 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Decoding for Verilog: Speed and Quality, All in One
Mar 18, 2025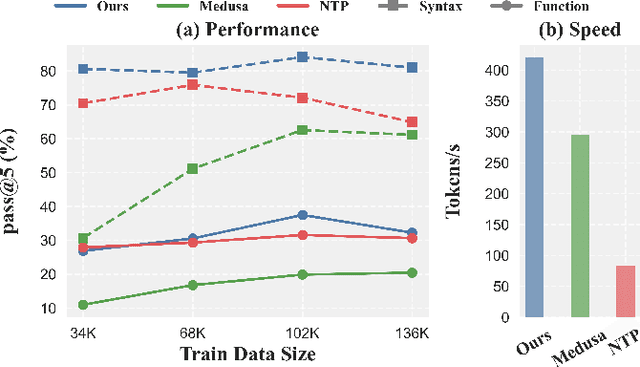
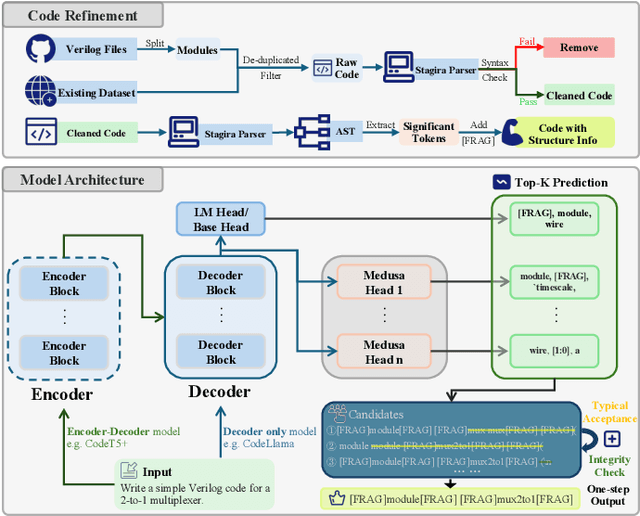
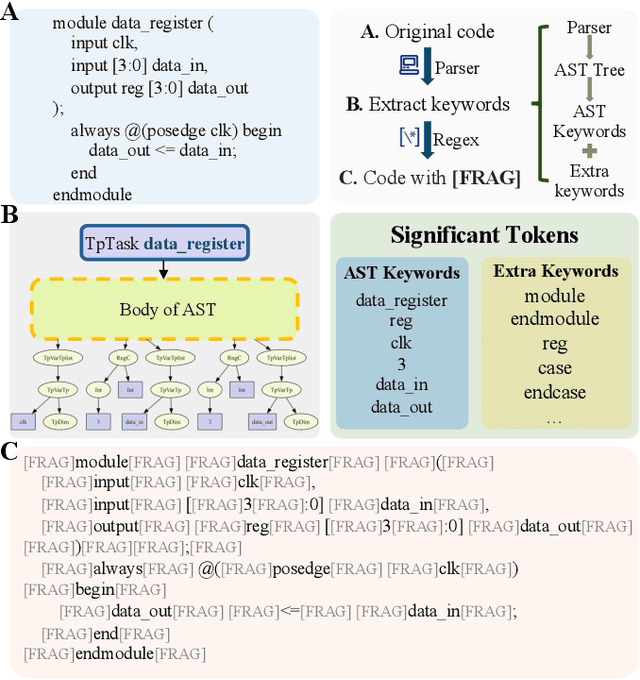
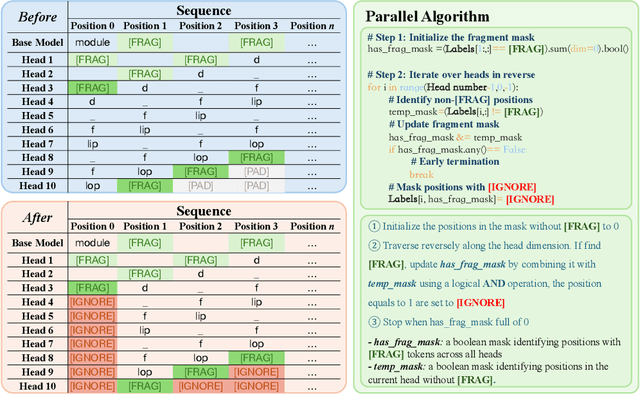
The rapid advancement of large language models (LLMs) has revolutionized code generation tasks across various programming languages. However, the unique characteristics of programming languages, particularly those like Verilog with specific syntax and lower representation in training datasets, pose significant challenges for conventional tokenization and decoding approaches. In this paper, we introduce a novel application of speculative decoding for Verilog code generation, showing that it can improve both inference speed and output quality, effectively achieving speed and quality all in one. Unlike standard LLM tokenization schemes, which often fragment meaningful code structures, our approach aligns decoding stops with syntactically significant tokens, making it easier for models to learn the token distribution. This refinement addresses inherent tokenization issues and enhances the model's ability to capture Verilog's logical constructs more effectively. Our experimental results show that our method achieves up to a 5.05x speedup in Verilog code generation and increases pass@10 functional accuracy on RTLLM by up to 17.19% compared to conventional training strategies. These findings highlight speculative decoding as a promising approach to bridge the quality gap in code generation for specialized programming languages.
