 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models
Jul 24, 2024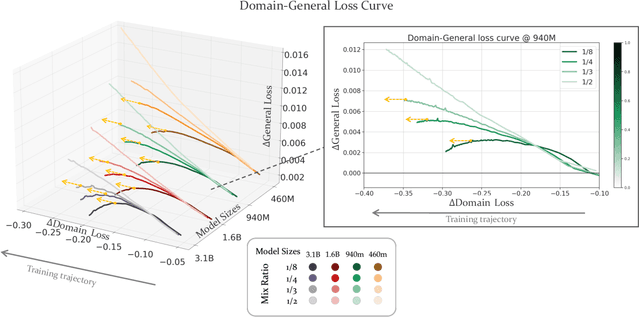
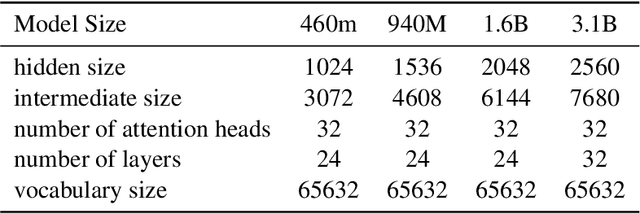
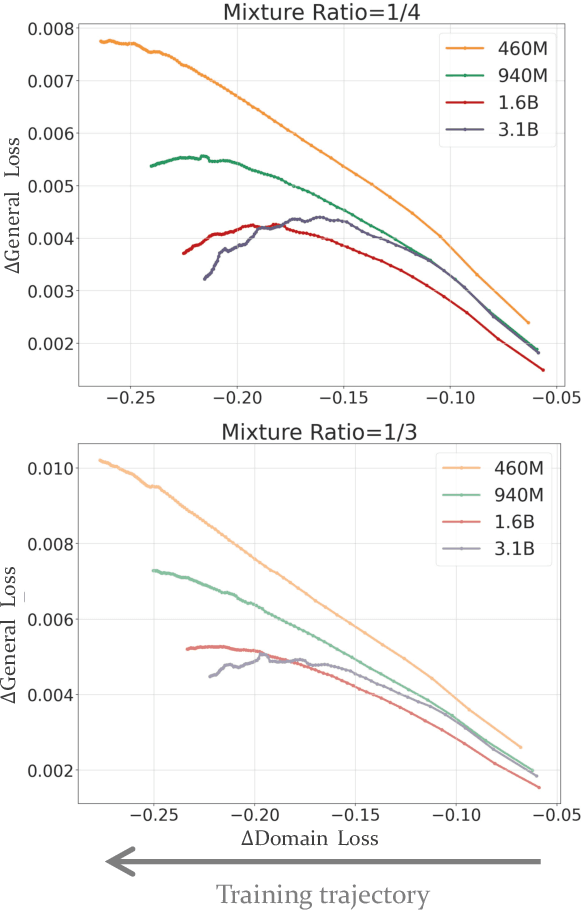
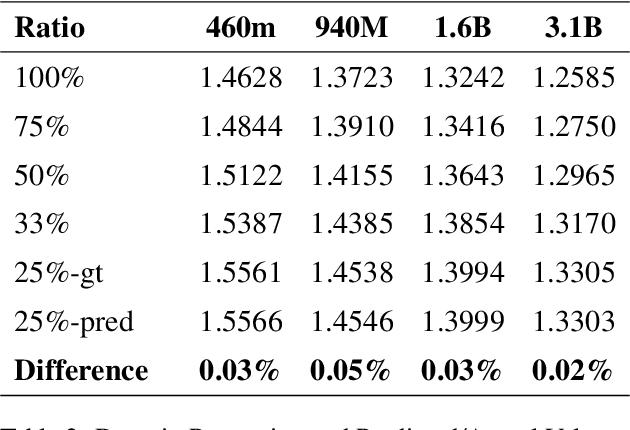
Large Language Models (LLMs) excel in diverse tasks but often underperform in specialized fields due to limited domain-specific or proprietary corpus. Continual pre-training (CPT) enhances LLM capabilities by imbuing new domain-specific or proprietary knowledge while replaying general corpus to prevent catastrophic forgetting. The data mixture ratio of general corpus and domain-specific corpus, however, has been chosen heuristically, leading to sub-optimal training efficiency in practice. In this context, we attempt to re-visit the scaling behavior of LLMs under the hood of CPT, and discover a power-law relationship between loss, mixture ratio, and training tokens scale. We formalize the trade-off between general and domain-specific capabilities, leading to a well-defined Critical Mixture Ratio (CMR) of general and domain data. By striking the balance, CMR maintains the model's general ability and achieves the desired domain transfer, ensuring the highest utilization of available resources. Therefore, if we value the balance between efficiency and effectiveness, CMR can be consider as the optimal mixture ratio.Through extensive experiments, we ascertain the predictability of CMR, and propose CMR scaling law and have substantiated its generalization. These findings offer practical guidelines for optimizing LLM training in specialized domains, ensuring both general and domain-specific performance while efficiently managing training resources.
