 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity
May 16, 2025Recent advances in large language models (LLMs) have demonstrated the power of reasoning through self-generated chains of thought. Multiple reasoning agents can collaborate to raise joint reasoning quality above individual outcomes. However, such agents typically interact in a turn-based manner, trading increased latency for improved quality. In this paper, we propose Group Think--a single LLM that acts as multiple concurrent reasoning agents, or thinkers. With shared visibility into each other's partial generation progress, Group Think introduces a new concurrent-reasoning paradigm in which multiple reasoning trajectories adapt dynamically to one another at the token level. For example, a reasoning thread may shift its generation mid-sentence upon detecting that another thread is better positioned to continue. This fine-grained, token-level collaboration enables Group Think to reduce redundant reasoning and improve quality while achieving significantly lower latency. Moreover, its concurrent nature allows for efficient utilization of idle computational resources, making it especially suitable for edge inference, where very small batch size often underutilizes local~GPUs. We give a simple and generalizable modification that enables any existing LLM to perform Group Think on a local GPU. We also present an evaluation strategy to benchmark reasoning latency and empirically demonstrate latency improvements using open-source LLMs that were not explicitly trained for Group Think. We hope this work paves the way for future LLMs to exhibit more sophisticated and more efficient collaborative behavior for higher quality generation.
TASTE: Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling
Apr 09, 2025Large Language Models (LLMs) excel in text-based natural language processing tasks but remain constrained by their reliance on textual inputs and outputs. To enable more natural human-LLM interaction, recent progress have focused on deriving a spoken language model (SLM) that can not only listen but also generate speech. To achieve this, a promising direction is to conduct speech-text joint modeling. However, recent SLM still lag behind text LLM due to the modality mismatch. One significant mismatch can be the sequence lengths between speech and text tokens. To address this, we introduce Text-Aligned Speech Tokenization and Embedding (TASTE), a method that directly addresses the modality gap by aligning speech token with the corresponding text transcription during the tokenization stage. We propose a method that can achieve this through the special aggregation mechanism and with speech reconstruction as the training objective. We conduct extensive experiments and show that TASTE can preserve essential paralinguistic information while dramatically reducing the token sequence length. Furthermore, by leveraging TASTE, we can adapt text-based LLMs into effective SLMs with parameter-efficient fine-tuning techniques such as Low-Rank Adaptation (LoRA). Experimental results on benchmark tasks, including SALMON and StoryCloze, demonstrate that TASTE-based SLMs perform similarly to previous full-finetuning methods. To our knowledge, TASTE is the first end-to-end approach that utilizes a reconstruction objective to automatically learn a text-aligned speech tokenization and embedding suitable for spoken language modeling. Our demo, code, and models are publicly available at https://github.com/mtkresearch/TASTE-SpokenLM.
BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation -- Challenges and Insights
Jan 29, 2025We present BreezyVoice, a Text-to-Speech (TTS) system specifically adapted for Taiwanese Mandarin, highlighting phonetic control abilities to address the unique challenges of polyphone disambiguation in the language. Building upon CosyVoice, we incorporate a $S^{3}$ tokenizer, a large language model (LLM), an optimal-transport conditional flow matching model (OT-CFM), and a grapheme to phoneme prediction model, to generate realistic speech that closely mimics human utterances. Our evaluation demonstrates BreezyVoice's superior performance in both general and code-switching contexts, highlighting its robustness and effectiveness in generating high-fidelity speech. Additionally, we address the challenges of generalizability in modeling long-tail speakers and polyphone disambiguation. Our approach significantly enhances performance and offers valuable insights into the workings of neural codec TTS systems.
