 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
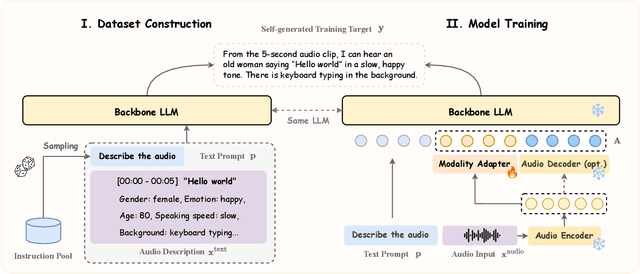


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
A Novel Deep Learning Framework for Efficient Multichannel Acoustic Feedback Control
May 21, 2025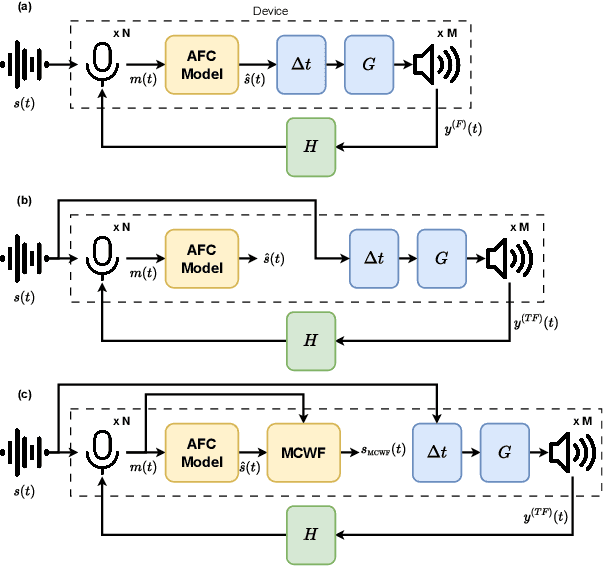
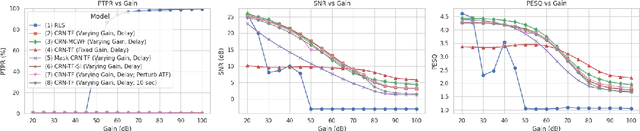
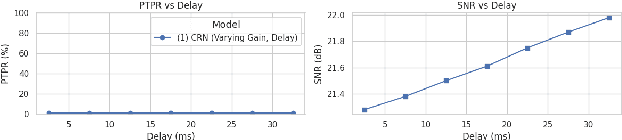
This study presents a deep-learning framework for controlling multichannel acoustic feedback in audio devices. Traditional digital signal processing methods struggle with convergence when dealing with highly correlated noise such as feedback. We introduce a Convolutional Recurrent Network that efficiently combines spatial and temporal processing, significantly enhancing speech enhancement capabilities with lower computational demands. Our approach utilizes three training methods: In-a-Loop Training, Teacher Forcing, and a Hybrid strategy with a Multichannel Wiener Filter, optimizing performance in complex acoustic environments. This scalable framework offers a robust solution for real-world applications, making significant advances in Acoustic Feedback Control technology.
