 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.
Improving generalizability of distilled self-supervised speech processing models under distorted settings
Oct 20, 2022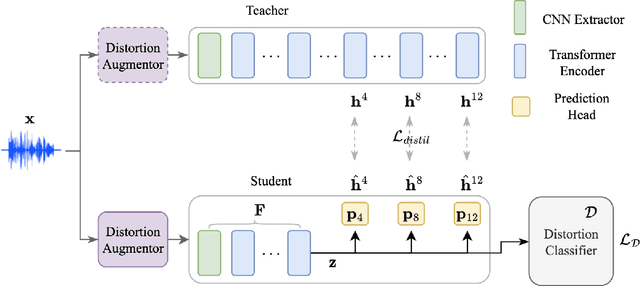
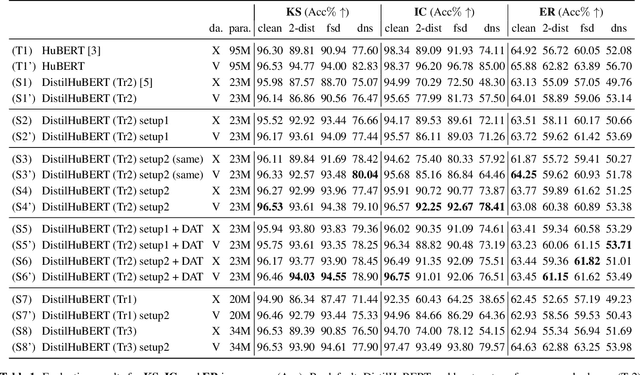
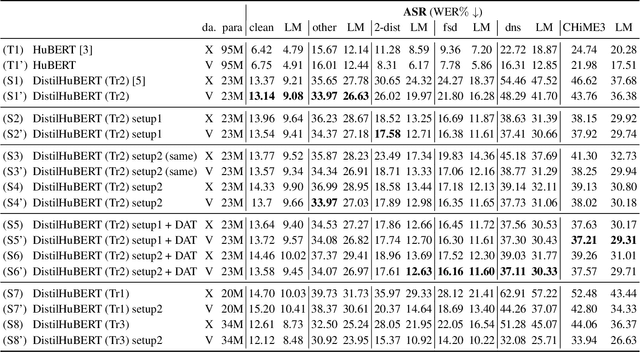
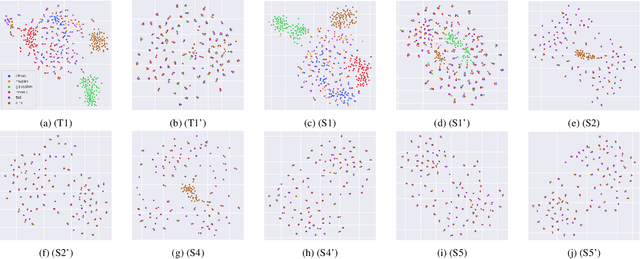
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.
Universal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
Apr 01, 2022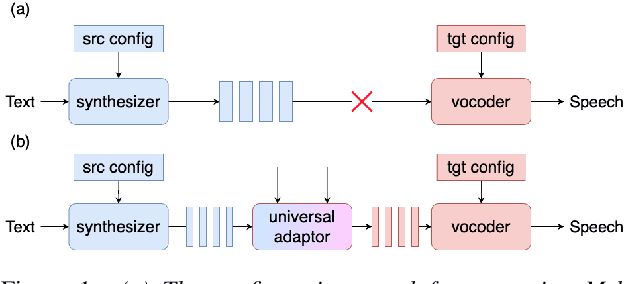

