 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textit{FocaLogic}: Logic-Based Interpretation of Visual Model Decisions
Jan 17, 2026Interpretability of modern visual models is crucial, particularly in high-stakes applications. However, existing interpretability methods typically suffer from either reliance on white-box model access or insufficient quantitative rigor. To address these limitations, we introduce FocaLogic, a novel model-agnostic framework designed to interpret and quantify visual model decision-making through logic-based representations. FocaLogic identifies minimal interpretable subsets of visual regions-termed visual focuses-that decisively influence model predictions. It translates these visual focuses into precise and compact logical expressions, enabling transparent and structured interpretations. Additionally, we propose a suite of quantitative metrics, including focus precision, recall, and divergence, to objectively evaluate model behavior across diverse scenarios. Empirical analyses demonstrate FocaLogic's capability to uncover critical insights such as training-induced concentration, increasing focus accuracy through generalization, and anomalous focuses under biases and adversarial attacks. Overall, FocaLogic provides a systematic, scalable, and quantitative solution for interpreting visual models.
Concept-SAE: Active Causal Probing of Visual Model Behavior
Sep 26, 2025Standard Sparse Autoencoders (SAEs) excel at discovering a dictionary of a model's learned features, offering a powerful observational lens. However, the ambiguous and ungrounded nature of these features makes them unreliable instruments for the active, causal probing of model behavior. To solve this, we introduce Concept-SAE, a framework that forges semantically grounded concept tokens through a novel hybrid disentanglement strategy. We first quantitatively demonstrate that our dual-supervision approach produces tokens that are remarkably faithful and spatially localized, outperforming alternative methods in disentanglement. This validated fidelity enables two critical applications: (1) we probe the causal link between internal concepts and predictions via direct intervention, and (2) we probe the model's failure modes by systematically localizing adversarial vulnerabilities to specific layers. Concept-SAE provides a validated blueprint for moving beyond correlational interpretation to the mechanistic, causal probing of model behavior.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
DebugAgent: Efficient and Interpretable Error Slice Discovery for Comprehensive Model Debugging
Jan 28, 2025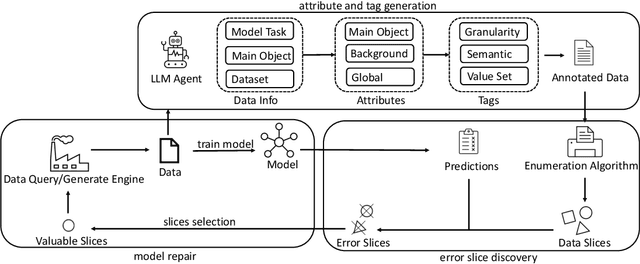


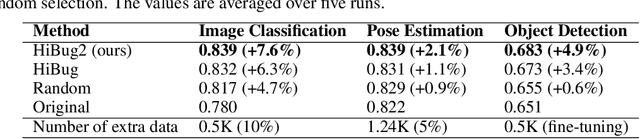
Despite the significant success of deep learning models in computer vision, they often exhibit systematic failures on specific data subsets, known as error slices. Identifying and mitigating these error slices is crucial to enhancing model robustness and reliability in real-world scenarios. In this paper, we introduce DebugAgent, an automated framework for error slice discovery and model repair. DebugAgent first generates task-specific visual attributes to highlight instances prone to errors through an interpretable and structured process. It then employs an efficient slice enumeration algorithm to systematically identify error slices, overcoming the combinatorial challenges that arise during slice exploration. Additionally, DebugAgent extends its capabilities by predicting error slices beyond the validation set, addressing a key limitation of prior approaches. Extensive experiments across multiple domains, including image classification, pose estimation, and object detection - show that DebugAgent not only improves the coherence and precision of identified error slices but also significantly enhances the model repair capabilities.
The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities
Jan 25, 2025Llama-Breeze2 (hereinafter referred to as Breeze2) is a suite of advanced multi-modal language models, available in 3B and 8B parameter configurations, specifically designed to enhance Traditional Chinese language representation. Building upon the Llama 3.2 model family, we continue the pre-training of Breeze2 on an extensive corpus to enhance the linguistic and cultural heritage of Traditional Chinese. In addition to language modeling capabilities, we significantly augment the models with function calling and vision understanding capabilities. At the time of this publication, as far as we are aware, absent reasoning-inducing prompts, Breeze2 are the strongest performing models in Traditional Chinese function calling and image understanding in its size class. The effectiveness of Breeze2 is benchmarked across various tasks, including Taiwan general knowledge, instruction-following, long context, function calling, and vision understanding. We are publicly releasing all Breeze2 models under the Llama 3.2 Community License. We also showcase the capabilities of the model running on mobile platform with a mobile application which we also open source.