Codec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models
Sep 21, 2024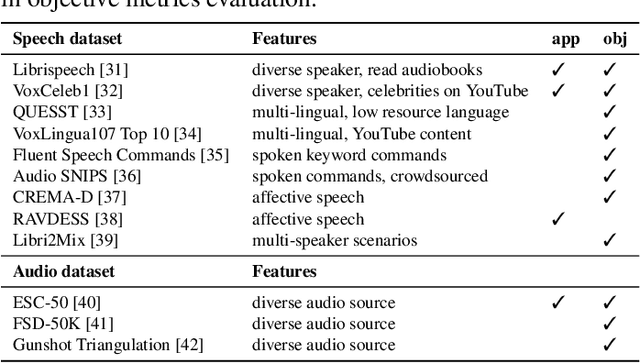
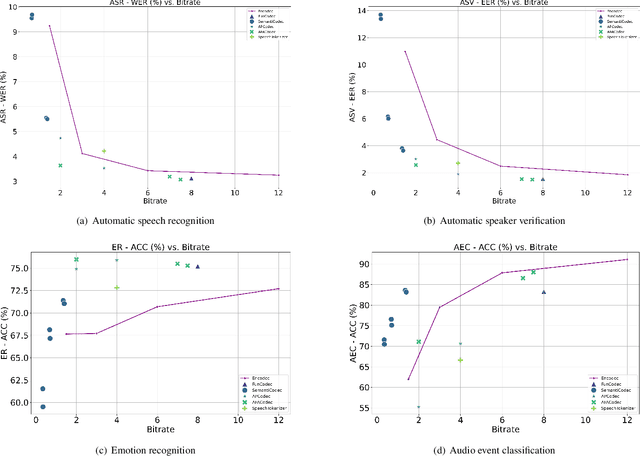
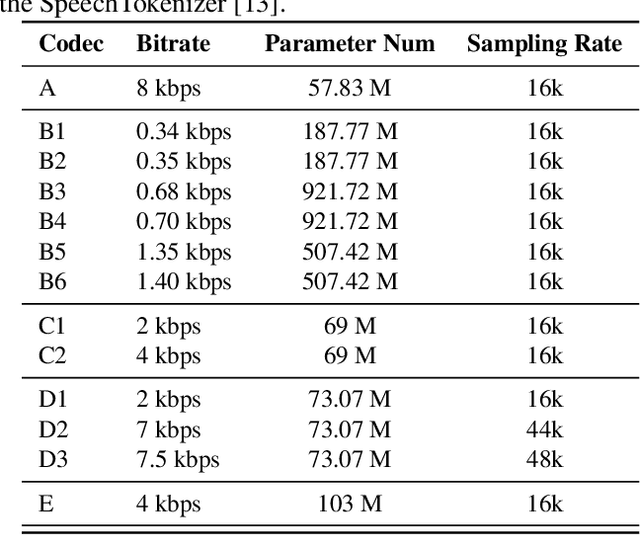
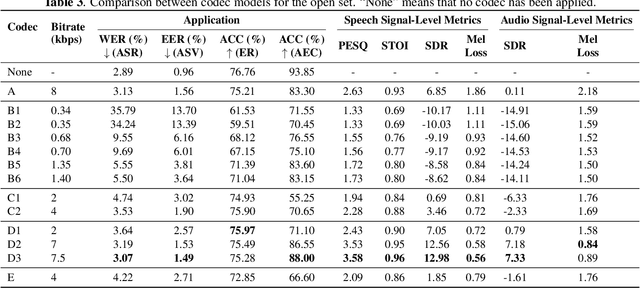
Neural audio codec models are becoming increasingly important as they serve as tokenizers for audio, enabling efficient transmission or facilitating speech language modeling. The ideal neural audio codec should maintain content, paralinguistics, speaker characteristics, and audio information even at low bitrates. Recently, numerous advanced neural codec models have been proposed. However, codec models are often tested under varying experimental conditions. As a result, we introduce the Codec-SUPERB challenge at SLT 2024, designed to facilitate fair and lightweight comparisons among existing codec models and inspire advancements in the field. This challenge brings together representative speech applications and objective metrics, and carefully selects license-free datasets, sampling them into small sets to reduce evaluation computation costs. This paper presents the challenge's rules, datasets, five participant systems, results, and findings.
