 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Phone Recognition from Unpaired Audio and Phone Sequences Based on Generative Adversarial Network
Jul 29, 2022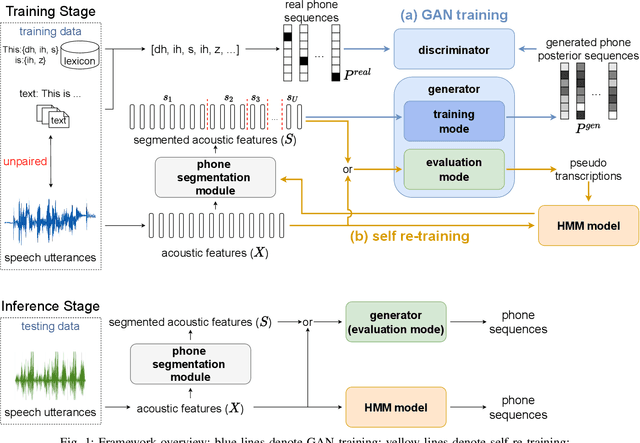



ASR has been shown to achieve great performance recently. However, most of them rely on massive paired data, which is not feasible for low-resource languages worldwide. This paper investigates how to learn directly from unpaired phone sequences and speech utterances. We design a two-stage iterative framework. GAN training is adopted in the first stage to find the mapping relationship between unpaired speech and phone sequence. In the second stage, another HMM model is introduced to train from the generator's output, which boosts the performance and provides a better segmentation for the next iteration. In the experiment, we first investigate different choices of model designs. Then we compare the framework to different types of baselines: (i) supervised methods (ii) acoustic unit discovery based methods (iii) methods learning from unpaired data. Our framework performs consistently better than all acoustic unit discovery methods and previous methods learning from unpaired data based on the TIMIT dataset.
Parallel Synthesis for Autoregressive Speech Generation
Apr 25, 2022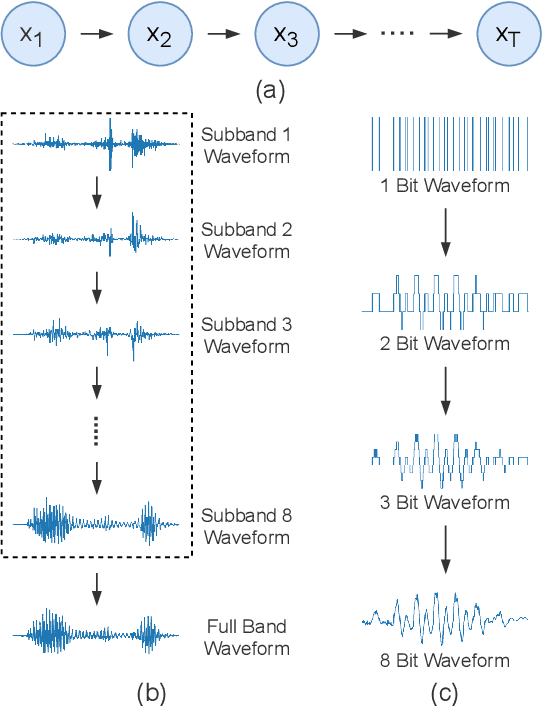
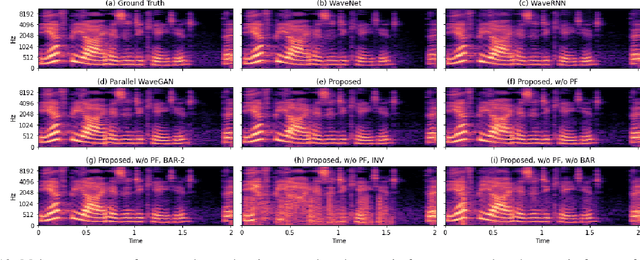
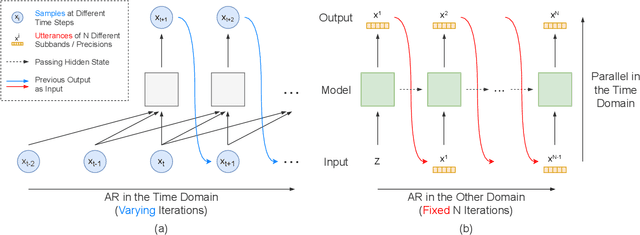
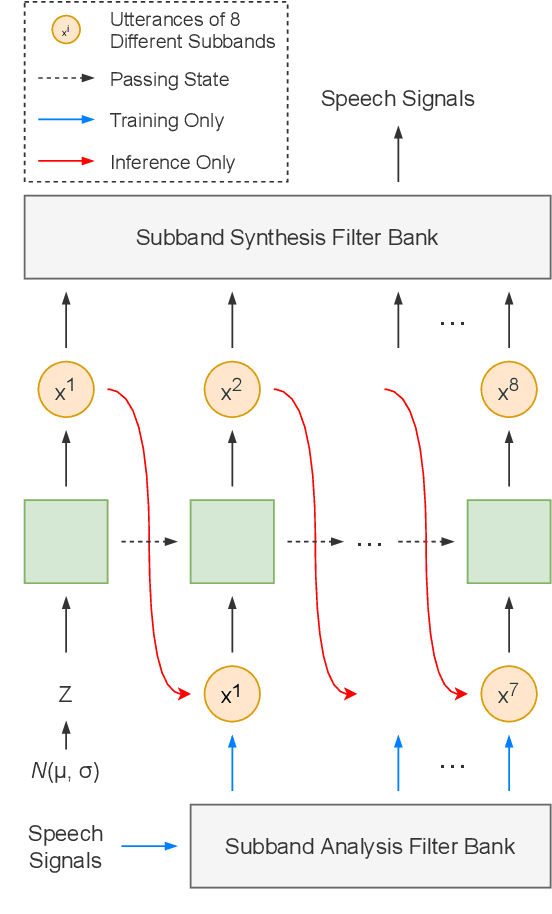
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.