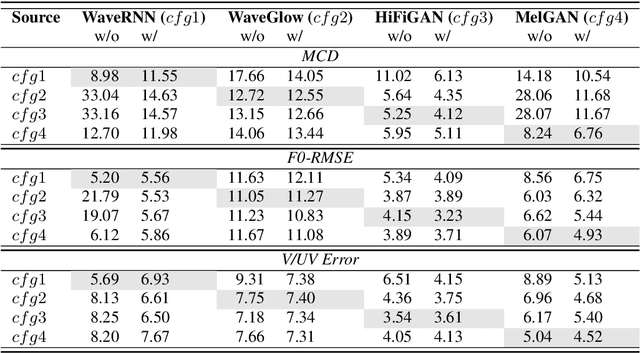
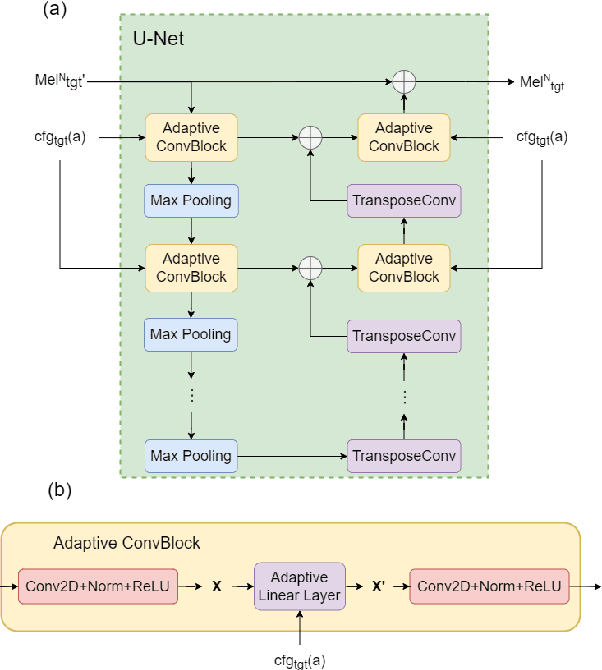
Most recent TTS systems are composed of a synthesizer and a vocoder. However, the existing synthesizers and vocoders can only be matched to acoustic features extracted with a specific configuration. Hence, we can't combine arbitrary synthesizers and vocoders together to form a complete TTS system, not to mention applying to a newly developed model. In this paper, we proposed a universal adaptor, which takes a Mel-spectogram parametrized by the source configuration and converts it into a Mel-spectrogram parametrized by the target configuration, as long as we feed in the source and the target configurations. Experiments show that the quality of speeches synthesized from our output of the universal adaptor is comparable to those synthesized from ground truth Mel-spectrogram. Moreover, our universal adaptor can be applied in the recent TTS systems and in multi-speaker speech synthesis without dropping quality.
Disentangling the Impacts of Language and Channel Variability on Speech Separation Networks
Mar 30, 2022
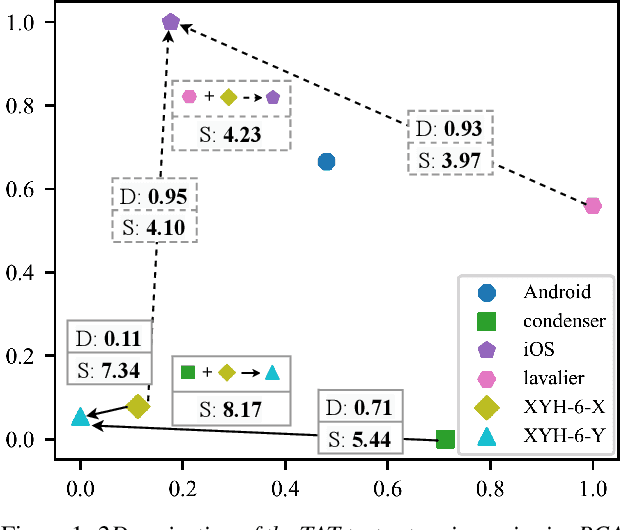


Because the performance of speech separation is excellent for speech in which two speakers completely overlap, research attention has been shifted to dealing with more realistic scenarios. However, domain mismatch between training/test situations due to factors, such as speaker, content, channel, and environment, remains a severe problem for speech separation. Speaker and environment mismatches have been studied in the existing literature. Nevertheless, there are few studies on speech content and channel mismatches. Moreover, the impacts of language and channel in these studies are mostly tangled. In this study, we create several datasets for various experiments. The results show that the impacts of different languages are small enough to be ignored compared to the impacts of different channels. In our experiments, training on data recorded by Android phones leads to the best generalizability. Moreover, we provide a new solution for channel mismatch by evaluating projection, where the channel similarity can be measured and used to effectively select additional training data to improve the performance of in-the-wild test data.
Dual-Path Filter Network: Speaker-Aware Modeling for Speech Separation
Jun 14, 2021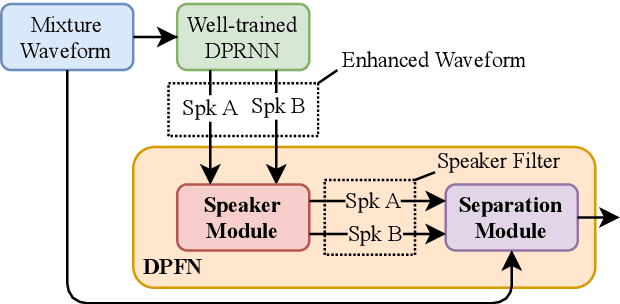



Speech separation has been extensively studied to deal with the cocktail party problem in recent years. All related approaches can be divided into two categories: time-frequency domain methods and time domain methods. In addition, some methods try to generate speaker vectors to support source separation. In this study, we propose a new model called dual-path filter network (DPFN). Our model focuses on the post-processing of speech separation to improve speech separation performance. DPFN is composed of two parts: the speaker module and the separation module. First, the speaker module infers the identities of the speakers. Then, the separation module uses the speakers' information to extract the voices of individual speakers from the mixture. DPFN constructed based on DPRNN-TasNet is not only superior to DPRNN-TasNet, but also avoids the problem of permutation-invariant training (PIT).