 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Text-to-Image Generative Models: An Empirical Study on Human Image Synthesis
Paper and Code
Mar 08, 2024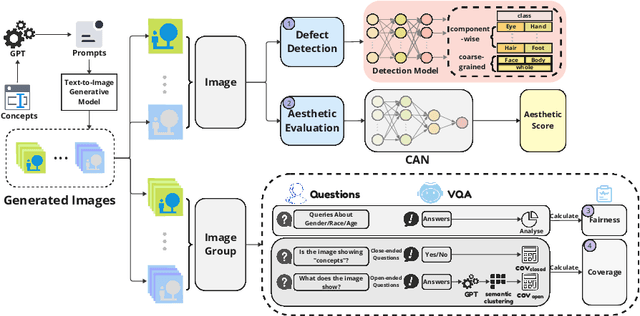
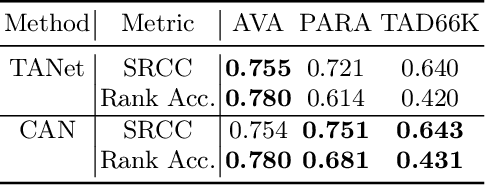
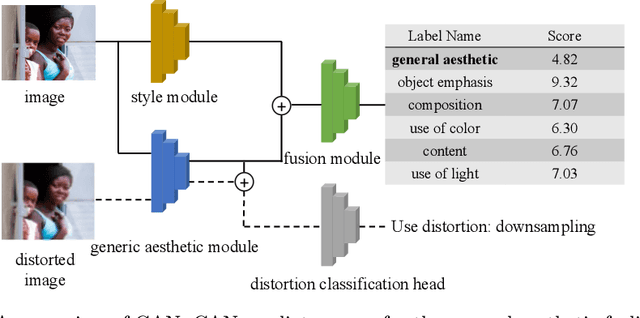
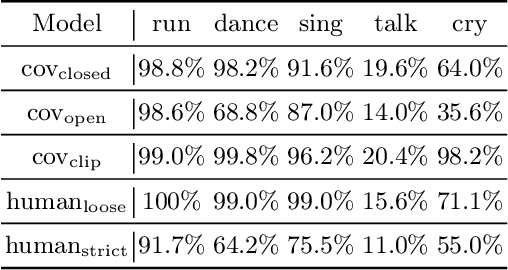
In this paper, we present an empirical study introducing a nuanced evaluation framework for text-to-image (T2I) generative models, applied to human image synthesis. Our framework categorizes evaluations into two distinct groups: first, focusing on image qualities such as aesthetics and realism, and second, examining text conditions through concept coverage and fairness. We introduce an innovative aesthetic score prediction model that assesses the visual appeal of generated images and unveils the first dataset marked with low-quality regions in generated human images to facilitate automatic defect detection. Our exploration into concept coverage probes the model's effectiveness in interpreting and rendering text-based concepts accurately, while our analysis of fairness reveals biases in model outputs, with an emphasis on gender, race, and age. While our study is grounded in human imagery, this dual-faceted approach is designed with the flexibility to be applicable to other forms of image generation, enhancing our understanding of generative models and paving the way to the next generation of more sophisticated, contextually aware, and ethically attuned generative models. We will release our code, the data used for evaluating generative models and the dataset annotated with defective areas soon.