 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASTE-Streaming: Towards Streamable Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling
Mar 12, 2026Text-speech joint spoken language modeling (SLM) aims at natural and intelligent speech-based interactions, but developing such a system may suffer from modality mismatch: speech unit sequences are much longer than text tokens. Prior work reduces this gap with text-aligned tokenization and embedding (TASTE), producing speech tokens that align in lengths with their textual counterparts. However, the dependence on an external ASR system and the use of a non-causal decoder limits streaming use. To address this limitation, we propose TASTE-S, a streamable extension of TASTE suitable for real-time usage. TASTE-S integrates a CTC-based ASR module into the encoder for instant dual-modality encoding. We also redesign the unit decoder to enable on-the-fly decoding. With joint training, we show that TASTE-S matches TASTE's performance while significantly reducing latency. Further investigations reveal that TASTE-S remains robust to transcriptions and enables long-form encoding and decoding.
On the Fallacy of Global Token Perplexity in Spoken Language Model Evaluation
Jan 09, 2026Generative spoken language models pretrained on large-scale raw audio can continue a speech prompt with appropriate content while preserving attributes like speaker and emotion, serving as foundation models for spoken dialogue. In prior literature, these models are often evaluated using ``global token perplexity'', which directly applies the text perplexity formulation to speech tokens. However, this practice overlooks fundamental differences between speech and text modalities, possibly leading to an underestimation of the speech characteristics. In this work, we propose a variety of likelihood- and generative-based evaluation methods that serve in place of naive global token perplexity. We demonstrate that the proposed evaluations more faithfully reflect perceived generation quality, as evidenced by stronger correlations with human-rated mean opinion scores (MOS). When assessed under the new metrics, the relative performance landscape of spoken language models is reshaped, revealing a significantly reduced gap between the best-performing model and the human topline. Together, these results suggest that appropriate evaluation is critical for accurately assessing progress in spoken language modeling.
TASTE: Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling
Apr 09, 2025



Large Language Models (LLMs) excel in text-based natural language processing tasks but remain constrained by their reliance on textual inputs and outputs. To enable more natural human-LLM interaction, recent progress have focused on deriving a spoken language model (SLM) that can not only listen but also generate speech. To achieve this, a promising direction is to conduct speech-text joint modeling. However, recent SLM still lag behind text LLM due to the modality mismatch. One significant mismatch can be the sequence lengths between speech and text tokens. To address this, we introduce Text-Aligned Speech Tokenization and Embedding (TASTE), a method that directly addresses the modality gap by aligning speech token with the corresponding text transcription during the tokenization stage. We propose a method that can achieve this through the special aggregation mechanism and with speech reconstruction as the training objective. We conduct extensive experiments and show that TASTE can preserve essential paralinguistic information while dramatically reducing the token sequence length. Furthermore, by leveraging TASTE, we can adapt text-based LLMs into effective SLMs with parameter-efficient fine-tuning techniques such as Low-Rank Adaptation (LoRA). Experimental results on benchmark tasks, including SALMON and StoryCloze, demonstrate that TASTE-based SLMs perform similarly to previous full-finetuning methods. To our knowledge, TASTE is the first end-to-end approach that utilizes a reconstruction objective to automatically learn a text-aligned speech tokenization and embedding suitable for spoken language modeling. Our demo, code, and models are publicly available at https://github.com/mtkresearch/TASTE-SpokenLM.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
Jul 15, 2024



Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).
REBORN: Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR
Feb 06, 2024Unsupervised automatic speech recognition (ASR) aims to learn the mapping between the speech signal and its corresponding textual transcription without the supervision of paired speech-text data. A word/phoneme in the speech signal is represented by a segment of speech signal with variable length and unknown boundary, and this segmental structure makes learning the mapping between speech and text challenging, especially without paired data. In this paper, we propose REBORN, Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR. REBORN alternates between (1) training a segmentation model that predicts the boundaries of the segmental structures in speech signals and (2) training the phoneme prediction model, whose input is a segmental structure segmented by the segmentation model, to predict a phoneme transcription. Since supervised data for training the segmentation model is not available, we use reinforcement learning to train the segmentation model to favor segmentations that yield phoneme sequence predictions with a lower perplexity. We conduct extensive experiments and find that under the same setting, REBORN outperforms all prior unsupervised ASR models on LibriSpeech, TIMIT, and five non-English languages in Multilingual LibriSpeech. We comprehensively analyze why the boundaries learned by REBORN improve the unsupervised ASR performance.
