 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model Transfer to All: On Robust Jailbreak Prompts Generation against LLMs
May 23, 2025Safety alignment in large language models (LLMs) is increasingly compromised by jailbreak attacks, which can manipulate these models to generate harmful or unintended content. Investigating these attacks is crucial for uncovering model vulnerabilities. However, many existing jailbreak strategies fail to keep pace with the rapid development of defense mechanisms, such as defensive suffixes, rendering them ineffective against defended models. To tackle this issue, we introduce a novel attack method called ArrAttack, specifically designed to target defended LLMs. ArrAttack automatically generates robust jailbreak prompts capable of bypassing various defense measures. This capability is supported by a universal robustness judgment model that, once trained, can perform robustness evaluation for any target model with a wide variety of defenses. By leveraging this model, we can rapidly develop a robust jailbreak prompt generator that efficiently converts malicious input prompts into effective attacks. Extensive evaluations reveal that ArrAttack significantly outperforms existing attack strategies, demonstrating strong transferability across both white-box and black-box models, including GPT-4 and Claude-3. Our work bridges the gap between jailbreak attacks and defenses, providing a fresh perspective on generating robust jailbreak prompts. We make the codebase available at https://github.com/LLBao/ArrAttack.
An Empirical Study on the Efficacy of Deep Active Learning for Image Classification
Nov 30, 2022



Deep Active Learning (DAL) has been advocated as a promising method to reduce labeling costs in supervised learning. However, existing evaluations of DAL methods are based on different settings, and their results are controversial. To tackle this issue, this paper comprehensively evaluates 19 existing DAL methods in a uniform setting, including traditional fully-\underline{s}upervised \underline{a}ctive \underline{l}earning (SAL) strategies and emerging \underline{s}emi-\underline{s}upervised \underline{a}ctive \underline{l}earning (SSAL) techniques. We have several non-trivial findings. First, most SAL methods cannot achieve higher accuracy than random selection. Second, semi-supervised training brings significant performance improvement compared to pure SAL methods. Third, performing data selection in the SSAL setting can achieve a significant and consistent performance improvement, especially with abundant unlabeled data. Our findings produce the following guidance for practitioners: one should (i) apply SSAL early and (ii) collect more unlabeled data whenever possible, for better model performance.
TestRank: Bringing Order into Unlabeled Test Instances for Deep Learning Tasks
May 21, 2021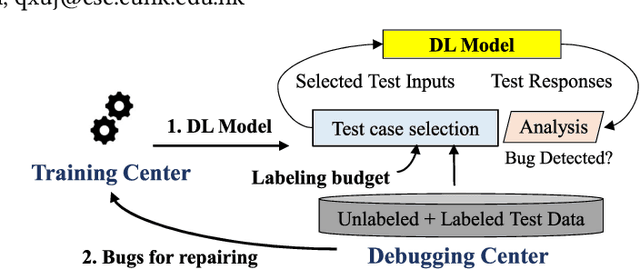

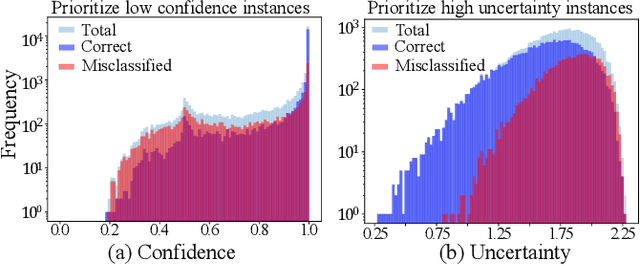
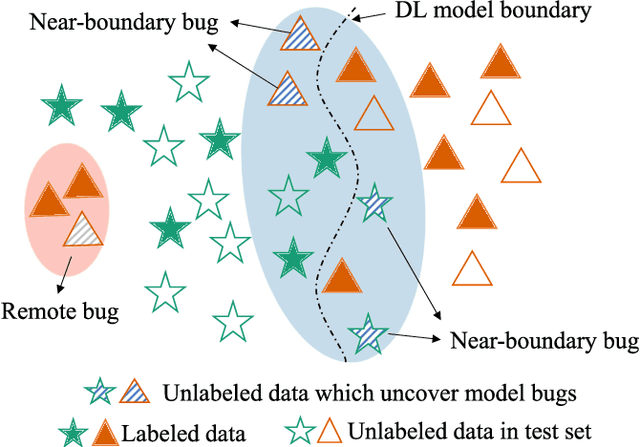
Deep learning (DL) has achieved unprecedented success in a variety of tasks. However, DL systems are notoriously difficult to test and debug due to the lack of explainability of DL models and the huge test input space to cover. Generally speaking, it is relatively easy to collect a massive amount of test data, but the labeling cost can be quite high. Consequently, it is essential to conduct test selection and label only those selected "high quality" bug-revealing test inputs for test cost reduction. In this paper, we propose a novel test prioritization technique that brings order into the unlabeled test instances according to their bug-revealing capabilities, namely TestRank. Different from existing solutions, TestRank leverages both intrinsic attributes and contextual attributes of test instances when prioritizing them. To be specific, we first build a similarity graph on test instances and training samples, and we conduct graph-based semi-supervised learning to extract contextual features. Then, for a particular test instance, the contextual features extracted from the graph neural network (GNN) and the intrinsic features obtained with the DL model itself are combined to predict its bug-revealing probability. Finally, TestRank prioritizes unlabeled test instances in descending order of the above probability value. We evaluate the performance of TestRank on a variety of image classification datasets. Experimental results show that the debugging efficiency of our method significantly outperforms existing test prioritization techniques.
I Know What You See: Power Side-Channel Attack on Convolutional Neural Network Accelerators
Mar 05, 2018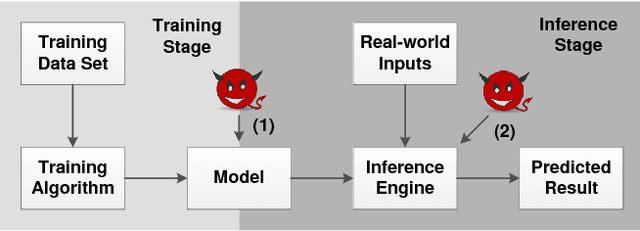