SpeechPrompt: Prompting Speech Language Models for Speech Processing Tasks
Aug 23, 2024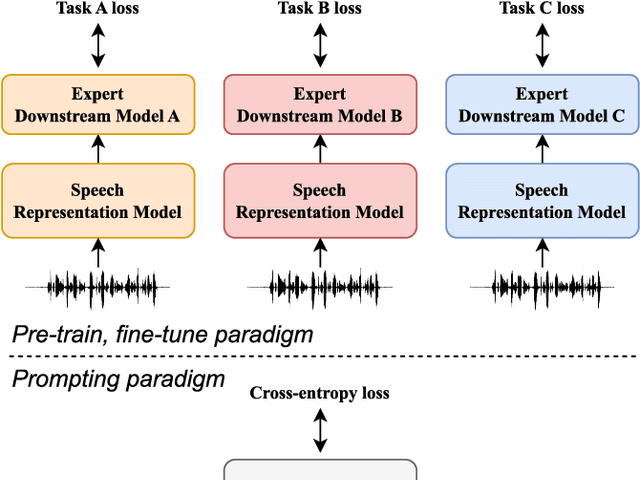
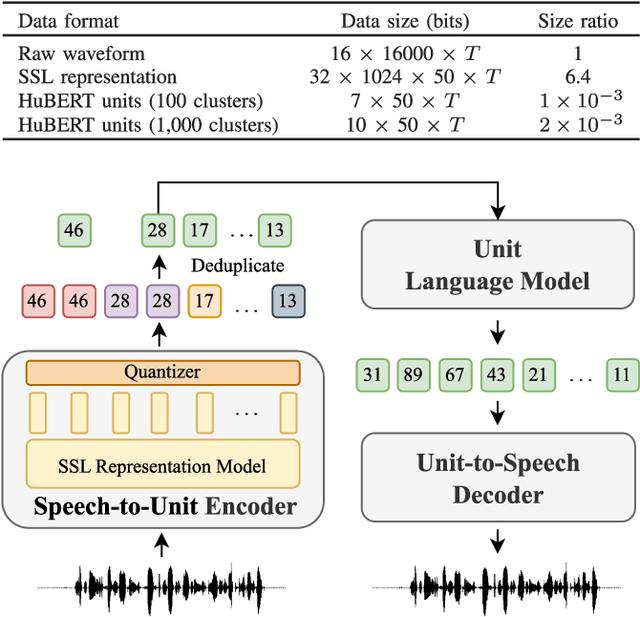
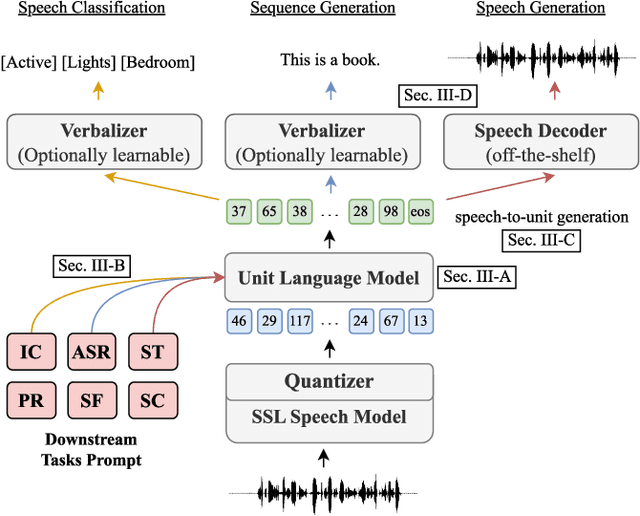
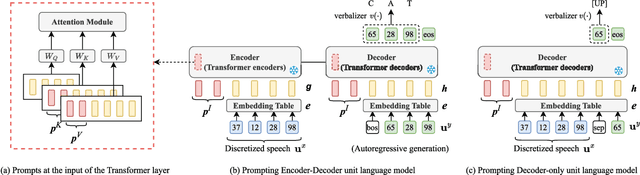
Prompting has become a practical method for utilizing pre-trained language models (LMs). This approach offers several advantages. It allows an LM to adapt to new tasks with minimal training and parameter updates, thus achieving efficiency in both storage and computation. Additionally, prompting modifies only the LM's inputs and harnesses the generative capabilities of language models to address various downstream tasks in a unified manner. This significantly reduces the need for human labor in designing task-specific models. These advantages become even more evident as the number of tasks served by the LM scales up. Motivated by the strengths of prompting, we are the first to explore the potential of prompting speech LMs in the domain of speech processing. Recently, there has been a growing interest in converting speech into discrete units for language modeling. Our pioneer research demonstrates that these quantized speech units are highly versatile within our unified prompting framework. Not only can they serve as class labels, but they also contain rich phonetic information that can be re-synthesized back into speech signals for speech generation tasks. Specifically, we reformulate speech processing tasks into speech-to-unit generation tasks. As a result, we can seamlessly integrate tasks such as speech classification, sequence generation, and speech generation within a single, unified prompting framework. The experiment results show that the prompting