 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Fallacy of Global Token Perplexity in Spoken Language Model Evaluation
Jan 09, 2026Generative spoken language models pretrained on large-scale raw audio can continue a speech prompt with appropriate content while preserving attributes like speaker and emotion, serving as foundation models for spoken dialogue. In prior literature, these models are often evaluated using ``global token perplexity'', which directly applies the text perplexity formulation to speech tokens. However, this practice overlooks fundamental differences between speech and text modalities, possibly leading to an underestimation of the speech characteristics. In this work, we propose a variety of likelihood- and generative-based evaluation methods that serve in place of naive global token perplexity. We demonstrate that the proposed evaluations more faithfully reflect perceived generation quality, as evidenced by stronger correlations with human-rated mean opinion scores (MOS). When assessed under the new metrics, the relative performance landscape of spoken language models is reshaped, revealing a significantly reduced gap between the best-performing model and the human topline. Together, these results suggest that appropriate evaluation is critical for accurately assessing progress in spoken language modeling.
CantoASR: Prosody-Aware ASR-LALM Collaboration for Low-Resource Cantonese
Nov 06, 2025Automatic speech recognition (ASR) is critical for language accessibility, yet low-resource Cantonese remains challenging due to limited annotated data, six lexical tones, tone sandhi, and accent variation. Existing ASR models, such as Whisper, often suffer from high word error rates. Large audio-language models (LALMs), in contrast, can leverage broader contextual reasoning but still require explicit tonal and prosodic acoustic cues. We introduce CantoASR, a collaborative ASR-LALM error correction framework that integrates forced alignment for acoustic feature extraction, a LoRA-finetuned Whisper for improved tone discrimination, and an instruction-tuned Qwen-Audio for prosody-aware correction. Evaluations on spontaneous Cantonese data show substantial CER gains over Whisper-Large-V3. These findings suggest that integrating acoustic cues with LALM reasoning provides a scalable strategy for low-resource tonal and dialectal ASR.
Pseudo2Real: Task Arithmetic for Pseudo-Label Correction in Automatic Speech Recognition
Oct 09, 2025Robust ASR under domain shift is crucial because real-world systems encounter unseen accents and domains with limited labeled data. Although pseudo-labeling offers a practical workaround, it often introduces systematic, accent-specific errors that filtering fails to fix. We ask: How can we correct these recurring biases without target ground truth? We propose a simple parameter-space correction: in a source domain containing both real and pseudo-labeled data, two ASR models are fine-tuned from the same initialization, one on ground-truth labels and the other on pseudo-labels, and their weight difference forms a correction vector that captures pseudo-label biases. When applied to a pseudo-labeled target model, this vector enhances recognition, achieving up to a 35% relative Word Error Rate (WER) reduction on AfriSpeech-200 across ten African accents with the Whisper tiny model.
Bloodroot: When Watermarking Turns Poisonous For Stealthy Backdoor
Oct 09, 2025Backdoor data poisoning is a crucial technique for ownership protection and defending against malicious attacks. Embedding hidden triggers in training data can manipulate model outputs, enabling provenance verification, and deterring unauthorized use. However, current audio backdoor methods are suboptimal, as poisoned audio often exhibits degraded perceptual quality, which is noticeable to human listeners. This work explores the intrinsic stealthiness and effectiveness of audio watermarking in achieving successful poisoning. We propose a novel Watermark-as-Trigger concept, integrated into the Bloodroot backdoor framework via adversarial LoRA fine-tuning, which enhances perceptual quality while achieving a much higher trigger success rate and clean-sample accuracy. Experiments on speech recognition (SR) and speaker identification (SID) datasets show that watermark-based poisoning remains effective under acoustic filtering and model pruning. The proposed Bloodroot backdoor framework not only secures data-to-model ownership, but also well reveals the risk of adversarial misuse.
