 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBCIR: Balancing Cross-Modal Focuses in Composed Image Retrieval
Mar 12, 2026Composed image retrieval (CIR) requires multi-modal models to jointly reason over visual content and semantic modifications presented in text-image input pairs. While current CIR models achieve strong performance on common benchmark cases, their accuracies often degrades in more challenging scenarios where negative candidates are semantically aligned with the query image or text. In this paper, we attribute this degradation to focus imbalances, where models disproportionately attend to one modality while neglecting the other. To validate this claim, we propose FBCIR, a multi-modal focus interpretation method that identifies the most crucial visual and textual input components to a model's retrieval decisions. Using FBCIR, we report that focus imbalances are prevalent in existing CIR models, especially under hard negative settings. Building on the analyses, we further propose a CIR data augmentation workflow that facilitates existing CIR datasets with curated hard negatives designed to encourage balanced cross-modal reasoning. Extensive experiments across multiple CIR models demonstrate that the proposed augmentation consistently improves performance in challenging cases, while maintaining their capabilities on standard benchmarks. Together, our interpretation method and data augmentation workflow provide a new perspective on CIR model diagnosis and robustness improvements.
\textit{FocaLogic}: Logic-Based Interpretation of Visual Model Decisions
Jan 17, 2026Interpretability of modern visual models is crucial, particularly in high-stakes applications. However, existing interpretability methods typically suffer from either reliance on white-box model access or insufficient quantitative rigor. To address these limitations, we introduce FocaLogic, a novel model-agnostic framework designed to interpret and quantify visual model decision-making through logic-based representations. FocaLogic identifies minimal interpretable subsets of visual regions-termed visual focuses-that decisively influence model predictions. It translates these visual focuses into precise and compact logical expressions, enabling transparent and structured interpretations. Additionally, we propose a suite of quantitative metrics, including focus precision, recall, and divergence, to objectively evaluate model behavior across diverse scenarios. Empirical analyses demonstrate FocaLogic's capability to uncover critical insights such as training-induced concentration, increasing focus accuracy through generalization, and anomalous focuses under biases and adversarial attacks. Overall, FocaLogic provides a systematic, scalable, and quantitative solution for interpreting visual models.
Concept-SAE: Active Causal Probing of Visual Model Behavior
Sep 26, 2025Standard Sparse Autoencoders (SAEs) excel at discovering a dictionary of a model's learned features, offering a powerful observational lens. However, the ambiguous and ungrounded nature of these features makes them unreliable instruments for the active, causal probing of model behavior. To solve this, we introduce Concept-SAE, a framework that forges semantically grounded concept tokens through a novel hybrid disentanglement strategy. We first quantitatively demonstrate that our dual-supervision approach produces tokens that are remarkably faithful and spatially localized, outperforming alternative methods in disentanglement. This validated fidelity enables two critical applications: (1) we probe the causal link between internal concepts and predictions via direct intervention, and (2) we probe the model's failure modes by systematically localizing adversarial vulnerabilities to specific layers. Concept-SAE provides a validated blueprint for moving beyond correlational interpretation to the mechanistic, causal probing of model behavior.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
DebugAgent: Efficient and Interpretable Error Slice Discovery for Comprehensive Model Debugging
Jan 28, 2025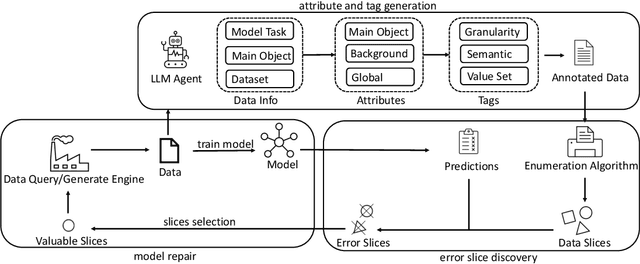


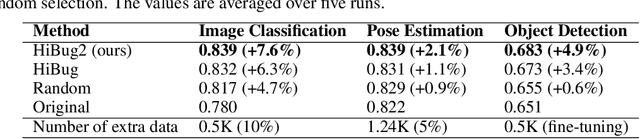
Despite the significant success of deep learning models in computer vision, they often exhibit systematic failures on specific data subsets, known as error slices. Identifying and mitigating these error slices is crucial to enhancing model robustness and reliability in real-world scenarios. In this paper, we introduce DebugAgent, an automated framework for error slice discovery and model repair. DebugAgent first generates task-specific visual attributes to highlight instances prone to errors through an interpretable and structured process. It then employs an efficient slice enumeration algorithm to systematically identify error slices, overcoming the combinatorial challenges that arise during slice exploration. Additionally, DebugAgent extends its capabilities by predicting error slices beyond the validation set, addressing a key limitation of prior approaches. Extensive experiments across multiple domains, including image classification, pose estimation, and object detection - show that DebugAgent not only improves the coherence and precision of identified error slices but also significantly enhances the model repair capabilities.
