 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalizability of distilled self-supervised speech processing models under distorted settings
Paper and Code
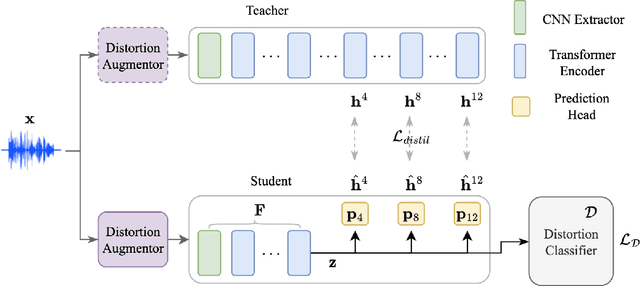
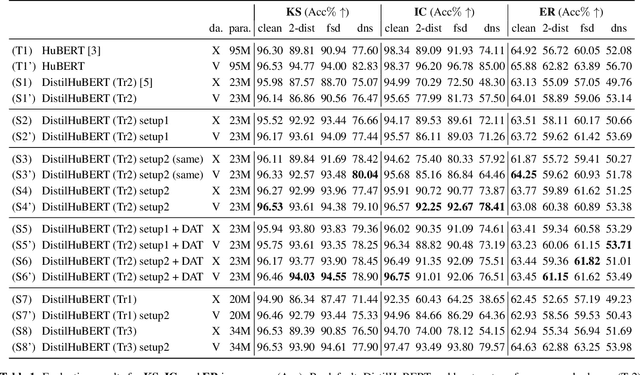
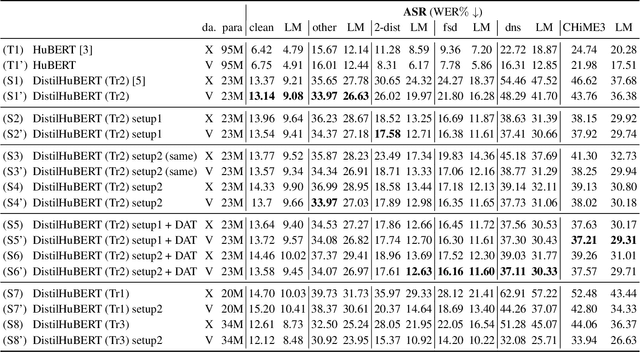
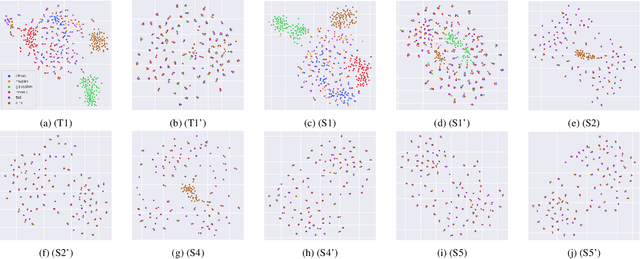
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.