DeepCircuitX: A Comprehensive Repository-Level Dataset for RTL Code Understanding, Generation, and PPA Analysis
Feb 25, 2025



This paper introduces DeepCircuitX, a comprehensive repository-level dataset designed to advance RTL (Register Transfer Level) code understanding, generation, and power-performance-area (PPA) analysis. Unlike existing datasets that are limited to either file-level RTL code or physical layout data, DeepCircuitX provides a holistic, multilevel resource that spans repository, file, module, and block-level RTL code. This structure enables more nuanced training and evaluation of large language models (LLMs) for RTL-specific tasks. DeepCircuitX is enriched with Chain of Thought (CoT) annotations, offering detailed descriptions of functionality and structure at multiple levels. These annotations enhance its utility for a wide range of tasks, including RTL code understanding, generation, and completion. Additionally, the dataset includes synthesized netlists and PPA metrics, facilitating early-stage design exploration and enabling accurate PPA prediction directly from RTL code. We demonstrate the dataset's effectiveness on various LLMs finetuned with our dataset and confirm the quality with human evaluations. Our results highlight DeepCircuitX as a critical resource for advancing RTL-focused machine learning applications in hardware design automation.Our data is available at https://zeju.gitbook.io/lcm-team.
DeepRTL: Bridging Verilog Understanding and Generation with a Unified Representation Model
Feb 20, 2025Recent advancements in large language models (LLMs) have shown significant potential for automating hardware description language (HDL) code generation from high-level natural language instructions. While fine-tuning has improved LLMs' performance in hardware design tasks, prior efforts have largely focused on Verilog generation, overlooking the equally critical task of Verilog understanding. Furthermore, existing models suffer from weak alignment between natural language descriptions and Verilog code, hindering the generation of high-quality, synthesizable designs. To address these issues, we present DeepRTL, a unified representation model that excels in both Verilog understanding and generation. Based on CodeT5+, DeepRTL is fine-tuned on a comprehensive dataset that aligns Verilog code with rich, multi-level natural language descriptions. We also introduce the first benchmark for Verilog understanding and take the initiative to apply embedding similarity and GPT Score to evaluate the models' understanding capabilities. These metrics capture semantic similarity more accurately than traditional methods like BLEU and ROUGE, which are limited to surface-level n-gram overlaps. By adapting curriculum learning to train DeepRTL, we enable it to significantly outperform GPT-4 in Verilog understanding tasks, while achieving performance on par with OpenAI's o1-preview model in Verilog generation tasks.