Multichannel consecutive data cross-extraction with 1DCNN-attention for diagnosis of power transformer
Oct 11, 2023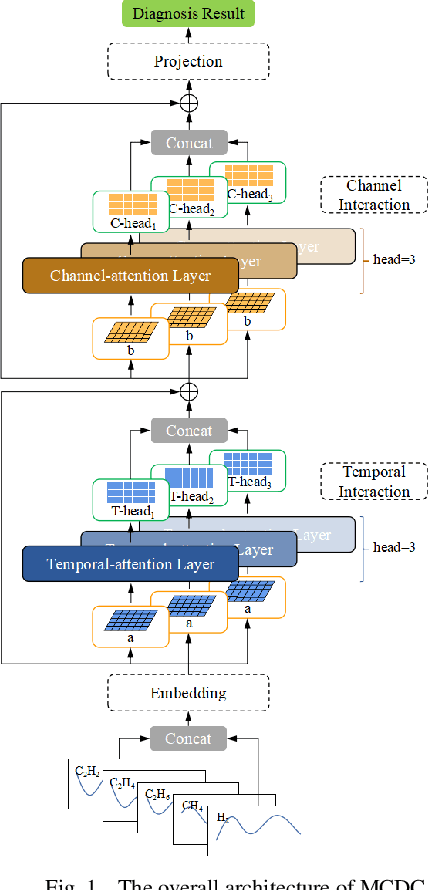



Power transformer plays a critical role in grid infrastructure, and its diagnosis is paramount for maintaining stable operation. However, the current methods for transformer diagnosis focus on discrete dissolved gas analysis, neglecting deep feature extraction of multichannel consecutive data. The unutilized sequential data contains the significant temporal information reflecting the transformer condition. In light of this, the structure of multichannel consecutive data cross-extraction (MCDC) is proposed in this article in order to comprehensively exploit the intrinsic characteristic and evaluate the states of transformer. Moreover, for the better accommodation in scenario of transformer diagnosis, one dimensional convolution neural network attention (1DCNN-attention) mechanism is introduced and offers a more efficient solution given the simplified spatial complexity. Finally, the effectiveness of MCDC and the superior generalization ability, compared with other algorithms, are validated in experiments conducted on a dataset collected from real operation cases of power transformer. Additionally, the better stability of 1DCNN-attention has also been certified.
