 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeg2pW: A Conditional Weighted Softmax BERT for Polyphone Disambiguation in Mandarin
Mar 24, 2022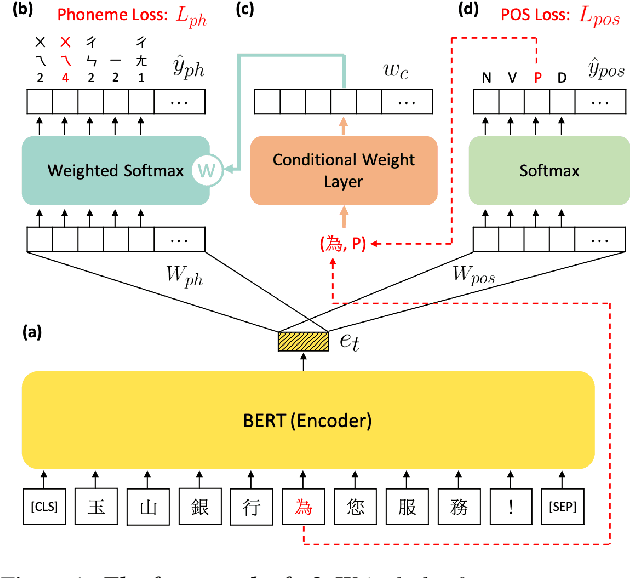
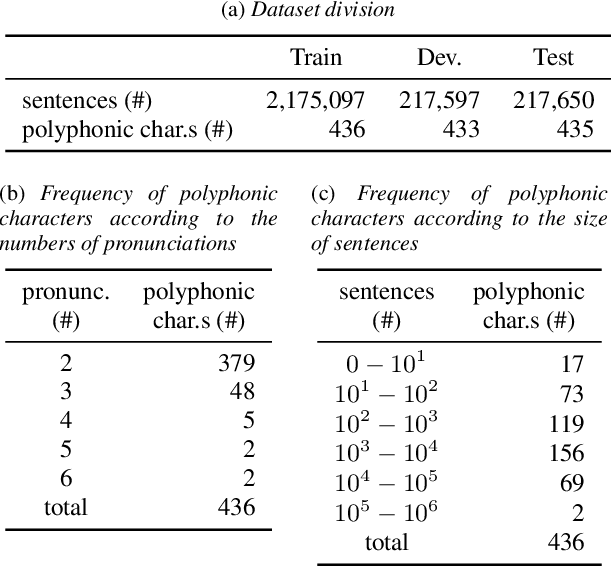
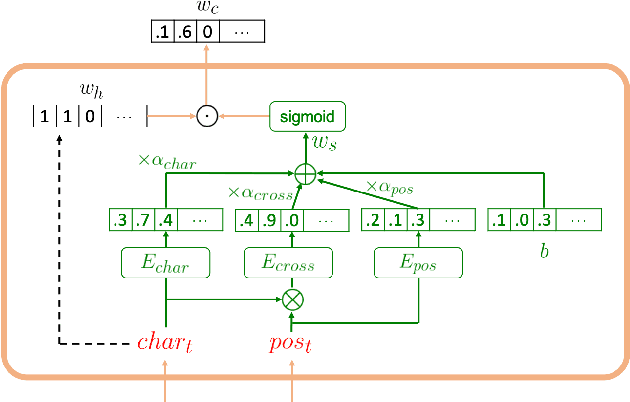
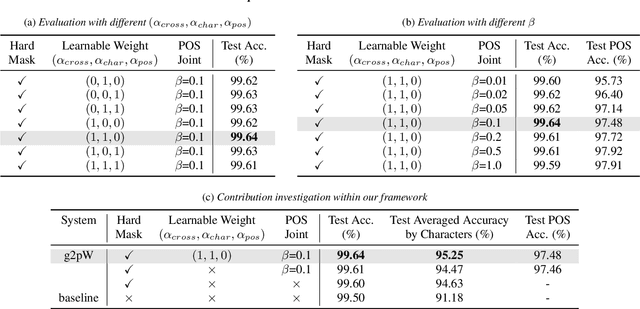
Polyphone disambiguation is the most crucial task in Mandarin grapheme-to-phoneme (g2p) conversion. Previous studies have approached this problem using pre-trained language models, restricted output, and extra information from Part-Of-Speech (POS) tagging. Inspired by these strategies, we propose a novel approach, called g2pW, which adapts learnable softmax-weights to condition the outputs of BERT with the polyphonic character of interest and its POS tagging. Rather than using the hard mask as in previous works, our experiments show that learning a soft-weighting function for the candidate phonemes benefits performance. In addition, our proposed g2pW does not require extra pre-trained POS tagging models while using POS tags as auxiliary features since we train the POS tagging model simultaneously with the unified encoder. Experimental results show that our g2pW outperforms existing methods on the public CPP dataset. All codes, model weights, and a user-friendly package are publicly available.