method can achieve competitive performance compared to the strong fine-tuning method based on self-supervised learning models with a similar number of trainable parameters. The prompting method also shows promising results in the few-shot setting. Moreover, with the advanced speech LMs coming into the stage, the proposed prompting framework attains great potential.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
Codec-SUPERB: An In-Depth Analysis of Sound Codec Models
Feb 20, 2024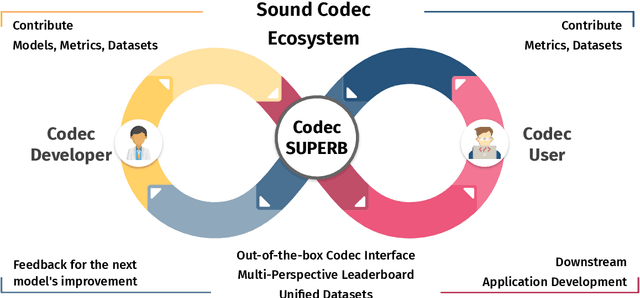
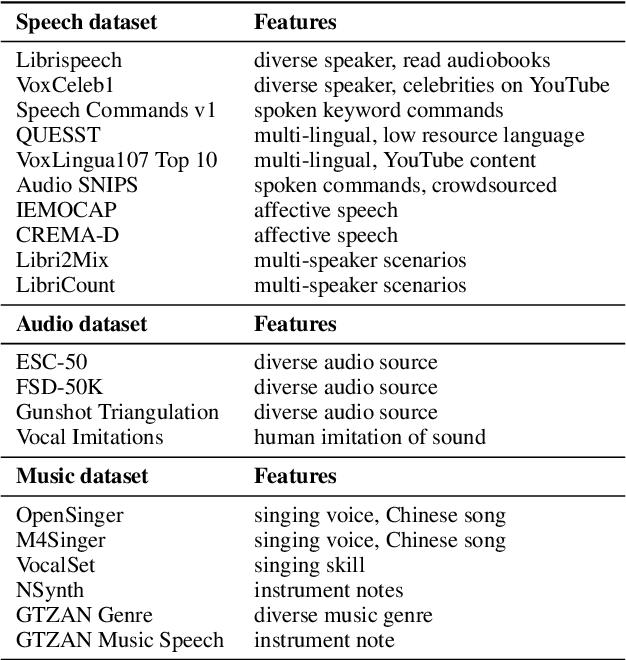
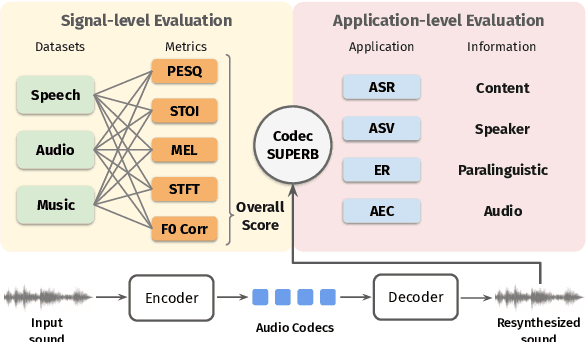
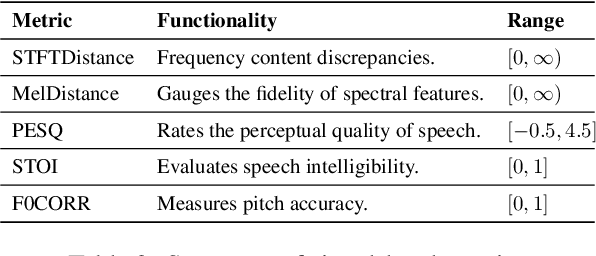
The sound codec's dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. Recent years have witnessed significant developments in codec models. The ideal sound codec should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal sound information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. This study introduces Codec-SUPERB, an acronym for Codec sound processing Universal PERformance Benchmark. It is an ecosystem designed to assess codec models across representative sound applications and signal-level metrics rooted in sound domain knowledge.Codec-SUPERB simplifies result sharing through an online leaderboard, promoting collaboration within a community-driven benchmark database, thereby stimulating new development cycles for codecs. Furthermore, we undertake an in-depth analysis to offer insights into codec models from both application and signal perspectives, diverging from previous codec papers mainly concentrating on signal-level comparisons. Finally, we will release codes, the leaderboard, and data to accelerate progress within the community.
SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts
Jun 19, 2023



Large language models (LLMs) have gained considerable attention for Artificial Intelligence Generated Content (AIGC), particularly with the emergence of ChatGPT. However, the direct adaptation of continuous speech to LLMs that process discrete tokens remains an unsolved challenge, hindering the application of LLMs for speech generation. The advanced speech LMs are in the corner, as that speech signals encapsulate a wealth of information, including speaker and emotion, beyond textual data alone. Prompt tuning has demonstrated notable gains in parameter efficiency and competitive performance on some speech classification tasks. However, the extent to which prompts can effectively elicit generation tasks from speech LMs remains an open question. In this paper, we present pioneering research that explores the application of prompt tuning to stimulate speech LMs for various generation tasks, within a unified framework called SpeechGen, with around 10M trainable parameters. The proposed unified framework holds great promise for efficiency and effectiveness, particularly with the imminent arrival of advanced speech LMs, which will significantly enhance the capabilities of the framework. The code and demos of SpeechGen will be available on the project website: \url{https://ga642381.github.io/SpeechPrompt/speechgen}
Improving the transferability of speech separation by meta-learning
Mar 11, 2022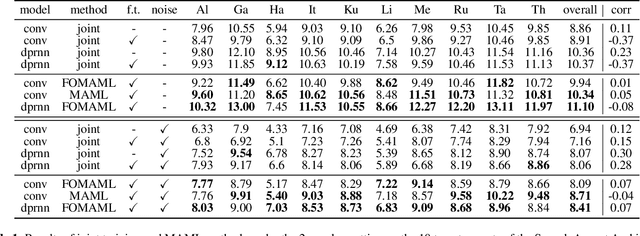
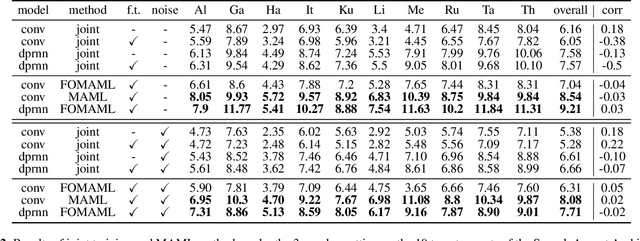
Speech separation aims to separate multiple speech sources from a speech mixture. Although speech separation is well-solved on some existing English speech separation benchmarks, it is worthy of more investigation on the generalizability of speech separation models on the accents or languages unseen during training. This paper adopts meta-learning based methods to improve the transferability of speech separation models. With the meta-learning based methods, we discovered that only using speech data with one accent, the native English accent, as our training data, the models still can be adapted to new unseen accents on the Speech Accent Archive. We compared the results with a human-rated native-likeness of accents, showing that the transferability of MAML methods has less relation to the similarity of data between the training and testing phase compared to the typical transfer learning methods. Furthermore, we found that models can deal with different language data from the CommonVoice corpus during the testing phase. Most of all, the MAML methods outperform typical transfer learning methods when it comes to new accents, new speakers, new languages, and noisy environments.
