 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrigReason: Trigger-Based Collaboration between Small and Large Reasoning Models
Apr 16, 2026Large Reasoning Models (LRMs) achieve strong performance on complex tasks through extended chains of thought but suffer from high inference latency due to autoregressive reasoning. Recent work explores using Small Reasoning Models (SRMs) to accelerate LRM inference. In this paper, we systematically characterize the capability boundaries of SRMs and identify three common types of reasoning risks: (1) path divergence, where SRMs lack the strategic ability to construct an initial plan, causing reasoning to deviate from the most probable path; (2) cognitive overload, where SRMs fail to solve particularly difficult steps; and (3) recovery inability, where SRMs lack robust self-reflection and error correction mechanisms. To address these challenges, we propose TrigReason, a trigger-based collaborative reasoning framework that replaces continuous polling with selective intervention. TrigReason delegates most reasoning to the SRM and activates LRM intervention only when necessary-during initial strategic planning (strategic priming trigger), upon detecting extraordinary overconfidence (cognitive offload trigger), or when reasoning falls into unproductive loops (intervention request trigger). The evaluation results on AIME24, AIME25, and GPQA-D indicate that TrigReason matches the accuracy of full LRMs and SpecReason, while offloading 1.70x - 4.79x more reasoning steps to SRMs. Under edge-cloud conditions, TrigReason reduces latency by 43.9\% and API cost by 73.3\%. Our code is available at \href{https://github.com/QQQ-yi/TrigReason}{https://github.com/QQQ-yi/TrigReason}
LifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Map-Enhanced Ego-Lane Detection in the Missing Feature Scenarios
Apr 04, 2020



As one of the most important tasks in autonomous driving systems, ego-lane detection has been extensively studied and has achieved impressive results in many scenarios. However, ego-lane detection in the missing feature scenarios is still an unsolved problem. To address this problem, previous methods have been devoted to proposing more complicated feature extraction algorithms, but they are very time-consuming and cannot deal with extreme scenarios. Different from others, this paper exploits prior knowledge contained in digital maps, which has a strong capability to enhance the performance of detection algorithms. Specifically, we employ the road shape extracted from OpenStreetMap as lane model, which is highly consistent with the real lane shape and irrelevant to lane features. In this way, only a few lane features are needed to eliminate the position error between the road shape and the real lane, and a search-based optimization algorithm is proposed. Experiments show that the proposed method can be applied to various scenarios and can run in real-time at a frequency of 20 Hz. At the same time, we evaluated the proposed method on the public KITTI Lane dataset where it achieves state-of-the-art performance. Moreover, our code will be open source after publication.