Improving Cascaded Unsupervised Speech Translation with Denoising Back-translation
May 12, 2023



Most of the speech translation models heavily rely on parallel data, which is hard to collect especially for low-resource languages. To tackle this issue, we propose to build a cascaded speech translation system without leveraging any kind of paired data. We use fully unpaired data to train our unsupervised systems and evaluate our results on CoVoST 2 and CVSS. The results show that our work is comparable with some other early supervised methods in some language pairs. While cascaded systems always suffer from severe error propagation problems, we proposed denoising back-translation (DBT), a novel approach to building robust unsupervised neural machine translation (UNMT). DBT successfully increases the BLEU score by 0.7--0.9 in all three translation directions. Moreover, we simplified the pipeline of our cascaded system to reduce inference latency and conducted a comprehensive analysis of every part of our work. We also demonstrate our unsupervised speech translation results on the established website.
Introducing Semantics into Speech Encoders
Nov 15, 2022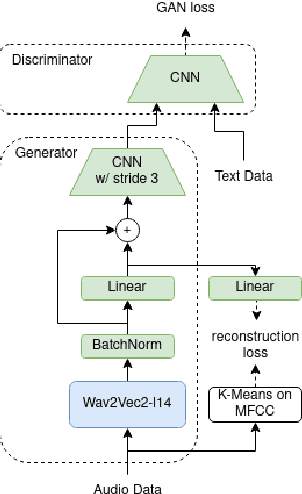
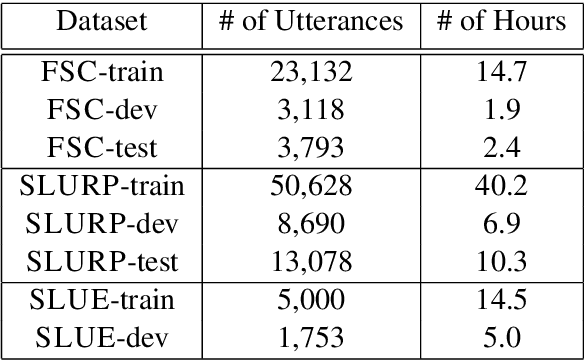
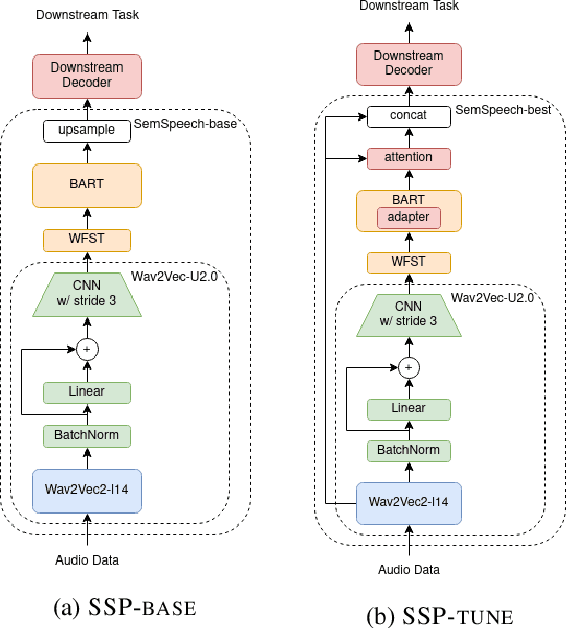
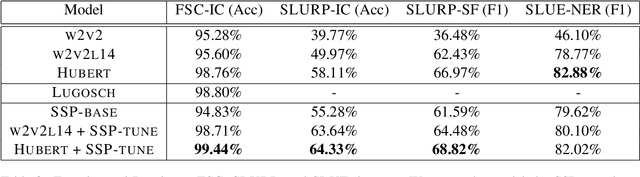
Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