Do You Hear What I Mean? Quantifying the Instruction-Perception Gap in Instruction-Guided Expressive Text-To-Speech Systems
Sep 18, 2025Instruction-guided text-to-speech (ITTS) enables users to control speech generation through natural language prompts, offering a more intuitive interface than traditional TTS. However, the alignment between user style instructions and listener perception remains largely unexplored. This work first presents a perceptual analysis of ITTS controllability across two expressive dimensions (adverbs of degree and graded emotion intensity) and collects human ratings on speaker age and word-level emphasis attributes. To comprehensively reveal the instruction-perception gap, we provide a data collection with large-scale human evaluations, named Expressive VOice Control (E-VOC) corpus. Furthermore, we reveal that (1) gpt-4o-mini-tts is the most reliable ITTS model with great alignment between instruction and generated utterances across acoustic dimensions. (2) The 5 analyzed ITTS systems tend to generate Adult voices even when the instructions ask to use child or Elderly voices. (3) Fine-grained control remains a major challenge, indicating that most ITTS systems have substantial room for improvement in interpreting slightly different attribute instructions.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
A correlation-permutation approach for speech-music encoders model merging
Jun 13, 2025Creating a unified speech and music model requires expensive pre-training. Model merging can instead create an unified audio model with minimal computational expense. However, direct merging is challenging when the models are not aligned in the weight space. Motivated by Git Re-Basin, we introduce a correlation-permutation approach that aligns a music encoder's internal layers with a speech encoder. We extend previous work to the case of merging transformer layers. The method computes a permutation matrix that maximizes the model's features-wise cross-correlations layer by layer, enabling effective fusion of these otherwise disjoint models. The merged model retains speech capabilities through this method while significantly enhancing music performance, achieving an improvement of 14.83 points in average score compared to linear interpolation model merging. This work allows the creation of unified audio models from independently trained encoders.
Multi-Distillation from Speech and Music Representation Models
Jun 08, 2025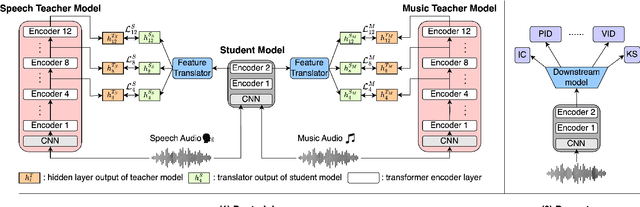

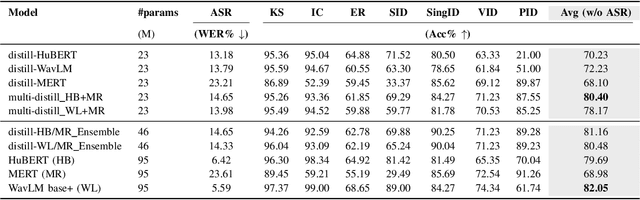
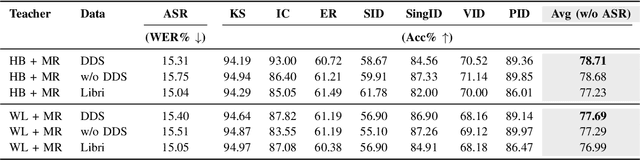
Real-world audio often mixes speech and music, yet models typically handle only one domain. This paper introduces a multi-teacher distillation framework that unifies speech and music models into a single one while significantly reducing model size. Our approach leverages the strengths of domain-specific teacher models, such as HuBERT for speech and MERT for music, and explores various strategies to balance both domains. Experiments across diverse tasks demonstrate that our model matches the performance of domain-specific models, showing the effectiveness of cross-domain distillation. Additionally, we conduct few-shot learning experiments, highlighting the need for general models in real-world scenarios where labeled data is limited. Our results show that our model not only performs on par with specialized models but also outperforms them in few-shot scenarios, proving that a cross-domain approach is essential and effective for diverse tasks with limited data.
CO-VADA: A Confidence-Oriented Voice Augmentation Debiasing Approach for Fair Speech Emotion Recognition
Jun 06, 2025Bias in speech emotion recognition (SER) systems often stems from spurious correlations between speaker characteristics and emotional labels, leading to unfair predictions across demographic groups. Many existing debiasing methods require model-specific changes or demographic annotations, limiting their practical use. We present CO-VADA, a Confidence-Oriented Voice Augmentation Debiasing Approach that mitigates bias without modifying model architecture or relying on demographic information. CO-VADA identifies training samples that reflect bias patterns present in the training data and then applies voice conversion to alter irrelevant attributes and generate samples. These augmented samples introduce speaker variations that differ from dominant patterns in the data, guiding the model to focus more on emotion-relevant features. Our framework is compatible with various SER models and voice conversion tools, making it a scalable and practical solution for improving fairness in SER systems.