Fast and Accurate, Convolutional Neural Network Based Approach for Object Detection from UAV
Aug 16, 2018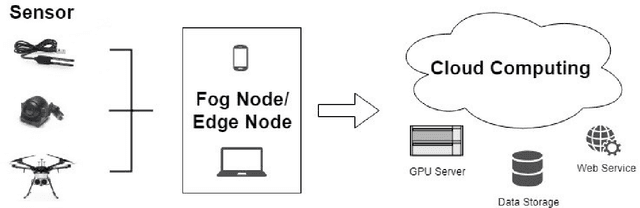
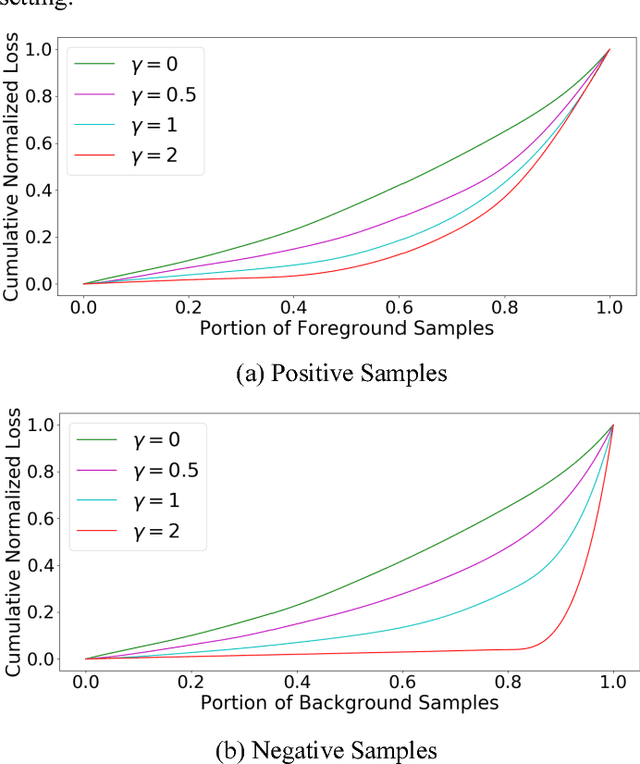

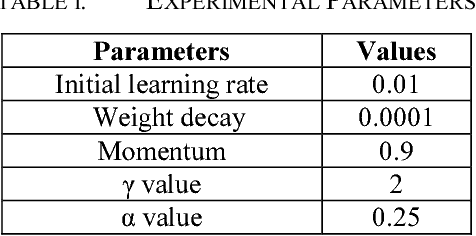
The ever-growing interest witnessed in the acquisition and development of unmanned aerial vehicles (UAVs), commonly known as drones in the past few years, has brought generation of a very promising and effective technology. Because of their characteristic of small size and fast deployment, UAVs have shown their effectiveness in collecting data over unreachable areas and restricted coverage zones. Moreover, their flexible-defined capacity enables them to collect information with a very high level of detail, leading to high resolution images. UAVs mainly served in military scenario. However, in the last decade, they have being broadly adopted in civilian applications as well. The task of aerial surveillance and situation awareness is usually completed by integrating intelligence, surveillance, observation, and navigation systems, all interacting in the same operational framework. To build this capability, UAV's are well suited tools that can be equipped with a wide variety of sensors, such as cameras or radars. Deep learning has been widely recognized as a prominent approach in different computer vision applications. Specifically, one-stage object detector and two-stage object detector are regarded as the most important two groups of Convolutional Neural Network based object detection methods. One-stage object detector could usually outperform two-stage object detector in speed; however, it normally trails in detection accuracy, compared with two-stage object detectors. In this study, focal loss based RetinaNet, which works as one-stage object detector, is utilized to be able to well match the speed of regular one-stage detectors and also defeat two-stage detectors in accuracy, for UAV based object detection. State-of-the-art performance result has been showed on the UAV captured image dataset-Stanford Drone Dataset (SDD).
Focal Loss Dense Detector for Vehicle Surveillance
Mar 03, 2018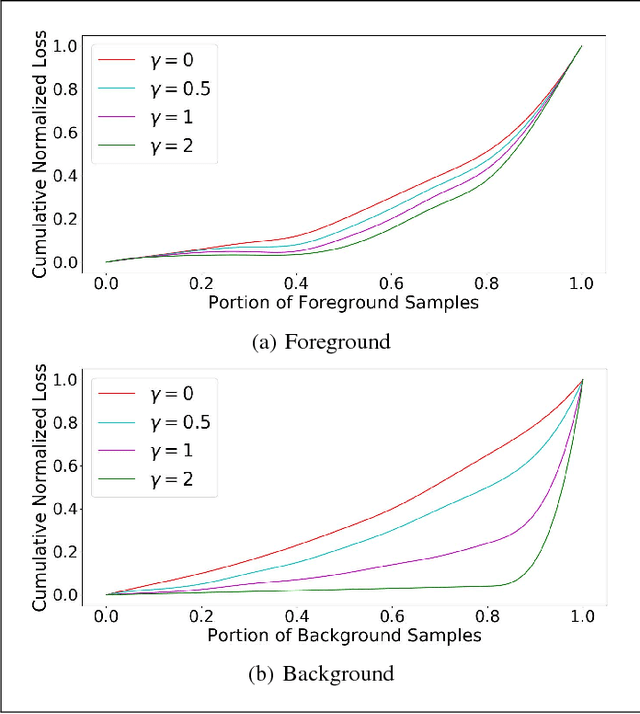
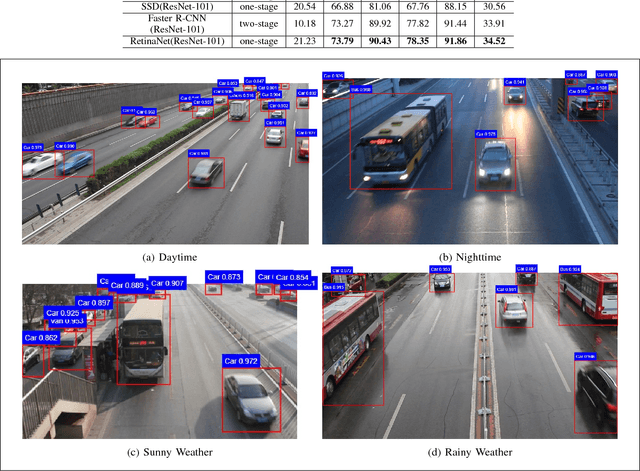
Deep learning has been widely recognized as a promising approach in different computer vision applications. Specifically, one-stage object detector and two-stage object detector are regarded as the most important two groups of Convolutional Neural Network based object detection methods. One-stage object detector could usually outperform two-stage object detector in speed; However, it normally trails in detection accuracy, compared with two-stage object detectors. In this study, focal loss based RetinaNet, which works as one-stage object detector, is utilized to be able to well match the speed of regular one-stage detectors and also defeat two-stage detectors in accuracy, for vehicle detection. State-of-the-art performance result has been showed on the DETRAC vehicle dataset.