 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarXFormer: Robust Object Detection via Cross-Dimension Fusion of 4D Radar Spectra and Images for Autonomous Driving
Mar 16, 2026Reliable perception is essential for autonomous driving systems to operate safely under diverse real-world traffic conditions. However, camera- and LiDAR-based perception systems suffer from performance degradation under adverse weather and lighting conditions, limiting their robustness and large-scale deployment in intelligent transportation systems. Radar-vision fusion provides a promising alternative by combining the environmental robustness and cost efficiency of millimeter-wave (mmWave) radar with the rich semantic information captured by cameras. Nevertheless, conventional 3D radar measurements lack height resolution and remain highly sparse, while emerging 4D mmWave radar introduces elevation information but also brings challenges such as signal noise and large data volume. To address these issues, this paper proposes RadarXFormer, a 3D object detection framework that enables efficient cross-modal fusion between 4D radar spectra and RGB images. Instead of relying on sparse radar point clouds, RadarXFormer directly leverages raw radar spectra and constructs an efficient 3D representation that reduces data volume while preserving complete 3D spatial information. The "X" highlights the proposed cross-dimension (3D-2D) fusion mechanism, in which multi-scale 3D spherical radar feature cubes are fused with complementary 2D image feature maps. Experiments on the K-Radar dataset demonstrate improved detection accuracy and robustness under challenging conditions while maintaining real-time inference capability.
Weather-Magician: Reconstruction and Rendering Framework for 4D Weather Synthesis In Real Time
May 26, 2025For tasks such as urban digital twins, VR/AR/game scene design, or creating synthetic films, the traditional industrial approach often involves manually modeling scenes and using various rendering engines to complete the rendering process. This approach typically requires high labor costs and hardware demands, and can result in poor quality when replicating complex real-world scenes. A more efficient approach is to use data from captured real-world scenes, then apply reconstruction and rendering algorithms to quickly recreate the authentic scene. However, current algorithms are unable to effectively reconstruct and render real-world weather effects. To address this, we propose a framework based on gaussian splatting, that can reconstruct real scenes and render them under synthesized 4D weather effects. Our work can simulate various common weather effects by applying Gaussians modeling and rendering techniques. It supports continuous dynamic weather changes and can easily control the details of the effects. Additionally, our work has low hardware requirements and achieves real-time rendering performance. The result demos can be accessed on our project homepage: weathermagician.github.io
Depth-aware Fusion Method based on Image and 4D Radar Spectrum for 3D Object Detection
Feb 21, 2025Safety and reliability are crucial for the public acceptance of autonomous driving. To ensure accurate and reliable environmental perception, intelligent vehicles must exhibit accuracy and robustness in various environments. Millimeter-wave radar, known for its high penetration capability, can operate effectively in adverse weather conditions such as rain, snow, and fog. Traditional 3D millimeter-wave radars can only provide range, Doppler, and azimuth information for objects. Although the recent emergence of 4D millimeter-wave radars has added elevation resolution, the radar point clouds remain sparse due to Constant False Alarm Rate (CFAR) operations. In contrast, cameras offer rich semantic details but are sensitive to lighting and weather conditions. Hence, this paper leverages these two highly complementary and cost-effective sensors, 4D millimeter-wave radar and camera. By integrating 4D radar spectra with depth-aware camera images and employing attention mechanisms, we fuse texture-rich images with depth-rich radar data in the Bird's Eye View (BEV) perspective, enhancing 3D object detection. Additionally, we propose using GAN-based networks to generate depth images from radar spectra in the absence of depth sensors, further improving detection accuracy.
AMFD: Distillation via Adaptive Multimodal Fusion for Multispectral Pedestrian Detection
May 21, 2024
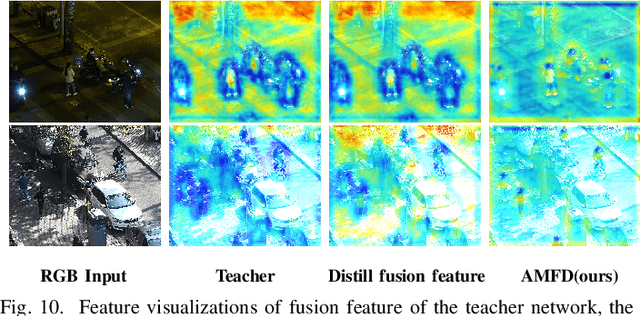


Multispectral pedestrian detection has been shown to be effective in improving performance within complex illumination scenarios. However, prevalent double-stream networks in multispectral detection employ two separate feature extraction branches for multi-modal data, leading to nearly double the inference time compared to single-stream networks utilizing only one feature extraction branch. This increased inference time has hindered the widespread employment of multispectral pedestrian detection in embedded devices for autonomous systems. To address this limitation, various knowledge distillation methods have been proposed. However, traditional distillation methods focus only on the fusion features and ignore the large amount of information in the original multi-modal features, thereby restricting the student network's performance. To tackle the challenge, we introduce the Adaptive Modal Fusion Distillation (AMFD) framework, which can fully utilize the original modal features of the teacher network. Specifically, a Modal Extraction Alignment (MEA) module is utilized to derive learning weights for student networks, integrating focal and global attention mechanisms. This methodology enables the student network to acquire optimal fusion strategies independent from that of teacher network without necessitating an additional feature fusion module. Furthermore, we present the SMOD dataset, a well-aligned challenging multispectral dataset for detection. Extensive experiments on the challenging KAIST, LLVIP and SMOD datasets are conducted to validate the effectiveness of AMFD. The results demonstrate that our method outperforms existing state-of-the-art methods in both reducing log-average Miss Rate and improving mean Average Precision. The code is available at https://github.com/bigD233/AMFD.git.