Artificial Intelligence Enhanced Digital Nucleic Acid Amplification Testing for Precision Medicine and Molecular Diagnostics
Jul 30, 2024



The precise quantification of nucleic acids is pivotal in molecular biology, underscored by the rising prominence of nucleic acid amplification tests (NAAT) in diagnosing infectious diseases and conducting genomic studies. This review examines recent advancements in digital Polymerase Chain Reaction (dPCR) and digital Loop-mediated Isothermal Amplification (dLAMP), which surpass the limitations of traditional NAAT by offering absolute quantification and enhanced sensitivity. In this review, we summarize the compelling advancements of dNNAT in addressing pressing public health issues, especially during the COVID-19 pandemic. Further, we explore the transformative role of artificial intelligence (AI) in enhancing dNAAT image analysis, which not only improves efficiency and accuracy but also addresses traditional constraints related to cost, complexity, and data interpretation. In encompassing the state-of-the-art (SOTA) development and potential of both software and hardware, the all-encompassing Point-of-Care Testing (POCT) systems cast new light on benefits including higher throughput, label-free detection, and expanded multiplex analyses. While acknowledging the enhancement of AI-enhanced dNAAT technology, this review aims to both fill critical gaps in the existing technologies through comparative assessments and offer a balanced perspective on the current trajectory, including attendant challenges and future directions. Leveraging AI, next-generation dPCR and dLAMP technologies promises integration into clinical practice, improving personalized medicine, real-time epidemic surveillance, and global diagnostic accessibility.
Evaluating Text-to-Image Generative Models: An Empirical Study on Human Image Synthesis
Mar 08, 2024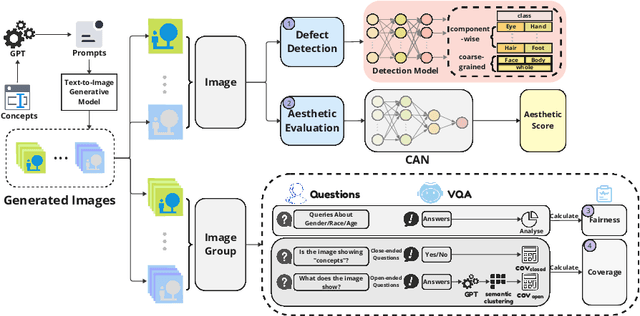
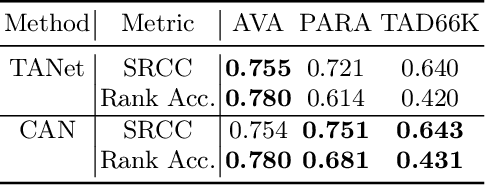
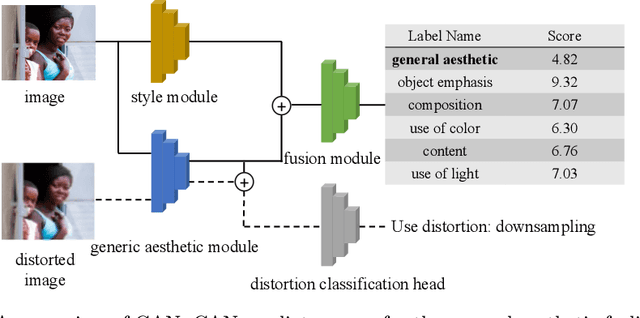
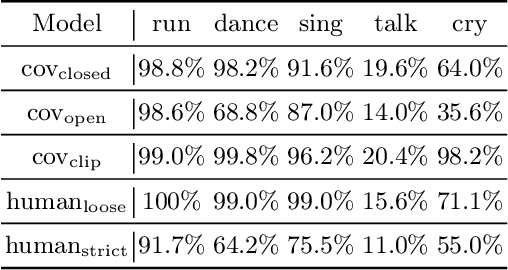
In this paper, we present an empirical study introducing a nuanced evaluation framework for text-to-image (T2I) generative models, applied to human image synthesis. Our framework categorizes evaluations into two distinct groups: first, focusing on image qualities such as aesthetics and realism, and second, examining text conditions through concept coverage and fairness. We introduce an innovative aesthetic score prediction model that assesses the visual appeal of generated images and unveils the first dataset marked with low-quality regions in generated human images to facilitate automatic defect detection. Our exploration into concept coverage probes the model's effectiveness in interpreting and rendering text-based concepts accurately, while our analysis of fairness reveals biases in model outputs, with an emphasis on gender, race, and age. While our study is grounded in human imagery, this dual-faceted approach is designed with the flexibility to be applicable to other forms of image generation, enhancing our understanding of generative models and paving the way to the next generation of more sophisticated, contextually aware, and ethically attuned generative models. We will release our code, the data used for evaluating generative models and the dataset annotated with defective areas soon.