Universal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
Apr 01, 2022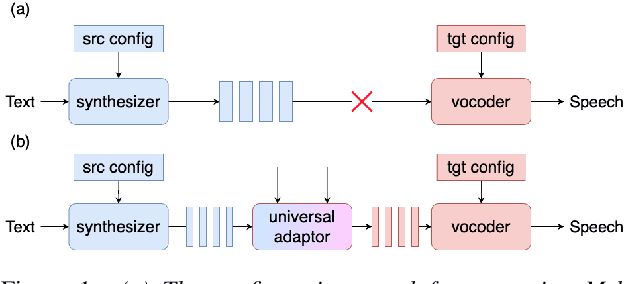

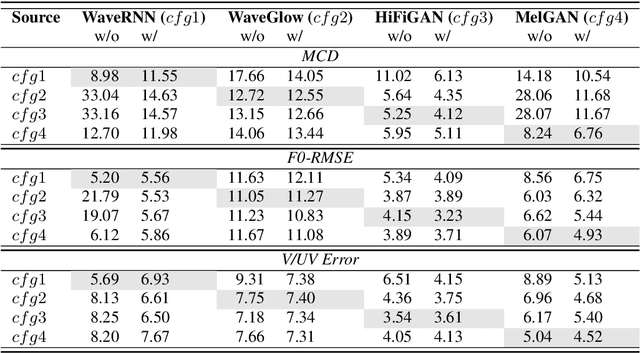
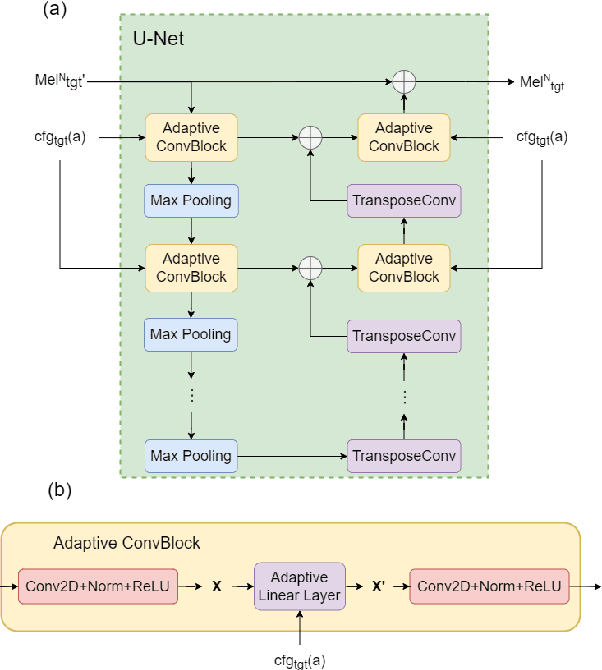
Most recent TTS systems are composed of a synthesizer and a vocoder. However, the existing synthesizers and vocoders can only be matched to acoustic features extracted with a specific configuration. Hence, we can't combine arbitrary synthesizers and vocoders together to form a complete TTS system, not to mention applying to a newly developed model. In this paper, we proposed a universal adaptor, which takes a Mel-spectogram parametrized by the source configuration and converts it into a Mel-spectrogram parametrized by the target configuration, as long as we feed in the source and the target configurations. Experiments show that the quality of speeches synthesized from our output of the universal adaptor is comparable to those synthesized from ground truth Mel-spectrogram. Moreover, our universal adaptor can be applied in the recent TTS systems and in multi-speaker speech synthesis without dropping quality.