often gain greater popularity. Inspired by this phenomenon, we focus on measuring and predicting music memorability. To achieve this, we collect a new music piece dataset with reliable memorability labels using a novel interactive experimental procedure. We then train baselines to predict and analyze music memorability, leveraging both interpretable features and audio mel-spectrograms as inputs. To the best of our knowledge, we are the first to explore music memorability using data-driven deep learning-based methods. Through a series of experiments and ablation studies, we demonstrate that while there is room for improvement, predicting music memorability with limited data is possible. Certain intrinsic elements, such as higher valence, arousal, and faster tempo, contribute to memorable music. As prediction techniques continue to evolve, real-life applications like music recommendation systems and music style transfer will undoubtedly benefit from this new area of research.
Multichannel Speech Enhancement by Raw Waveform-mapping using Fully Convolutional Networks
Sep 26, 2019
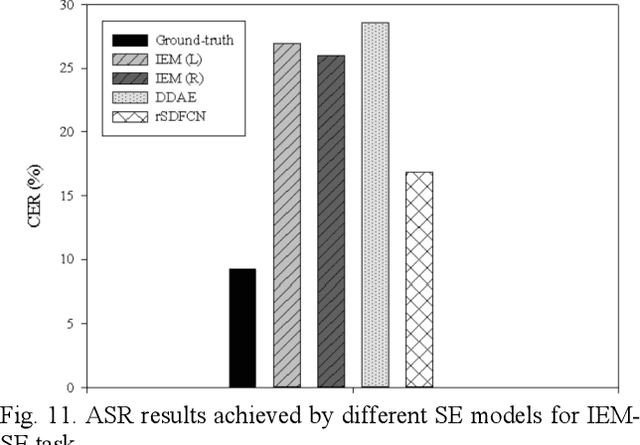


In recent years, waveform-mapping-based speech enhancement (SE) methods have garnered significant attention. These methods generally use a deep learning model to directly process and reconstruct speech waveforms. Because both the input and output are in waveform format, the waveform-mapping-based SE methods can overcome the distortion caused by imperfect phase estimation, which may be encountered in spectral-mapping-based SE systems. So far, most waveform-mapping-based SE methods have focused on single-channel tasks. In this paper, we propose a novel fully convolutional network (FCN) with Sinc and dilated convolutional layers (termed SDFCN) for multichannel SE that operates in the time domain. We also propose an extended version of SDFCN, called the residual SDFCN (termed rSDFCN). The proposed methods are evaluated on two multichannel SE tasks, namely the dual-channel inner-ear microphones SE task and the distributed microphones SE task. The experimental results confirm the outstanding denoising capability of the proposed SE systems on both tasks and the benefits of using the residual architecture on the overall SE performance.