 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Synthesis for Autoregressive Speech Generation
Paper and Code
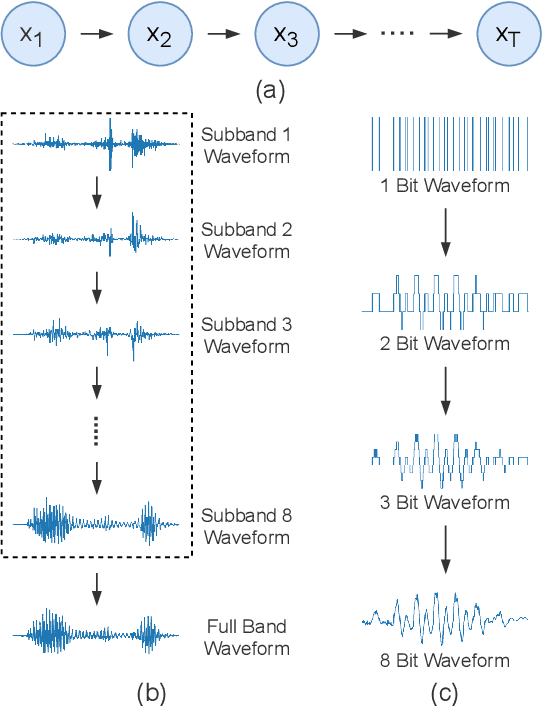
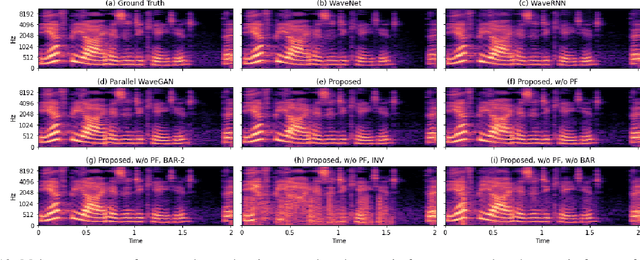
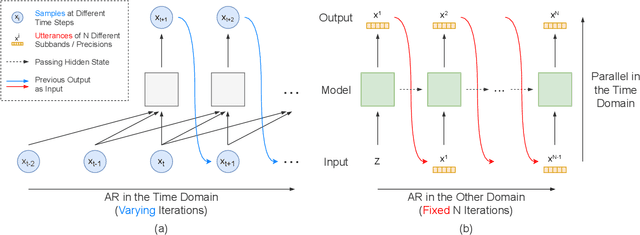
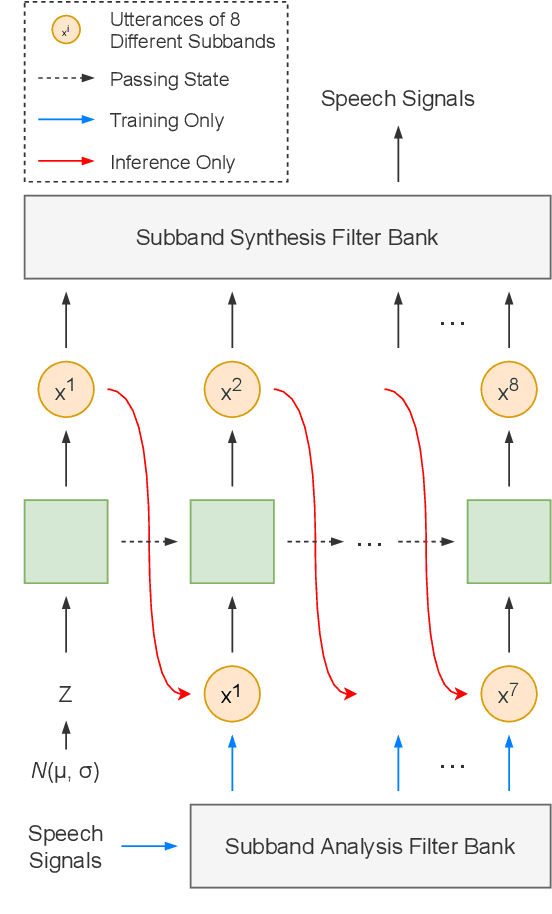
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.