 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models
Sep 21, 2024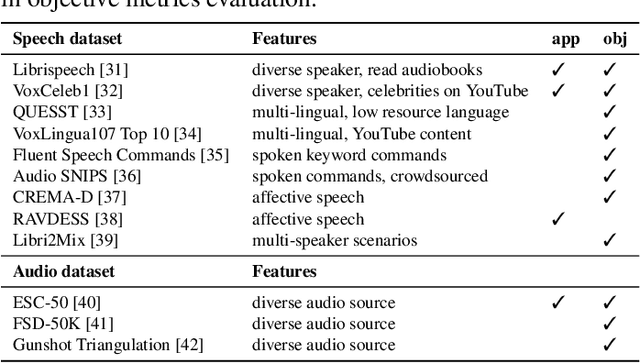
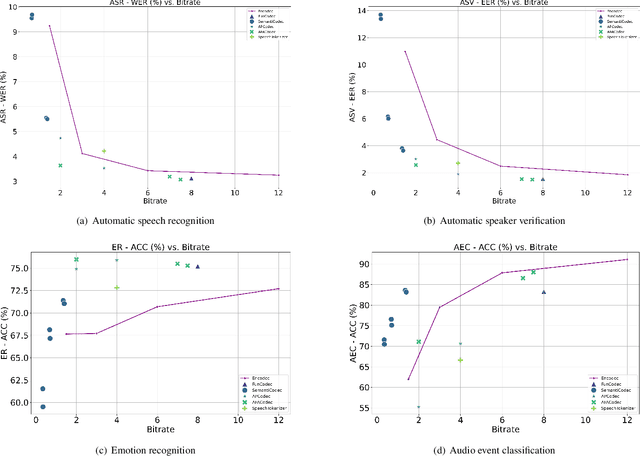
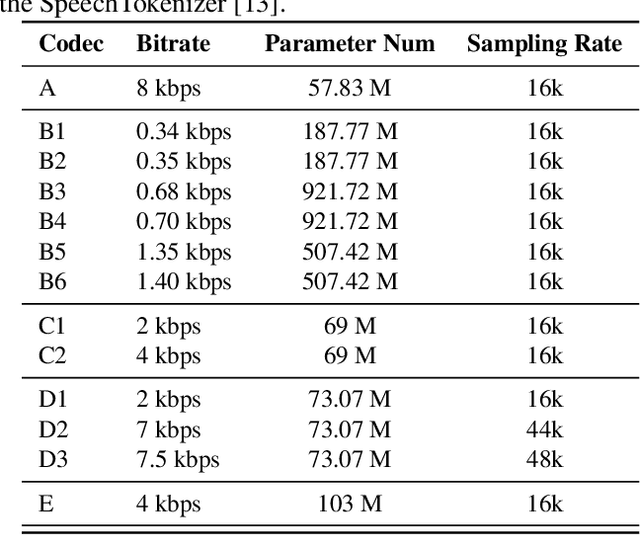
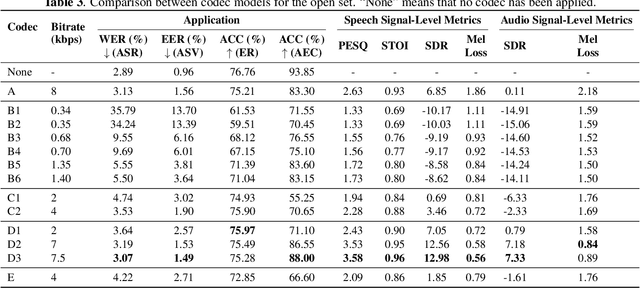
Neural audio codec models are becoming increasingly important as they serve as tokenizers for audio, enabling efficient transmission or facilitating speech language modeling. The ideal neural audio codec should maintain content, paralinguistics, speaker characteristics, and audio information even at low bitrates. Recently, numerous advanced neural codec models have been proposed. However, codec models are often tested under varying experimental conditions. As a result, we introduce the Codec-SUPERB challenge at SLT 2024, designed to facilitate fair and lightweight comparisons among existing codec models and inspire advancements in the field. This challenge brings together representative speech applications and objective metrics, and carefully selects license-free datasets, sampling them into small sets to reduce evaluation computation costs. This paper presents the challenge's rules, datasets, five participant systems, results, and findings.