 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the transferability of speech separation by meta-learning
Paper and Code
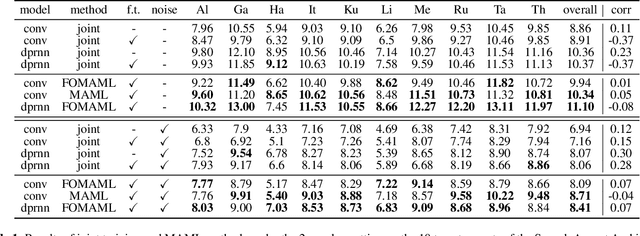
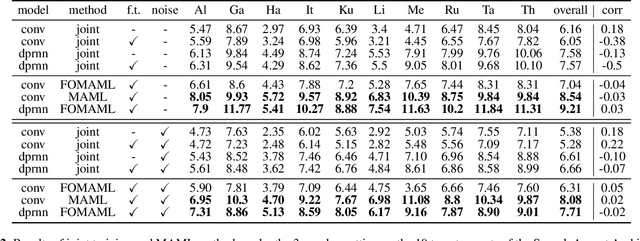
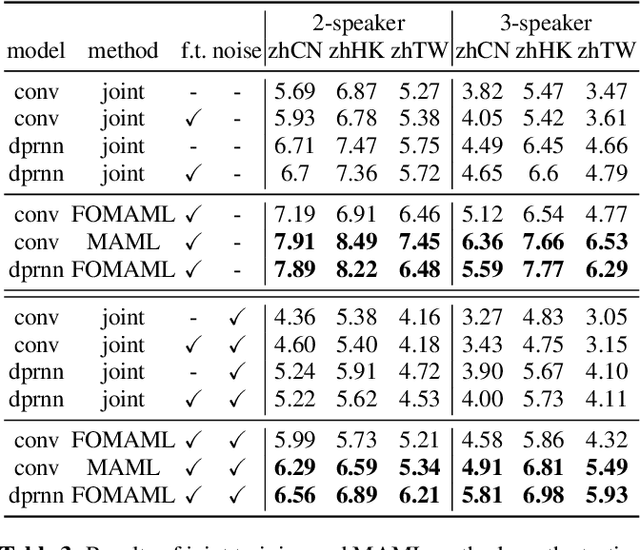
Speech separation aims to separate multiple speech sources from a speech mixture. Although speech separation is well-solved on some existing English speech separation benchmarks, it is worthy of more investigation on the generalizability of speech separation models on the accents or languages unseen during training. This paper adopts meta-learning based methods to improve the transferability of speech separation models. With the meta-learning based methods, we discovered that only using speech data with one accent, the native English accent, as our training data, the models still can be adapted to new unseen accents on the Speech Accent Archive. We compared the results with a human-rated native-likeness of accents, showing that the transferability of MAML methods has less relation to the similarity of data between the training and testing phase compared to the typical transfer learning methods. Furthermore, we found that models can deal with different language data from the CommonVoice corpus during the testing phase. Most of all, the MAML methods outperform typical transfer learning methods when it comes to new accents, new speakers, new languages, and noisy environments.