LESS-Map: Lightweight and Evolving Semantic Map in Parking Lots for Long-term Self-Localization
Oct 11, 2023



Precise and long-term stable localization is essential in parking lots for tasks like autonomous driving or autonomous valet parking, \textit{etc}. Existing methods rely on a fixed and memory-inefficient map, which lacks robust data association approaches. And it is not suitable for precise localization or long-term map maintenance. In this paper, we propose a novel mapping, localization, and map update system based on ground semantic features, utilizing low-cost cameras. We present a precise and lightweight parameterization method to establish improved data association and achieve accurate localization at centimeter-level. Furthermore, we propose a novel map update approach by implementing high-quality data association for parameterized semantic features, allowing continuous map update and refinement during re-localization, while maintaining centimeter-level accuracy. We validate the performance of the proposed method in real-world experiments and compare it against state-of-the-art algorithms. The proposed method achieves an average accuracy improvement of 5cm during the registration process. The generated maps consume only a compact size of 450 KB/km and remain adaptable to evolving environments through continuous update.
SUNet: Scale-aware Unified Network for Panoptic Segmentation
Sep 07, 2022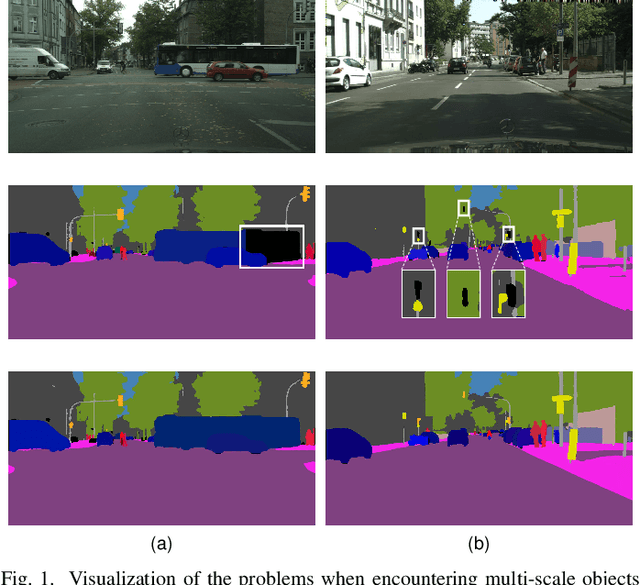
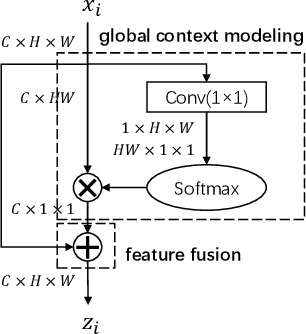
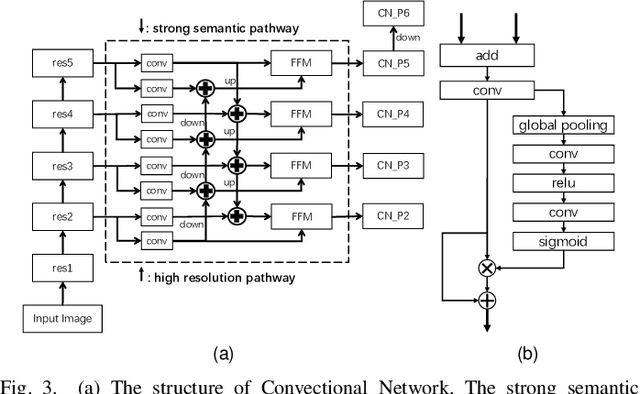
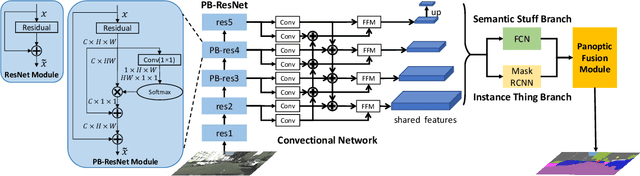
Panoptic segmentation combines the advantages of semantic and instance segmentation, which can provide both pixel-level and instance-level environmental perception information for intelligent vehicles. However, it is challenged with segmenting objects of various scales, especially on extremely large and small ones. In this work, we propose two lightweight modules to mitigate this problem. First, Pixel-relation Block is designed to model global context information for large-scale things, which is based on a query-independent formulation and brings small parameter increments. Then, Convectional Network is constructed to collect extra high-resolution information for small-scale stuff, supplying more appropriate semantic features for the downstream segmentation branches. Based on these two modules, we present an end-to-end Scale-aware Unified Network (SUNet), which is more adaptable to multi-scale objects. Extensive experiments on Cityscapes and COCO demonstrate the effectiveness of the proposed methods.