Multi-accent Speech Separation with One Shot Learning
Jun 28, 2021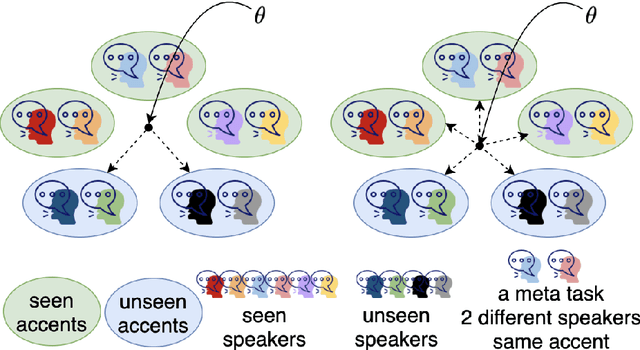
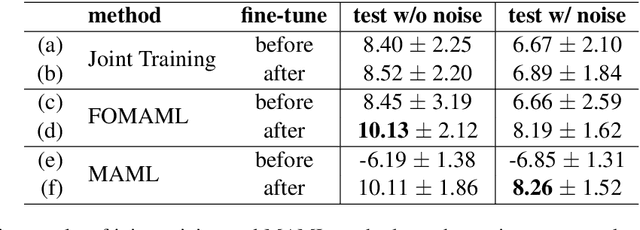
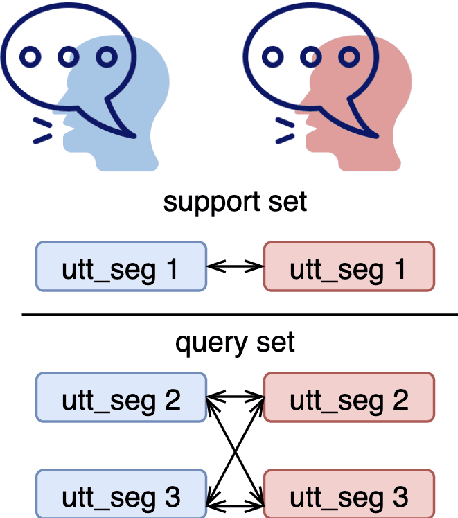
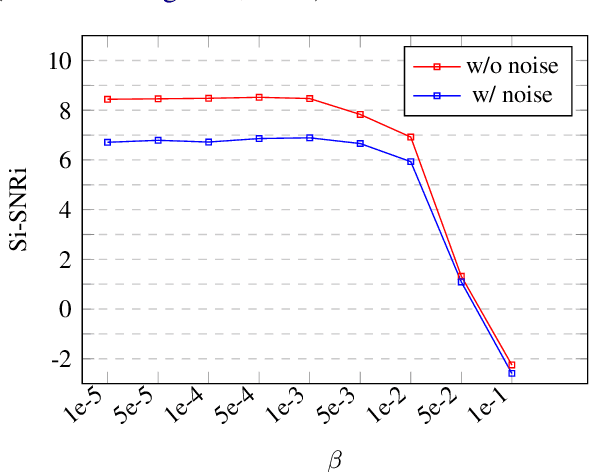
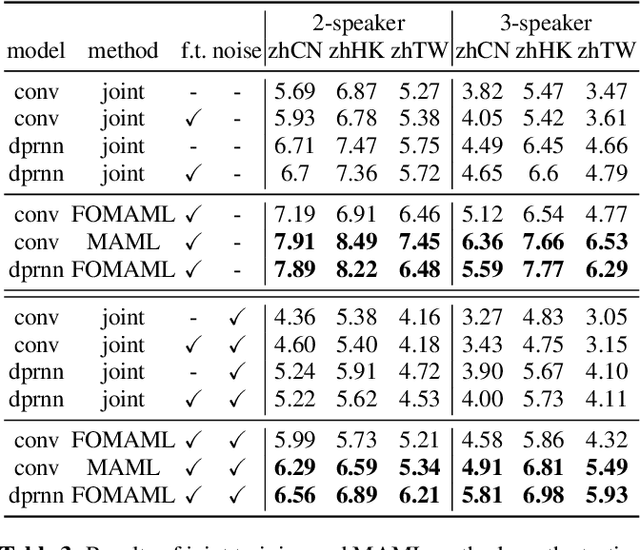
Speech separation is a problem in the field of speech processing that has been studied in full swing recently. However, there has not been much work studying a multi-accent speech separation scenario. Unseen speakers with new accents and noise aroused the domain mismatch problem which cannot be easily solved by conventional joint training methods. Thus, we applied MAML and FOMAML to tackle this problem and obtained higher average Si-SNRi values than joint training on almost all the unseen accents. This proved that these two methods do have the ability to generate well-trained parameters for adapting to speech mixtures of new speakers and accents. Furthermore, we found out that FOMAML obtains similar performance compared to MAML while saving a lot of time.