Region-level Contrastive and Consistency Learning for Semi-Supervised Semantic Segmentation
Apr 28, 2022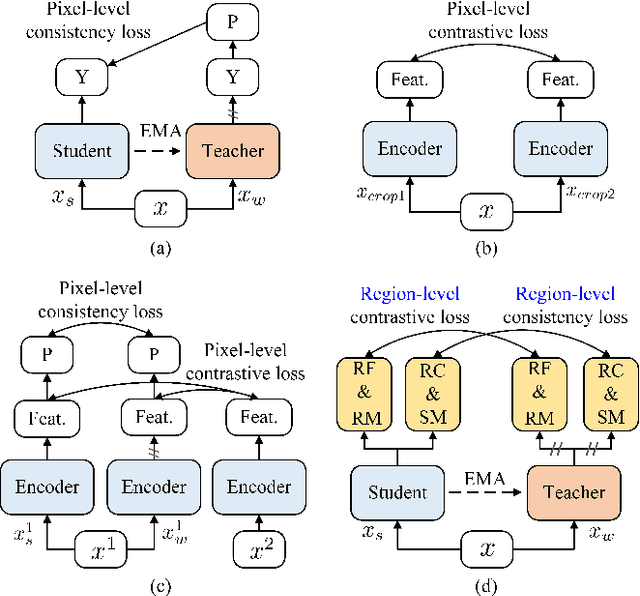
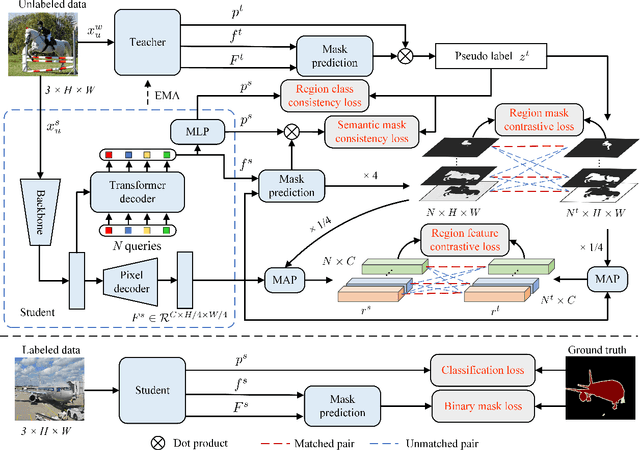
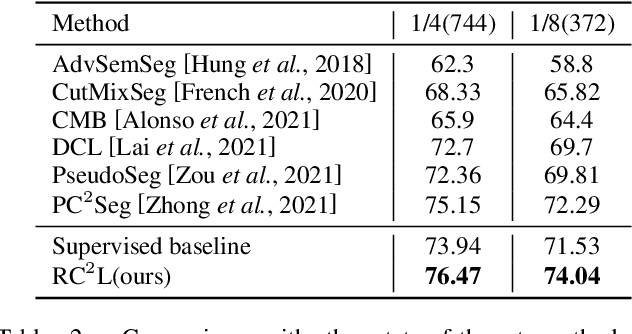
Current semi-supervised semantic segmentation methods mainly focus on designing pixel-level consistency and contrastive regularization. However, pixel-level regularization is sensitive to noise from pixels with incorrect predictions, and pixel-level contrastive regularization has memory and computational cost with O(pixel_num^2). To address the issues, we propose a novel region-level contrastive and consistency learning framework (RC^2L) for semi-supervised semantic segmentation. Specifically, we first propose a Region Mask Contrastive (RMC) loss and a Region Feature Contrastive (RFC) loss to accomplish region-level contrastive property. Furthermore, Region Class Consistency (RCC) loss and Semantic Mask Consistency (SMC) loss are proposed for achieving region-level consistency. Based on the proposed region-level contrastive and consistency regularization, we develop a region-level contrastive and consistency learning framework (RC^2L) for semi-supervised semantic segmentation, and evaluate our RC$^2$L on two challenging benchmarks (PASCAL VOC 2012 and Cityscapes), outperforming the state-of-the-art.