Improving generalizability of distilled self-supervised speech processing models under distorted settings
Oct 20, 2022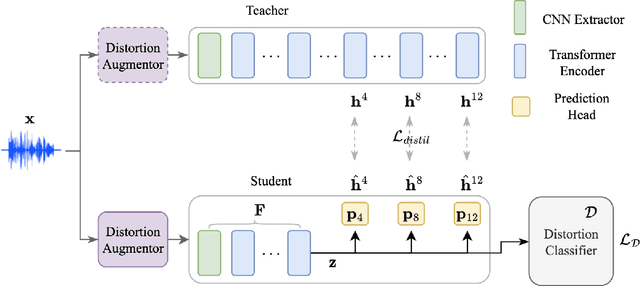
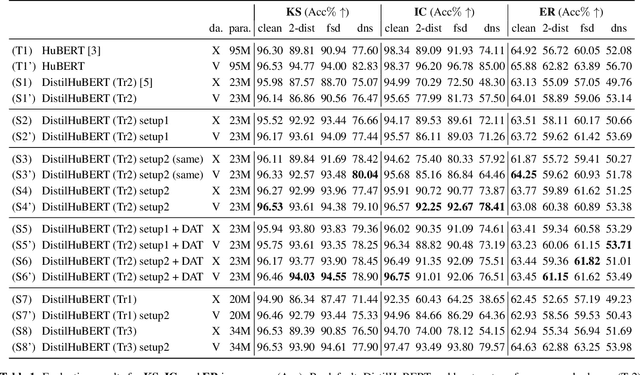
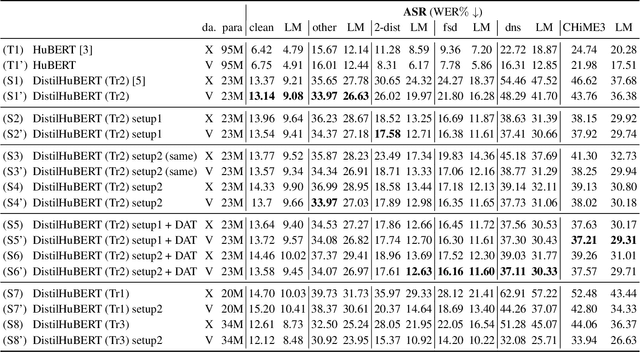
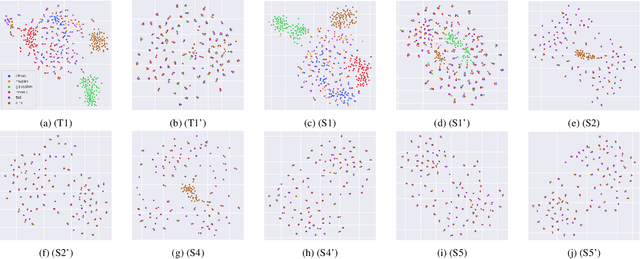
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.
Mandarin-English Code-switching Speech Recognition with Self-supervised Speech Representation Models
Oct 07, 2021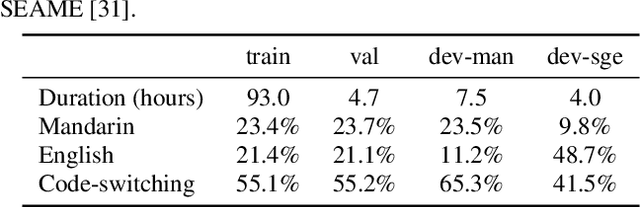
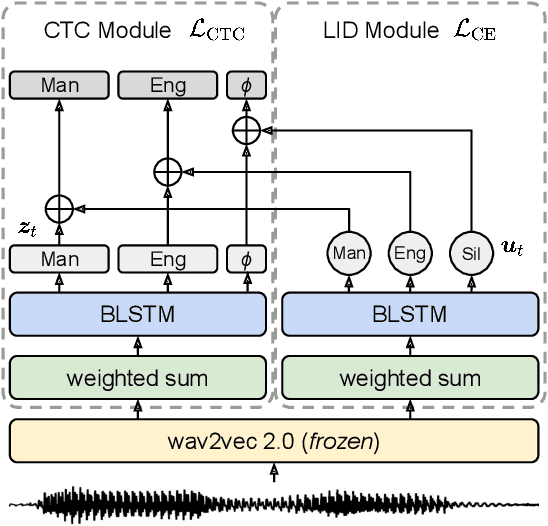
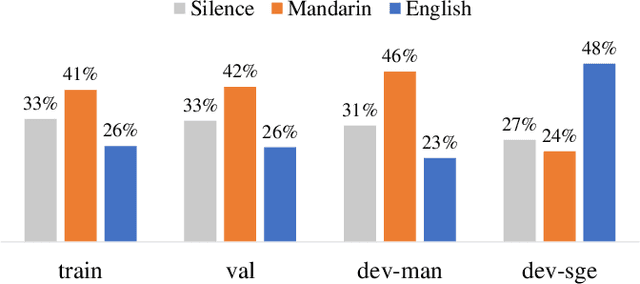
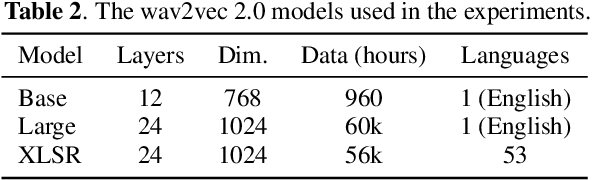
Code-switching (CS) is common in daily conversations where more than one language is used within a sentence. The difficulties of CS speech recognition lie in alternating languages and the lack of transcribed data. Therefore, this paper uses the recently successful self-supervised learning (SSL) methods to leverage many unlabeled speech data without CS. We show that hidden representations of SSL models offer frame-level language identity even if the models are trained with English speech only. Jointly training CTC and language identification modules with self-supervised speech representations improves CS speech recognition performance. Furthermore, using multilingual speech data for pre-training obtains the best CS speech recognition.