Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMandarin-English Code-switching Speech Recognition with Self-supervised Speech Representation Models
Paper and Code
Oct 07, 2021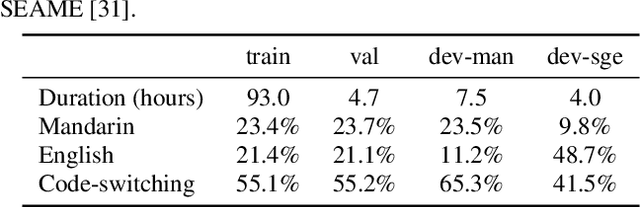
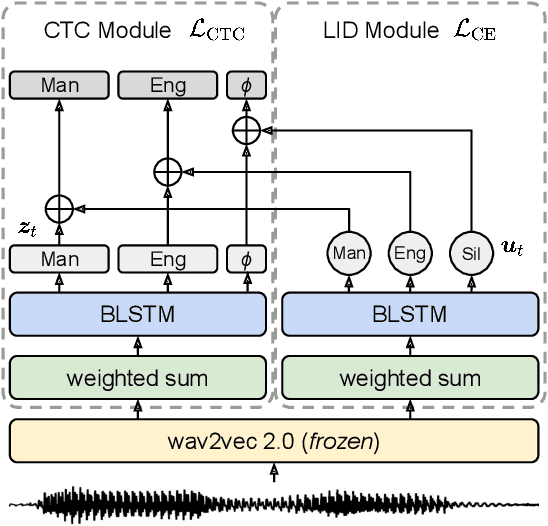
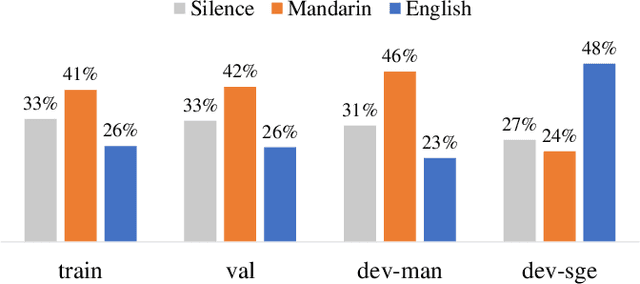
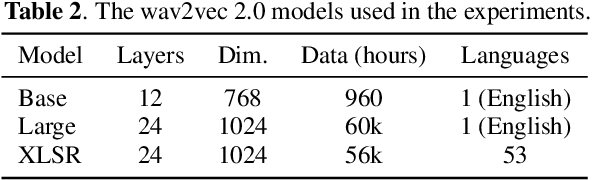
Code-switching (CS) is common in daily conversations where more than one language is used within a sentence. The difficulties of CS speech recognition lie in alternating languages and the lack of transcribed data. Therefore, this paper uses the recently successful self-supervised learning (SSL) methods to leverage many unlabeled speech data without CS. We show that hidden representations of SSL models offer frame-level language identity even if the models are trained with English speech only. Jointly training CTC and language identification modules with self-supervised speech representations improves CS speech recognition performance. Furthermore, using multilingual speech data for pre-training obtains the best CS speech recognition.
* Submitted to ICASSP 2022
View paper on