DiffGuard: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
Aug 16, 2023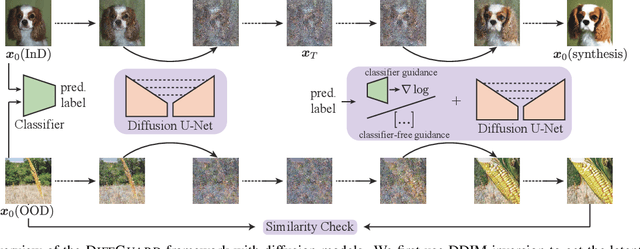
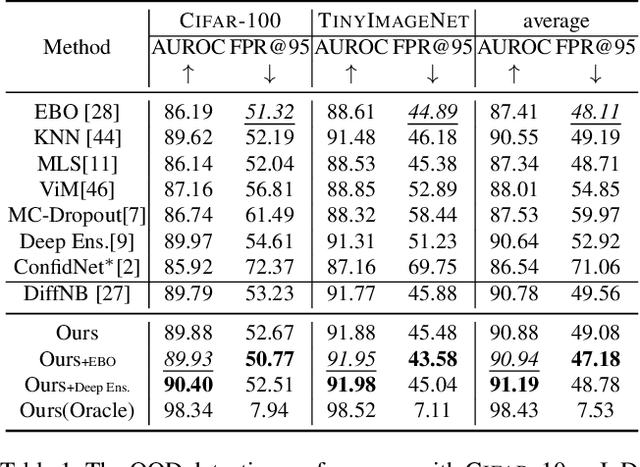
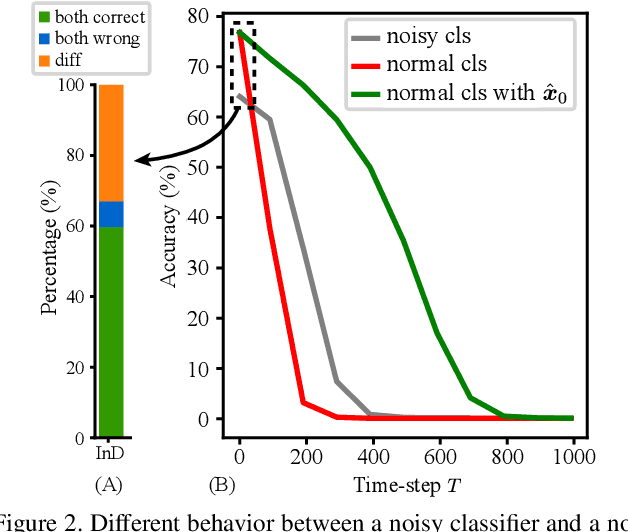
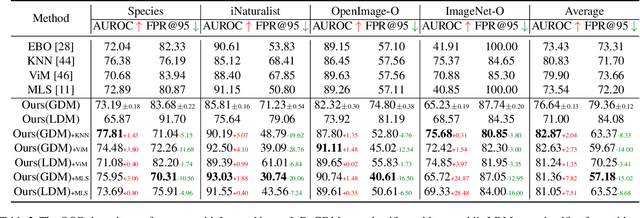
Given a classifier, the inherent property of semantic Out-of-Distribution (OOD) samples is that their contents differ from all legal classes in terms of semantics, namely semantic mismatch. There is a recent work that directly applies it to OOD detection, which employs a conditional Generative Adversarial Network (cGAN) to enlarge semantic mismatch in the image space. While achieving remarkable OOD detection performance on small datasets, it is not applicable to ImageNet-scale datasets due to the difficulty in training cGANs with both input images and labels as conditions. As diffusion models are much easier to train and amenable to various conditions compared to cGANs, in this work, we propose to directly use pre-trained diffusion models for semantic mismatch-guided OOD detection, named DiffGuard. Specifically, given an OOD input image and the predicted label from the classifier, we try to enlarge the semantic difference between the reconstructed OOD image under these conditions and the original input image. We also present several test-time techniques to further strengthen such differences. Experimental results show that DiffGuard is effective on both Cifar-10 and hard cases of the large-scale ImageNet, and it can be easily combined with existing OOD detection techniques to achieve state-of-the-art OOD detection results.
HumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation
Apr 09, 2023
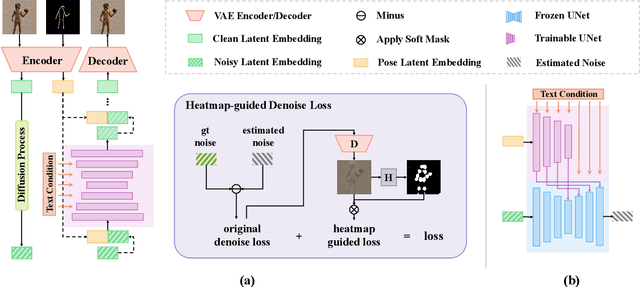
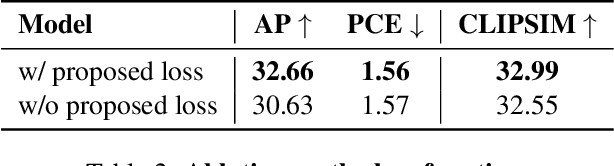
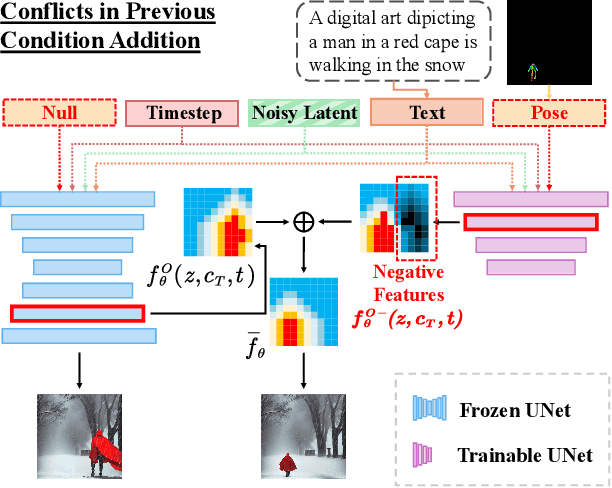
Controllable human image generation (HIG) has numerous real-life applications. State-of-the-art solutions, such as ControlNet and T2I-Adapter, introduce an additional learnable branch on top of the frozen pre-trained stable diffusion (SD) model, which can enforce various conditions, including skeleton guidance of HIG. While such a plug-and-play approach is appealing, the inevitable and uncertain conflicts between the original images produced from the frozen SD branch and the given condition incur significant challenges for the learnable branch, which essentially conducts image feature editing for condition enforcement. In this work, we propose a native skeleton-guided diffusion model for controllable HIG called HumanSD. Instead of performing image editing with dual-branch diffusion, we fine-tune the original SD model using a novel heatmap-guided denoising loss. This strategy effectively and efficiently strengthens the given skeleton condition during model training while mitigating the catastrophic forgetting effects. HumanSD is fine-tuned on the assembly of three large-scale human-centric datasets with text-image-pose information, two of which are established in this work. As shown in Figure 1, HumanSD outperforms ControlNet in terms of accurate pose control and image quality, particularly when the given skeleton guidance is sophisticated.
Blurring Fools the Network -- Adversarial Attacks by Feature Peak Suppression and Gaussian Blurring
Dec 21, 2020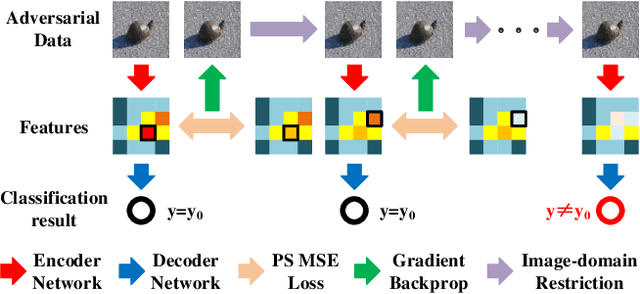
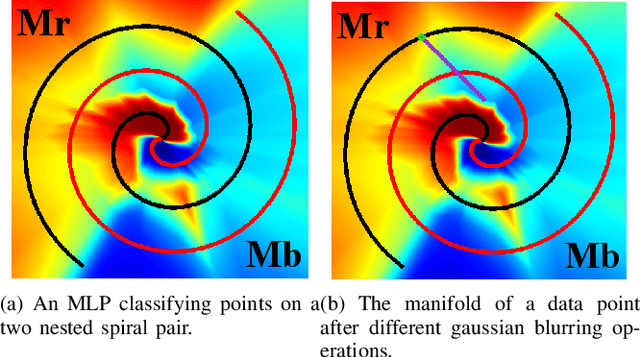

Existing pixel-level adversarial attacks on neural networks may be deficient in real scenarios, since pixel-level changes on the data cannot be fully delivered to the neural network after camera capture and multiple image preprocessing steps. In contrast, in this paper, we argue from another perspective that gaussian blurring, a common technique of image preprocessing, can be aggressive itself in specific occasions, thus exposing the network to real-world adversarial attacks. We first propose an adversarial attack demo named peak suppression (PS) by suppressing the values of peak elements in the features of the data. Based on the blurring spirit of PS, we further apply gaussian blurring to the data, to investigate the potential influence and threats of gaussian blurring to performance of the network. Experiment results show that PS and well-designed gaussian blurring can form adversarial attacks that completely change classification results of a well-trained target network. With the strong physical significance and wide applications of gaussian blurring, the proposed approach will also be capable of conducting real world attacks.
