 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation
Paper and Code

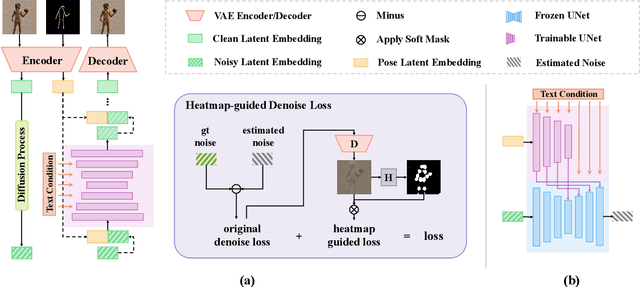
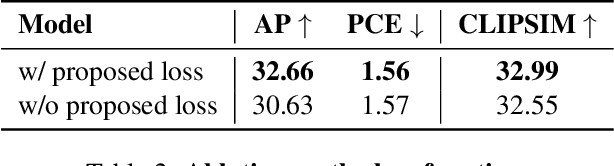
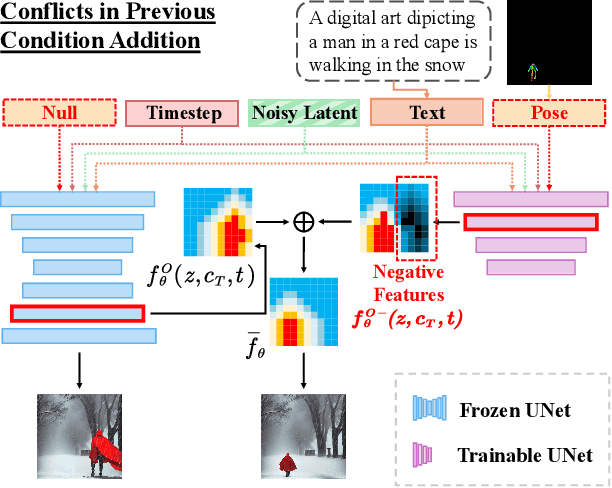
Controllable human image generation (HIG) has numerous real-life applications. State-of-the-art solutions, such as ControlNet and T2I-Adapter, introduce an additional learnable branch on top of the frozen pre-trained stable diffusion (SD) model, which can enforce various conditions, including skeleton guidance of HIG. While such a plug-and-play approach is appealing, the inevitable and uncertain conflicts between the original images produced from the frozen SD branch and the given condition incur significant challenges for the learnable branch, which essentially conducts image feature editing for condition enforcement. In this work, we propose a native skeleton-guided diffusion model for controllable HIG called HumanSD. Instead of performing image editing with dual-branch diffusion, we fine-tune the original SD model using a novel heatmap-guided denoising loss. This strategy effectively and efficiently strengthens the given skeleton condition during model training while mitigating the catastrophic forgetting effects. HumanSD is fine-tuned on the assembly of three large-scale human-centric datasets with text-image-pose information, two of which are established in this work. As shown in Figure 1, HumanSD outperforms ControlNet in terms of accurate pose control and image quality, particularly when the given skeleton guidance is sophisticated.