Evaluating Text-to-Image Generative Models: An Empirical Study on Human Image Synthesis
Mar 08, 2024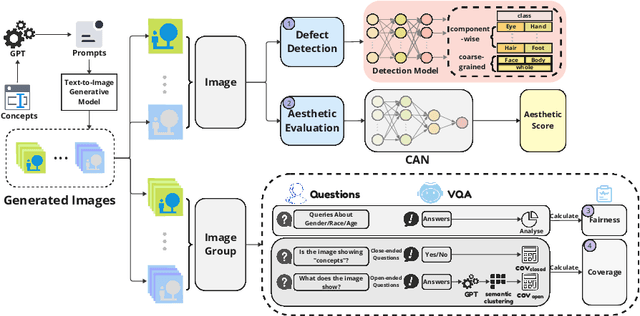
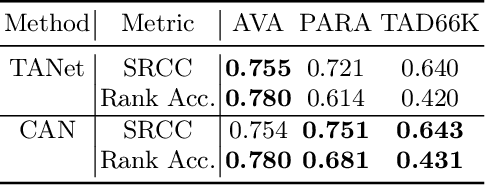
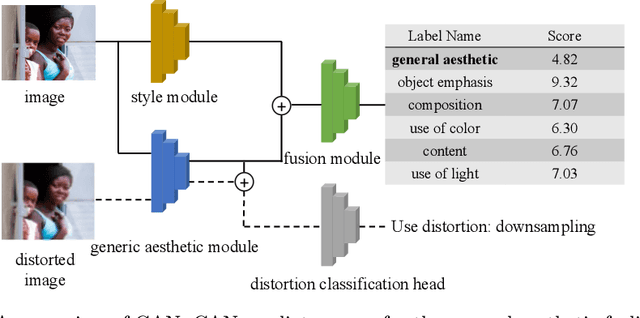
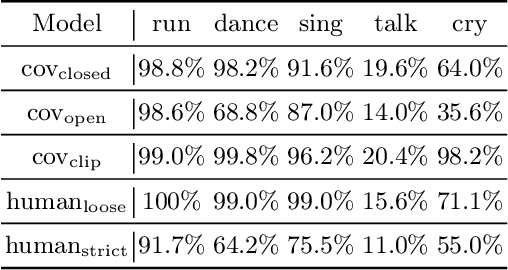
In this paper, we present an empirical study introducing a nuanced evaluation framework for text-to-image (T2I) generative models, applied to human image synthesis. Our framework categorizes evaluations into two distinct groups: first, focusing on image qualities such as aesthetics and realism, and second, examining text conditions through concept coverage and fairness. We introduce an innovative aesthetic score prediction model that assesses the visual appeal of generated images and unveils the first dataset marked with low-quality regions in generated human images to facilitate automatic defect detection. Our exploration into concept coverage probes the model's effectiveness in interpreting and rendering text-based concepts accurately, while our analysis of fairness reveals biases in model outputs, with an emphasis on gender, race, and age. While our study is grounded in human imagery, this dual-faceted approach is designed with the flexibility to be applicable to other forms of image generation, enhancing our understanding of generative models and paving the way to the next generation of more sophisticated, contextually aware, and ethically attuned generative models. We will release our code, the data used for evaluating generative models and the dataset annotated with defective areas soon.
FrAug: Frequency Domain Augmentation for Time Series Forecasting
Feb 18, 2023Data augmentation (DA) has become a de facto solution to expand training data size for deep learning. With the proliferation of deep models for time series analysis, various time series DA techniques are proposed in the literature, e.g., cropping-, warping-, flipping-, and mixup-based methods. However, these augmentation methods mainly apply to time series classification and anomaly detection tasks. In time series forecasting (TSF), we need to model the fine-grained temporal relationship within time series segments to generate accurate forecasting results given data in a look-back window. Existing DA solutions in the time domain would break such a relationship, leading to poor forecasting accuracy. To tackle this problem, this paper proposes simple yet effective frequency domain augmentation techniques that ensure the semantic consistency of augmented data-label pairs in forecasting, named FrAug. We conduct extensive experiments on eight widely-used benchmarks with several state-of-the-art TSF deep models. Our results show that FrAug can boost the forecasting accuracy of TSF models in most cases. Moreover, we show that FrAug enables models trained with 1\% of the original training data to achieve similar performance to the ones trained on full training data, which is particularly attractive for cold-start forecasting. Finally, we show that applying test-time training with FrAug greatly improves forecasting accuracy for time series with significant distribution shifts, which often occurs in real-life TSF applications. Our code is available at https://anonymous.4open.science/r/Fraug-more-results-1785.
