 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Phone Recognition from Unpaired Audio and Phone Sequences Based on Generative Adversarial Network
Paper and Code
Jul 29, 2022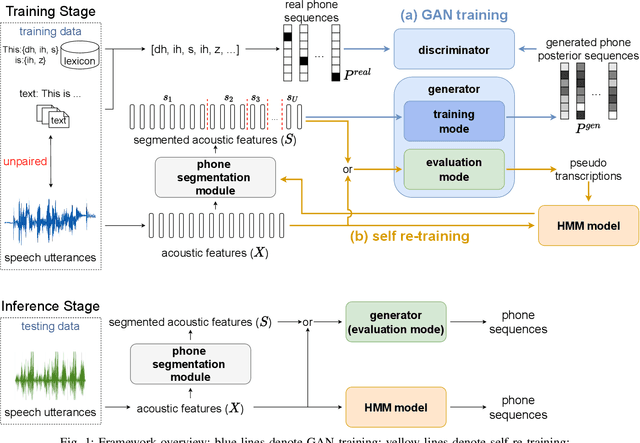



ASR has been shown to achieve great performance recently. However, most of them rely on massive paired data, which is not feasible for low-resource languages worldwide. This paper investigates how to learn directly from unpaired phone sequences and speech utterances. We design a two-stage iterative framework. GAN training is adopted in the first stage to find the mapping relationship between unpaired speech and phone sequence. In the second stage, another HMM model is introduced to train from the generator's output, which boosts the performance and provides a better segmentation for the next iteration. In the experiment, we first investigate different choices of model designs. Then we compare the framework to different types of baselines: (i) supervised methods (ii) acoustic unit discovery based methods (iii) methods learning from unpaired data. Our framework performs consistently better than all acoustic unit discovery methods and previous methods learning from unpaired data based on the TIMIT dataset.