MITAS: A Compressed Time-Domain Audio Separation Network with Parameter Sharing
Dec 09, 2019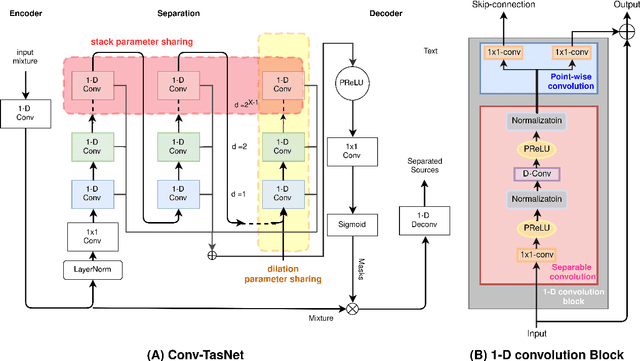
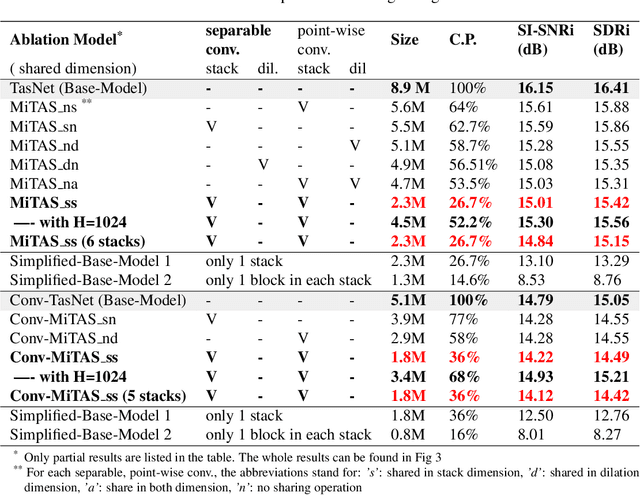
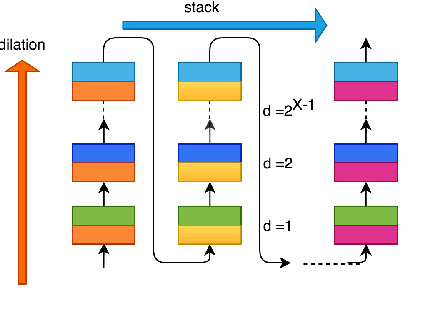
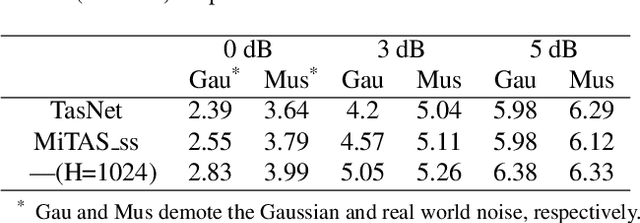
Deep learning methods have brought substantial advancements in speech separation (SS). Nevertheless, it remains challenging to deploy deep-learning-based models on edge devices. Thus, identifying an effective way to compress these large models without hurting SS performance has become an important research topic. Recently, TasNet and Conv-TasNet have been proposed. They achieved state-of-the-art results on several standardized SS tasks. Moreover, their low latency natures make them definitely suitable for real-time on-device applications. In this study, we propose two parameter-sharing schemes to lower the memory consumption on TasNet and Conv-TasNet. Accordingly, we derive a novel so-called MiTAS (Mini TasNet). Our experimental results first confirmed the robustness of our MiTAS on two types of perturbations in mixed audio. We also designed a series of ablation experiments to analyze the relation between SS performance and the amount of parameters in the model. The results show that MiTAS is able to reduce the model size by a factor of four while maintaining comparable SS performance with improved stability as compared to TasNet and Conv-TasNet. This suggests that MiTAS is more suitable for real-time low latency applications.