The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities
Jan 25, 2025Llama-Breeze2 (hereinafter referred to as Breeze2) is a suite of advanced multi-modal language models, available in 3B and 8B parameter configurations, specifically designed to enhance Traditional Chinese language representation. Building upon the Llama 3.2 model family, we continue the pre-training of Breeze2 on an extensive corpus to enhance the linguistic and cultural heritage of Traditional Chinese. In addition to language modeling capabilities, we significantly augment the models with function calling and vision understanding capabilities. At the time of this publication, as far as we are aware, absent reasoning-inducing prompts, Breeze2 are the strongest performing models in Traditional Chinese function calling and image understanding in its size class. The effectiveness of Breeze2 is benchmarked across various tasks, including Taiwan general knowledge, instruction-following, long context, function calling, and vision understanding. We are publicly releasing all Breeze2 models under the Llama 3.2 Community License. We also showcase the capabilities of the model running on mobile platform with a mobile application which we also open source.
Enhancing Function-Calling Capabilities in LLMs: Strategies for Prompt Formats, Data Integration, and Multilingual Translation
Dec 02, 2024Large language models (LLMs) have significantly advanced autonomous agents, particularly in zero-shot tool usage, also known as function calling. This research delves into enhancing the function-calling capabilities of LLMs by exploring different approaches, including prompt formats for integrating function descriptions, blending function-calling and instruction-following data, introducing a novel Decision Token for conditional prompts, leveraging chain-of-thought reasoning, and overcoming multilingual challenges with a translation pipeline. Our key findings and contributions are as follows: (1) Instruction-following data improves both function-calling accuracy and relevance detection. (2) The use of the newly proposed Decision Token, combined with synthetic non-function-call data, enhances relevance detection. (3) A tailored translation pipeline effectively overcomes multilingual limitations, demonstrating significant improvements in Traditional Chinese. These insights highlight the potential for improved function-calling capabilities and multilingual applications in LLMs.
Let's Fuse Step by Step: A Generative Fusion Decoding Algorithm with LLMs for Multi-modal Text Recognition
May 23, 2024We introduce ``Generative Fusion Decoding'' (GFD), a novel shallow fusion framework, utilized to integrate Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). We derive the formulas necessary to enable GFD to operate across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. The framework is plug-and-play, compatible with various auto-regressive models, and does not require re-training for feature alignment, thus overcoming limitations of previous fusion techniques. We highlight three main advantages of GFD: First, by simplifying the complexity of aligning different model sample spaces, GFD allows LLMs to correct errors in tandem with the recognition model, reducing computation latencies. Second, the in-context learning ability of LLMs is fully capitalized by GFD, increasing robustness in long-form speech recognition and instruction aware speech recognition. Third, GFD enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. Our evaluation demonstrates that GFD significantly improves performance in ASR and OCR tasks, with ASR reaching state-of-the-art in the NTUML2021 benchmark. GFD provides a significant step forward in model integration, offering a unified solution that could be widely applicable to leveraging existing pre-trained models through step by step fusion.
Breeze-7B Technical Report
Mar 05, 2024Breeze-7B is an open-source language model based on Mistral-7B, designed to address the need for improved language comprehension and chatbot-oriented capabilities in Traditional Chinese. This technical report provides an overview of the additional pretraining, finetuning, and evaluation stages for the Breeze-7B model. The Breeze-7B family of base and chat models exhibits good performance on language comprehension and chatbot-oriented tasks, reaching the top in several benchmarks among models comparable in its complexity class.