Threshold-adaptive Unsupervised Focal Loss for Domain Adaptation of Semantic Segmentation
Aug 23, 2022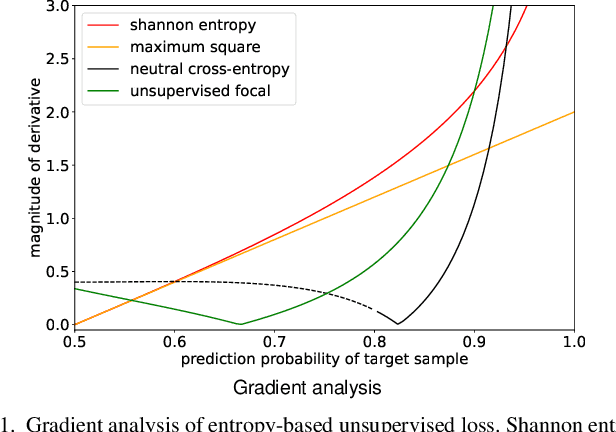
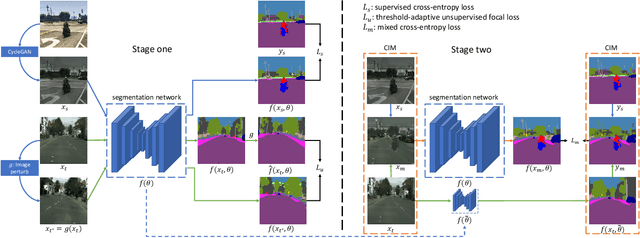
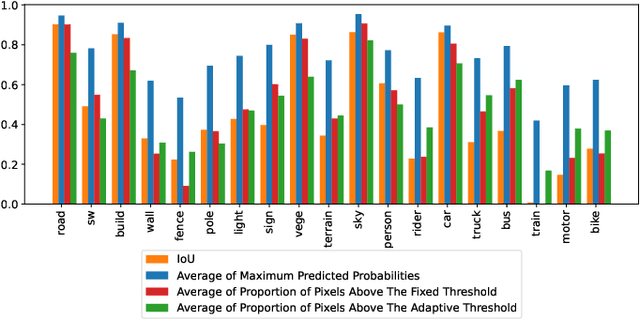

Semantic segmentation is an important task for intelligent vehicles to understand the environment. Current deep learning methods require large amounts of labeled data for training. Manual annotation is expensive, while simulators can provide accurate annotations. However, the performance of the semantic segmentation model trained with the data of the simulator will significantly decrease when applied in the actual scene. Unsupervised domain adaptation (UDA) for semantic segmentation has recently gained increasing research attention, aiming to reduce the domain gap and improve the performance on the target domain. In this paper, we propose a novel two-stage entropy-based UDA method for semantic segmentation. In stage one, we design a threshold-adaptative unsupervised focal loss to regularize the prediction in the target domain, which has a mild gradient neutralization mechanism and mitigates the problem that hard samples are barely optimized in entropy-based methods. In stage two, we introduce a data augmentation method named cross-domain image mixing (CIM) to bridge the semantic knowledge from two domains. Our method achieves state-of-the-art 58.4% and 59.6% mIoUs on SYNTHIA-to-Cityscapes and GTA5-to-Cityscapes using DeepLabV2 and competitive performance using the lightweight BiSeNet.
