 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
Paper and Code
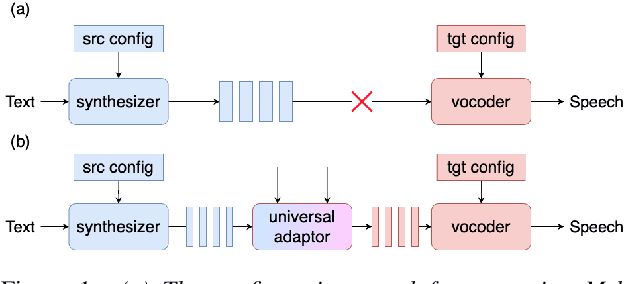

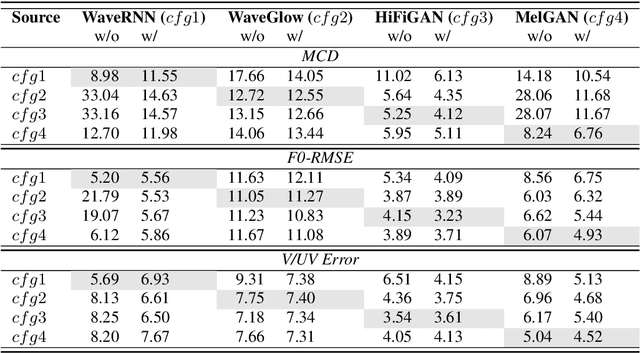
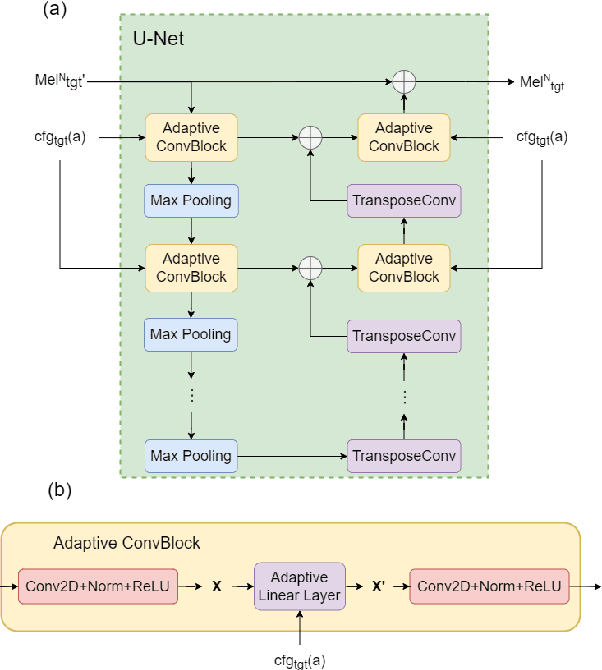
Most recent TTS systems are composed of a synthesizer and a vocoder. However, the existing synthesizers and vocoders can only be matched to acoustic features extracted with a specific configuration. Hence, we can't combine arbitrary synthesizers and vocoders together to form a complete TTS system, not to mention applying to a newly developed model. In this paper, we proposed a universal adaptor, which takes a Mel-spectogram parametrized by the source configuration and converts it into a Mel-spectrogram parametrized by the target configuration, as long as we feed in the source and the target configurations. Experiments show that the quality of speeches synthesized from our output of the universal adaptor is comparable to those synthesized from ground truth Mel-spectrogram. Moreover, our universal adaptor can be applied in the recent TTS systems and in multi-speaker speech synthesis without dropping quality.