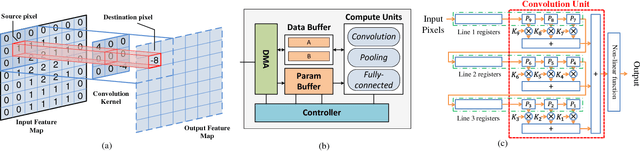
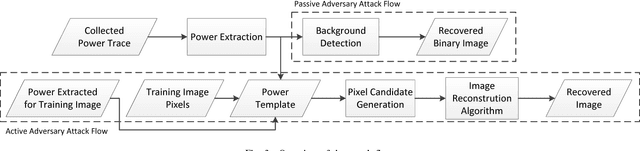
Deep learning has become the de-facto computational paradigm for various kinds of perception problems, including many privacy-sensitive applications such as online medical image analysis. No doubt to say, the data privacy of these deep learning systems is a serious concern. Different from previous research focusing on exploiting privacy leakage from deep learning models, in this paper, we present the first attack on the implementation of deep learning models. To be specific, we perform the attack on an FPGA-based convolutional neural network accelerator and we manage to recover the input image from the collected power traces without knowing the detailed parameters in the neural network by utilizing the characteristics of the "line buffer" performing convolution in the CNN accelerators. For the MNIST dataset, our power side-channel attack is able to achieve up to 89% recognition accuracy.
Towards Imperceptible and Robust Adversarial Example Attacks against Neural Networks
Jan 15, 2018
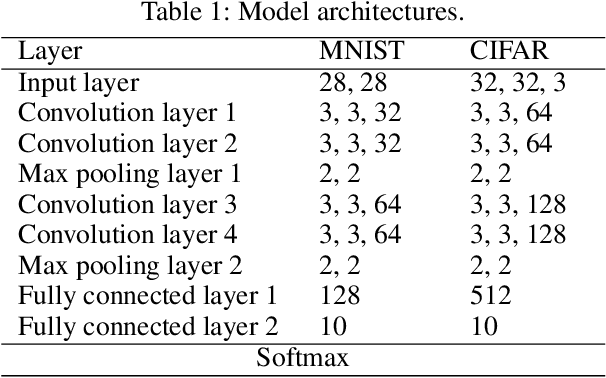
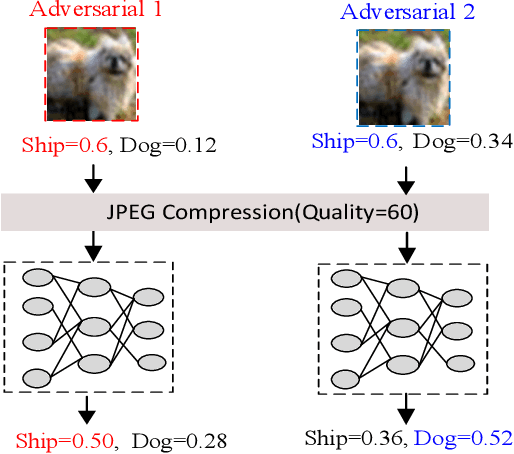

Machine learning systems based on deep neural networks, being able to produce state-of-the-art results on various perception tasks, have gained mainstream adoption in many applications. However, they are shown to be vulnerable to adversarial example attack, which generates malicious output by adding slight perturbations to the input. Previous adversarial example crafting methods, however, use simple metrics to evaluate the distances between the original examples and the adversarial ones, which could be easily detected by human eyes. In addition, these attacks are often not robust due to the inevitable noises and deviation in the physical world. In this work, we present a new adversarial example attack crafting method, which takes the human perceptual system into consideration and maximizes the noise tolerance of the crafted adversarial example. Experimental results demonstrate the efficacy of the proposed technique.