Advancing the Evaluation of Traditional Chinese Language Models: Towards a Comprehensive Benchmark Suite
Oct 02, 2023
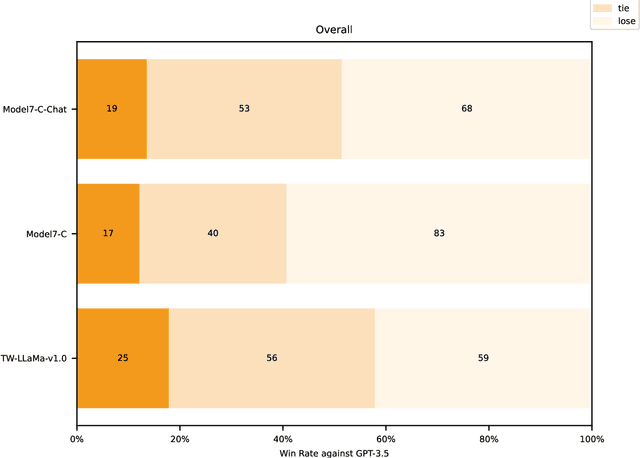
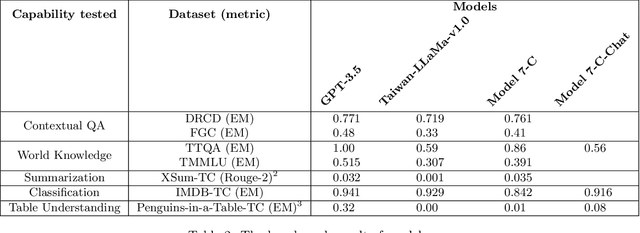
The evaluation of large language models is an essential task in the field of language understanding and generation. As language models continue to advance, the need for effective benchmarks to assess their performance has become imperative. In the context of Traditional Chinese, there is a scarcity of comprehensive and diverse benchmarks to evaluate the capabilities of language models, despite the existence of certain benchmarks such as DRCD, TTQA, CMDQA, and FGC dataset. To address this gap, we propose a novel set of benchmarks that leverage existing English datasets and are tailored to evaluate language models in Traditional Chinese. These benchmarks encompass a wide range of tasks, including contextual question-answering, summarization, classification, and table understanding. The proposed benchmarks offer a comprehensive evaluation framework, enabling the assessment of language models' capabilities across different tasks. In this paper, we evaluate the performance of GPT-3.5, Taiwan-LLaMa-v1.0, and Model 7-C, our proprietary model, on these benchmarks. The evaluation results highlight that our model, Model 7-C, achieves performance comparable to GPT-3.5 with respect to a part of the evaluated capabilities. In an effort to advance the evaluation of language models in Traditional Chinese and stimulate further research in this field, we have open-sourced our benchmark and opened the model for trial.
Zero-shot Domain-sensitive Speech Recognition with Prompt-conditioning Fine-tuning
Jul 18, 2023



In this work, we propose a method to create domain-sensitive speech recognition models that utilize textual domain information by conditioning its generation on a given text prompt. This is accomplished by fine-tuning a pre-trained, end-to-end model (Whisper) to learn from demonstrations with prompt examples. We show that this ability can be generalized to different domains and even various prompt contexts, with our model gaining a Word Error Rate (WER) reduction of up to 33% on unseen datasets from various domains, such as medical conversation, air traffic control communication, and financial meetings. Considering the limited availability of audio-transcript pair data, we further extend our method to text-only fine-tuning to achieve domain sensitivity as well as domain adaptation. We demonstrate that our text-only fine-tuned model can also attend to various prompt contexts, with the model reaching the most WER reduction of 29% on the medical conversation dataset.