Amplifying the Anterior-Posterior Difference via Data Enhancement -- A More Robust Deep Monocular Orientation Estimation Solution
Dec 21, 2020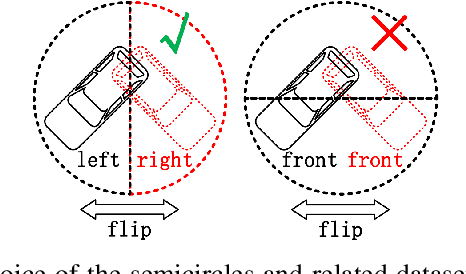
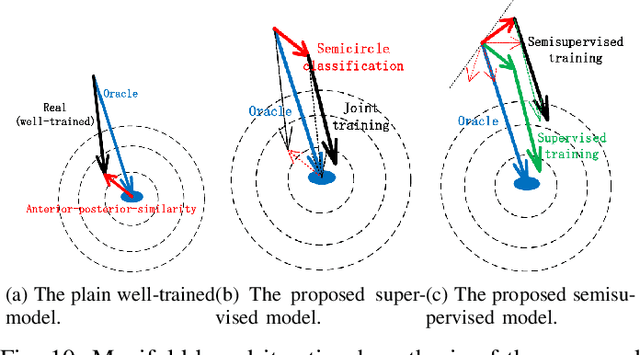
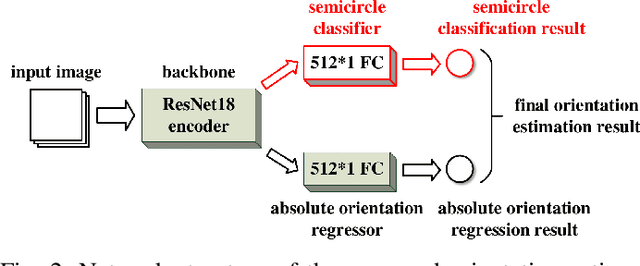
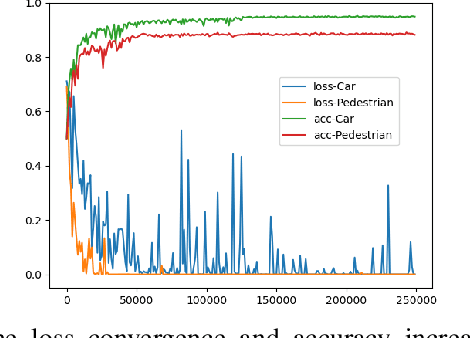
Existing deep-learning based monocular orientation estimation algorithms faces the problem of confusion between the anterior and posterior parts of the objects, caused by the feature similarity of such parts in typical objects in traffic scenes such as cars and pedestrians. While difficult to solve, the problem may lead to serious orientation estimation errors, and pose threats to the upcoming decision making process of the ego vehicle, since the predicted tracks of objects may have directions opposite to ground truths. In this paper, we mitigate this problem by proposing a pretraining method. The method focuses on predicting the left/right semicircle in which the orientation of the object is located. The trained semicircle prediction model is then integrated into the orientation angle estimation model which predicts a value in range $[0, \pi]$. Experiment results show that the proposed semicircle prediction enhances the accuracy of orientation estimation, and mitigates the problem stated above. With the proposed method, a backbone achieves similar state-of-the-art orientation estimation performance to existing approaches with well-designed network structures.