An Empirical Study on the Efficacy of Deep Active Learning for Image Classification
Nov 30, 2022



Deep Active Learning (DAL) has been advocated as a promising method to reduce labeling costs in supervised learning. However, existing evaluations of DAL methods are based on different settings, and their results are controversial. To tackle this issue, this paper comprehensively evaluates 19 existing DAL methods in a uniform setting, including traditional fully-\underline{s}upervised \underline{a}ctive \underline{l}earning (SAL) strategies and emerging \underline{s}emi-\underline{s}upervised \underline{a}ctive \underline{l}earning (SSAL) techniques. We have several non-trivial findings. First, most SAL methods cannot achieve higher accuracy than random selection. Second, semi-supervised training brings significant performance improvement compared to pure SAL methods. Third, performing data selection in the SSAL setting can achieve a significant and consistent performance improvement, especially with abundant unlabeled data. Our findings produce the following guidance for practitioners: one should (i) apply SSAL early and (ii) collect more unlabeled data whenever possible, for better model performance.
Are Transformers Effective for Time Series Forecasting?
Jun 01, 2022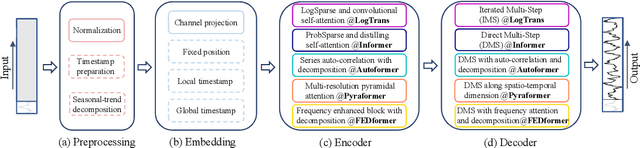

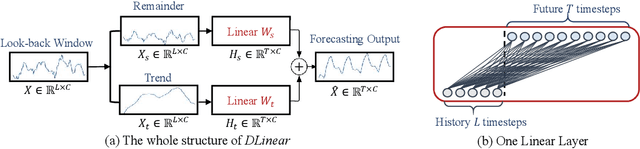
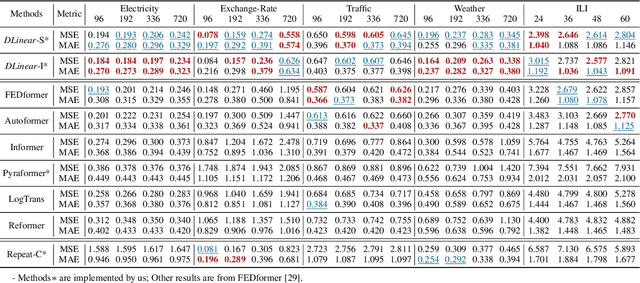
Recently, there has been a surge of Transformer-based solutions for the time series forecasting (TSF) task, especially for the challenging long-term TSF problem. Transformer architecture relies on self-attention mechanisms to effectively extract the semantic correlations between paired elements in a long sequence, which is permutation-invariant and anti-ordering to some extent. However, in time series modeling, we are to extract the temporal relations among an ordering set of continuous points. Consequently, whether Transformer-based techniques are the right solutions for long-term time series forecasting is an interesting problem to investigate, despite the performance improvements shown in these studies. In this work, we question the validity of Transformer-based TSF solutions. In their experiments, the compared (non-Transformer) baselines are mainly autoregressive forecasting solutions, which usually have a poor long-term prediction capability due to inevitable error accumulation effects. In contrast, we use an embarrassingly simple architecture named DLinear that conducts direct multi-step (DMS) forecasting for comparison. DLinear decomposes the time series into a trend and a remainder series and employs two one-layer linear networks to model these two series for the forecasting task. Surprisingly, it outperforms existing complex Transformer-based models in most cases by a large margin. Therefore, we conclude that the relatively higher long-term forecasting accuracy of Transformer-based TSF solutions shown in existing works has little to do with the temporal relation extraction capabilities of the Transformer architecture. Instead, it is mainly due to the non-autoregressive DMS forecasting strategy used in them. We hope this study also advocates revisiting the validity of Transformer-based solutions for other time series analysis tasks (e.g., anomaly detection) in the future.