g2pW: A Conditional Weighted Softmax BERT for Polyphone Disambiguation in Mandarin
Mar 24, 2022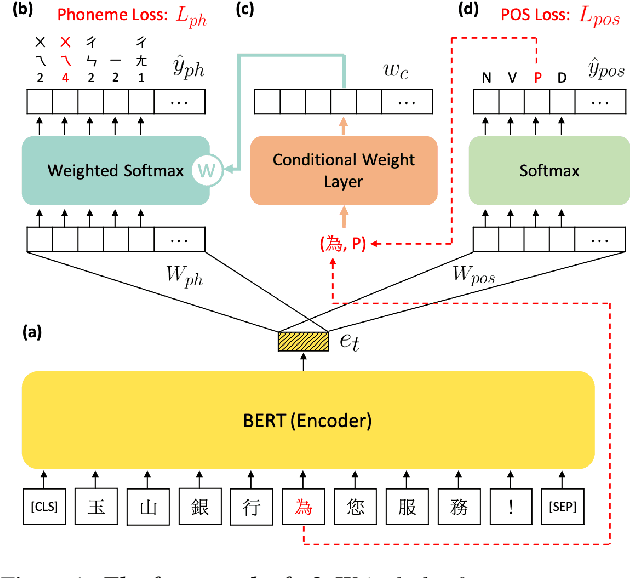
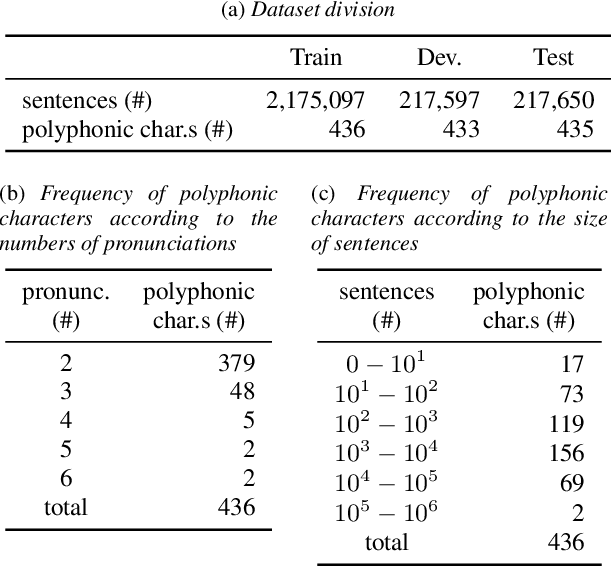
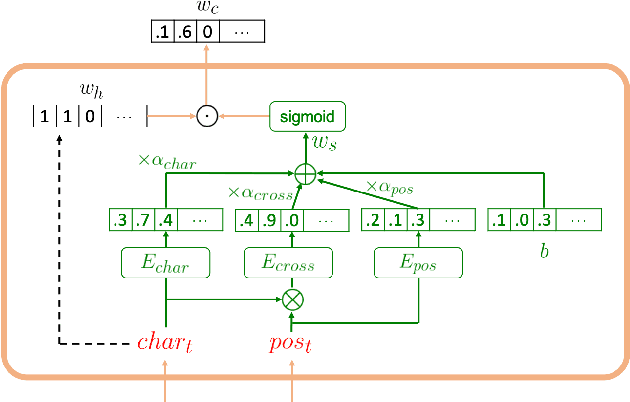
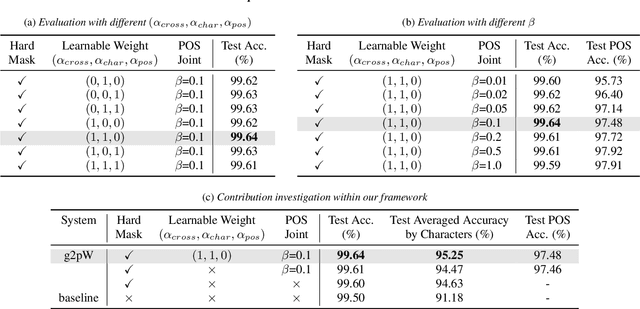
Polyphone disambiguation is the most crucial task in Mandarin grapheme-to-phoneme (g2p) conversion. Previous studies have approached this problem using pre-trained language models, restricted output, and extra information from Part-Of-Speech (POS) tagging. Inspired by these strategies, we propose a novel approach, called g2pW, which adapts learnable softmax-weights to condition the outputs of BERT with the polyphonic character of interest and its POS tagging. Rather than using the hard mask as in previous works, our experiments show that learning a soft-weighting function for the candidate phonemes benefits performance. In addition, our proposed g2pW does not require extra pre-trained POS tagging models while using POS tags as auxiliary features since we train the POS tagging model simultaneously with the unified encoder. Experimental results show that our g2pW outperforms existing methods on the public CPP dataset. All codes, model weights, and a user-friendly package are publicly available.