 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Convolution and Vision Transformer integrated model with Multi-scale Self-attention Mechanism
Aug 23, 2025Vision Transformer (ViT) has prevailed in computer vision tasks due to its strong long-range dependency modelling ability. However, its large model size with high computational cost and weak local feature modeling ability hinder its application in real scenarios. To balance computation efficiency and performance, we propose SAEViT (Sparse-Attention-Efficient-ViT), a lightweight ViT based model with convolution blocks, in this paper to achieve efficient downstream vision tasks. Specifically, SAEViT introduces a Sparsely Aggregated Attention (SAA) module that performs adaptive sparse sampling based on image redundancy and recovers the feature map via deconvolution operation, which significantly reduces the computational complexity of attention operations. In addition, a Channel-Interactive Feed-Forward Network (CIFFN) layer is developed to enhance inter-channel information exchange through feature decomposition and redistribution, mitigating redundancy in traditional feed-forward networks (FNN). Finally, a hierarchical pyramid structure with embedded depth-wise separable convolutional blocks (DWSConv) is devised to further strengthen convolutional features. Extensive experiments on mainstream datasets show that SAEViT achieves Top-1 accuracies of 76.3\% and 79.6\% on the ImageNet-1K classification task with only 0.8 GFLOPs and 1.3 GFLOPs, respectively, demonstrating a lightweight solution for various fundamental vision tasks.
CNNSum: Exploring Long-Context Summarization with Large Language Models in Chinese Novels
Dec 11, 2024



Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k to 128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field (https://github.com/CxsGhost/CNNSum).
CNNSum: Exploring Long-Conext Summarization with Large Language Models in Chinese Novels
Dec 05, 2024Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k\textasciitilde128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field.
E2LLM: Encoder Elongated Large Language Models for Long-Context Understanding and Reasoning
Sep 10, 2024



In the realm of Large Language Models (LLMs), the ability to process long contexts is increasingly crucial for tasks such as multi-round dialogues, code generation, and document summarization. This paper addresses the challenges of enhancing the long-context performance, reducing computational complexity, and leveraging pretrained models collectively termed the "impossible triangle." We introduce E2LLM (Encoder Elongated Large Language Models), a novel approach that effectively navigates this paradox. The method involves splitting long contexts into chunks, compressing each into embedding vectors via a pretrained text encoder, and utilizing an adapter to align these representations with a decoder-only LLM. Two training objectives, focusing on reconstruction of the encoder output and long-context instruction fine-tuning, are employed to facilitate the understanding of soft prompts by the LLM. Experimental results demonstrate that E2LLM achieves superior performance in long-context scenarios while balancing efficiency, performance, and compatibility with pretrained models. Our framework thus represents a significant advancement in the field, contributing to effective long-text modeling.
On Functional Test Generation for Deep Neural Network IPs
Nov 23, 2019

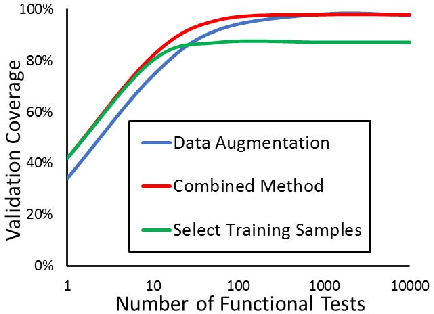

Machine learning systems based on deep neural networks (DNNs) produce state-of-the-art results in many applications. Considering the large amount of training data and know-how required to generate the network, it is more practical to use third-party DNN intellectual property (IP) cores for many designs. No doubt to say, it is essential for DNN IP vendors to provide test cases for functional validation without leaking their parameters to IP users. To satisfy this requirement, we propose to effectively generate test cases that activate parameters as many as possible and propagate their perturbations to outputs. Then the functionality of DNN IPs can be validated by only checking their outputs. However, it is difficult considering large numbers of parameters and highly non-linearity of DNNs. In this paper, we tackle this problem by judiciously selecting samples from the DNN training set and applying a gradient-based method to generate new test cases. Experimental results demonstrate the efficacy of our proposed solution.
I Know What You See: Power Side-Channel Attack on Convolutional Neural Network Accelerators
Mar 05, 2018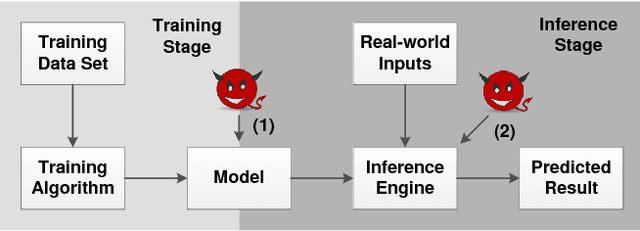