Map-Enhanced Ego-Lane Detection in the Missing Feature Scenarios
Apr 04, 2020



As one of the most important tasks in autonomous driving systems, ego-lane detection has been extensively studied and has achieved impressive results in many scenarios. However, ego-lane detection in the missing feature scenarios is still an unsolved problem. To address this problem, previous methods have been devoted to proposing more complicated feature extraction algorithms, but they are very time-consuming and cannot deal with extreme scenarios. Different from others, this paper exploits prior knowledge contained in digital maps, which has a strong capability to enhance the performance of detection algorithms. Specifically, we employ the road shape extracted from OpenStreetMap as lane model, which is highly consistent with the real lane shape and irrelevant to lane features. In this way, only a few lane features are needed to eliminate the position error between the road shape and the real lane, and a search-based optimization algorithm is proposed. Experiments show that the proposed method can be applied to various scenarios and can run in real-time at a frequency of 20 Hz. At the same time, we evaluated the proposed method on the public KITTI Lane dataset where it achieves state-of-the-art performance. Moreover, our code will be open source after publication.
Monocular Pedestrian Orientation Estimation Based on Deep 2D-3D Feedforward
Sep 24, 2019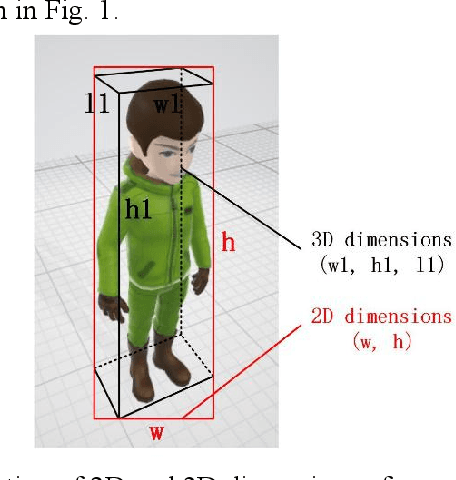

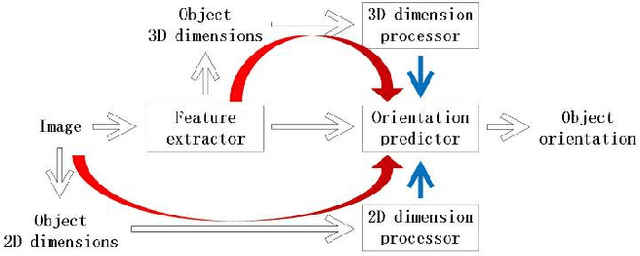
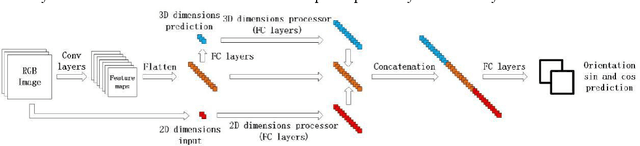
Accurate pedestrian orientation estimation of autonomous driving helps the ego vehicle obtain the intentions of pedestrians in the related environment, which are the base of safety measures such as collision avoidance and prewarning. However, because of relatively small sizes and high-level deformation of pedestrians, common pedestrian orientation estimation models fail to extract sufficient and comprehensive information from them, thus having their performance restricted, especially monocular ones which fail to obtain depth information of objects and related environment. In this paper, a novel monocular pedestrian orientation estimation model, called FFNet, is proposed. Apart from camera captures, the model adds the 2D and 3D dimensions of pedestrians as two other inputs according to the logic relationship between orientation and them. The 2D and 3D dimensions of pedestrians are determined from the camera captures and further utilized through two feedforward links connected to the orientation estimator. The feedforward links strengthen the logicality and interpretability of the network structure of the proposed model. Experiments show that the proposed model has at least 1.72% AOS increase than most state-of-the-art models after identical training processes. The model also has competitive results in orientation estimation evaluation on KITTI dataset.
Joint Calibration of Panoramic Camera and Lidar Based on Supervised Learning
Sep 13, 2017In view of contemporary panoramic camera-laser scanner system, the traditional calibration method is not suitable for panoramic cameras whose imaging model is extremely nonlinear. The method based on statistical optimization has the disadvantage that the requirement of the number of laser scanner's channels is relatively high. Calibration equipments with extreme accuracy for panoramic camera-laser scanner system are costly. Facing all these in the calibration of panoramic camera-laser scanner system, a method based on supervised learning is proposed. Firstly, corresponding feature points of panoramic images and point clouds are gained to generate the training dataset by designing a round calibration object. Furthermore, the traditional calibration problem is transformed into a multiple nonlinear regression optimization problem by designing a supervised learning network with preprocessing of the panoramic imaging model. Back propagation algorithm is utilized to regress the rotation and translation matrix with high accuracy. Experimental results show that this method can quickly regress the calibration parameters and the accuracy is better than the traditional calibration method and the method based on statistical optimization. The calibration accuracy of this method is really high, and it is more highly-automated.