SMILE: Sequence-to-Sequence Domain Adaption with Minimizing Latent Entropy for Text Image Recognition
Feb 24, 2022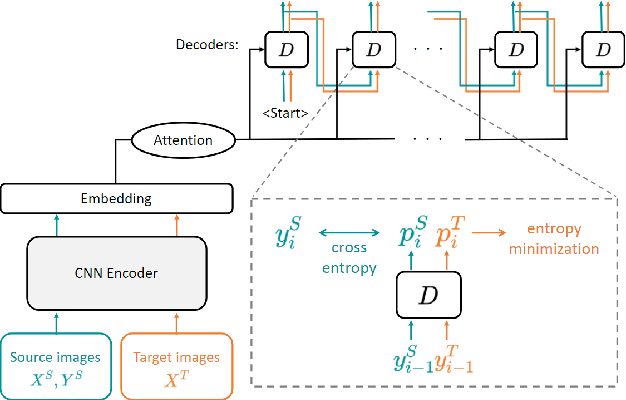
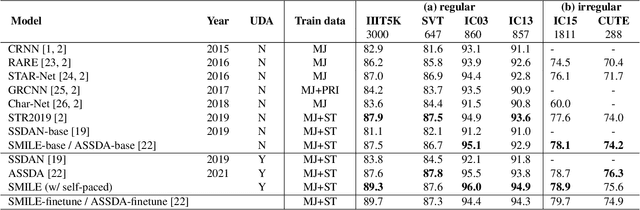
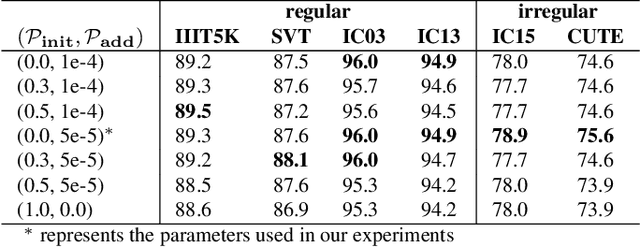
Training recognition models with synthetic images have achieved remarkable results in text recognition. However, recognizing text from real-world images still faces challenges due to the domain shift between synthetic and real-world text images. One of the strategies to eliminate the domain difference without manual annotation is unsupervised domain adaptation (UDA). Due to the characteristic of sequential labeling tasks, most popular UDA methods cannot be directly applied to text recognition. To tackle this problem, we proposed a UDA method with minimizing latent entropy on sequence-to-sequence attention-based models with classbalanced self-paced learning. Our experiments show that our proposed framework achieves better recognition results than the existing methods on most UDA text recognition benchmarks. All codes are publicly available.
Traditional Chinese Synthetic Datasets Verified with Labeled Data for Scene Text Recognition
Nov 26, 2021

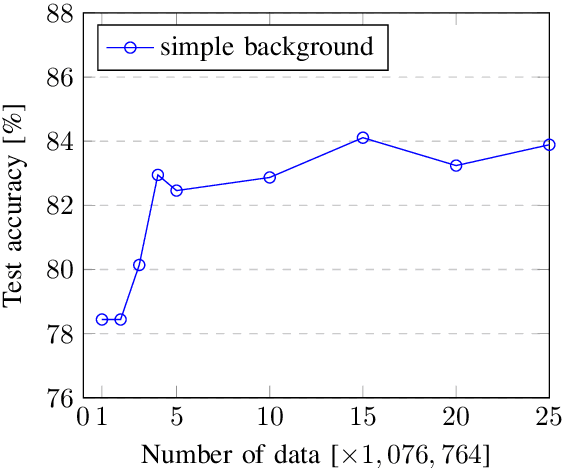
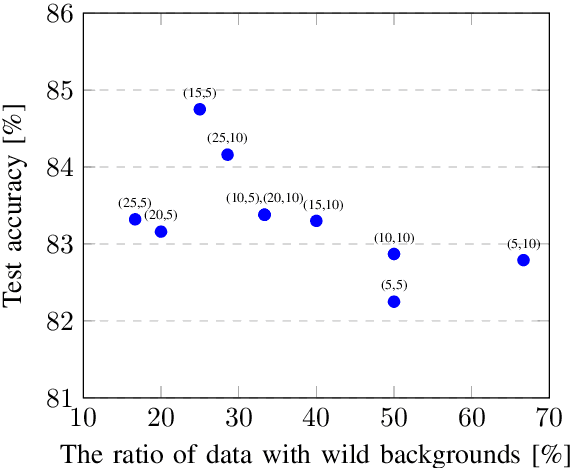
Scene text recognition (STR) has been widely studied in academia and industry. Training a text recognition model often requires a large amount of labeled data, but data labeling can be difficult, expensive, or time-consuming, especially for Traditional Chinese text recognition. To the best of our knowledge, public datasets for Traditional Chinese text recognition are lacking. This paper presents a framework for a Traditional Chinese synthetic data engine which aims to improve text recognition model performance. We generated over 20 million synthetic data and collected over 7,000 manually labeled data TC-STR 7k-word as the benchmark. Experimental results show that a text recognition model can achieve much better accuracy either by training from scratch with our generated synthetic data or by further fine-tuning with TC-STR 7k-word.