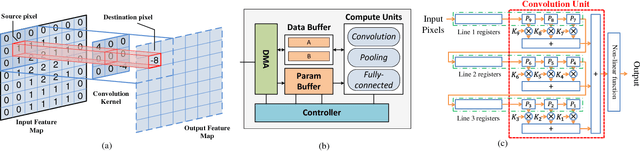
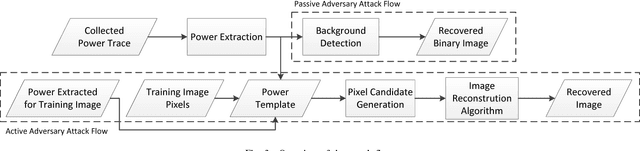
Deep learning has become the de-facto computational paradigm for various kinds of perception problems, including many privacy-sensitive applications such as online medical image analysis. No doubt to say, the data privacy of these deep learning systems is a serious concern. Different from previous research focusing on exploiting privacy leakage from deep learning models, in this paper, we present the first attack on the implementation of deep learning models. To be specific, we perform the attack on an FPGA-based convolutional neural network accelerator and we manage to recover the input image from the collected power traces without knowing the detailed parameters in the neural network by utilizing the characteristics of the "line buffer" performing convolution in the CNN accelerators. For the MNIST dataset, our power side-channel attack is able to achieve up to 89% recognition accuracy.
Towards Imperceptible and Robust Adversarial Example Attacks against Neural Networks
Jan 15, 2018
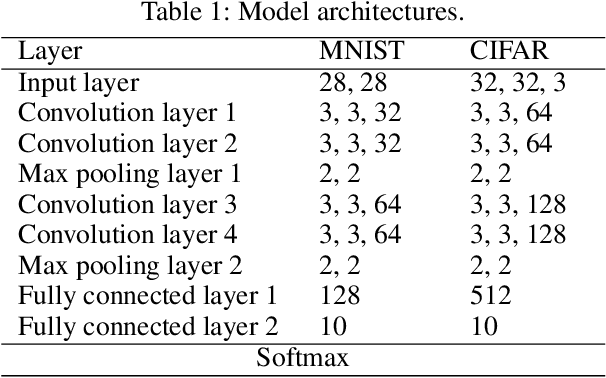
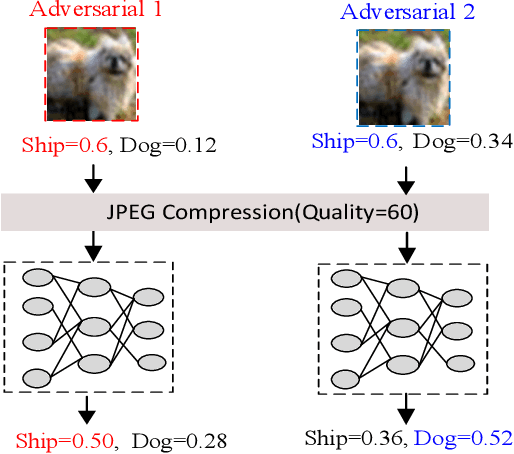

Machine learning systems based on deep neural networks, being able to produce state-of-the-art results on various perception tasks, have gained mainstream adoption in many applications. However, they are shown to be vulnerable to adversarial example attack, which generates malicious output by adding slight perturbations to the input. Previous adversarial example crafting methods, however, use simple metrics to evaluate the distances between the original examples and the adversarial ones, which could be easily detected by human eyes. In addition, these attacks are often not robust due to the inevitable noises and deviation in the physical world. In this work, we present a new adversarial example attack crafting method, which takes the human perceptual system into consideration and maximizes the noise tolerance of the crafted adversarial example. Experimental results demonstrate the efficacy of the proposed technique.