 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNNSum: Exploring Long-Context Summarization with Large Language Models in Chinese Novels
Dec 11, 2024



Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k to 128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field (https://github.com/CxsGhost/CNNSum).
CNNSum: Exploring Long-Conext Summarization with Large Language Models in Chinese Novels
Dec 05, 2024Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k\textasciitilde128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field.
LIFBench: Evaluating the Instruction Following Performance and Stability of Large Language Models in Long-Context Scenarios
Nov 11, 2024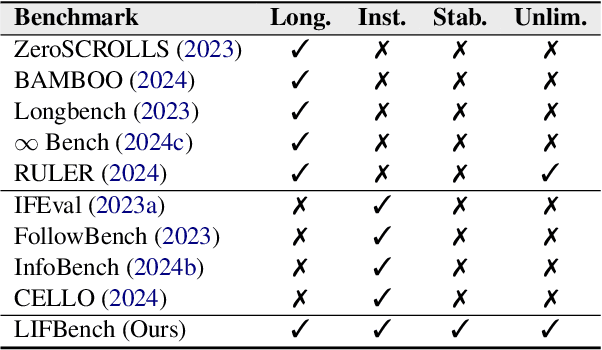
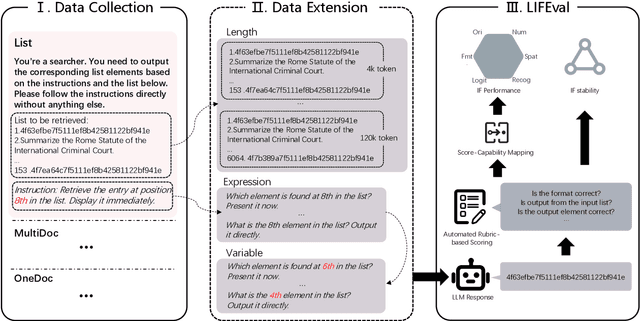
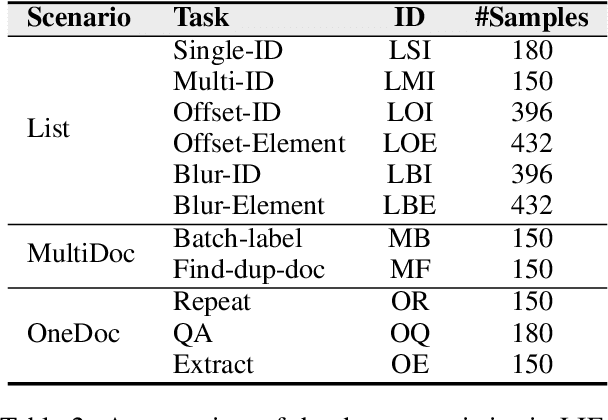
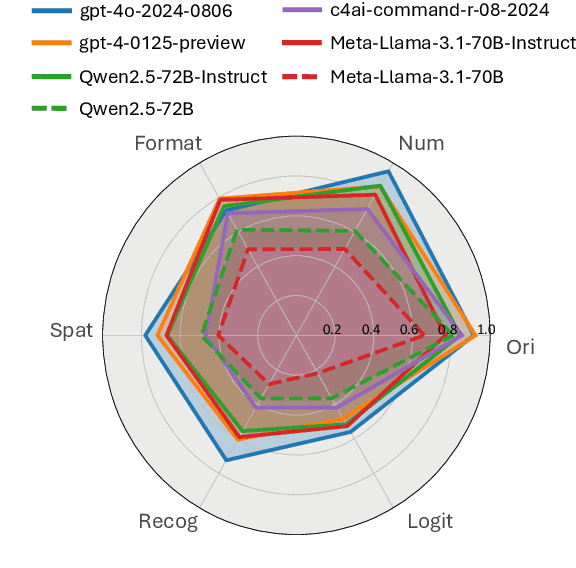
As Large Language Models (LLMs) continue to advance in natural language processing (NLP), their ability to stably follow instructions in long-context inputs has become crucial for real-world applications. While existing benchmarks assess various LLM capabilities, they rarely focus on instruction-following in long-context scenarios or stability on different inputs. In response, we introduce the Long-context Instruction-Following Benchmark (LIFBench), a scalable dataset designed to evaluate LLMs' instruction-following capabilities and stability across long contexts. LIFBench comprises three long-context scenarios and eleven diverse tasks, supported by 2,766 instructions generated through an automated expansion method across three dimensions: length, expression, and variables. For evaluation, we propose LIFEval, a rubric-based assessment framework that provides precise, automated scoring of complex LLM responses without relying on LLM-assisted evaluations or human judgments. This approach facilitates a comprehensive analysis of model performance and stability across various perspectives. We conduct extensive experiments on 20 notable LLMs across six length intervals, analyzing their instruction-following capabilities and stability. Our work contributes LIFBench and LIFEval as robust tools for assessing LLM performance in complex, long-context settings, providing insights that can inform future LLM development.
Migrating Face Swap to Mobile Devices: A lightweight Framework and A Supervised Training Solution
Apr 13, 2022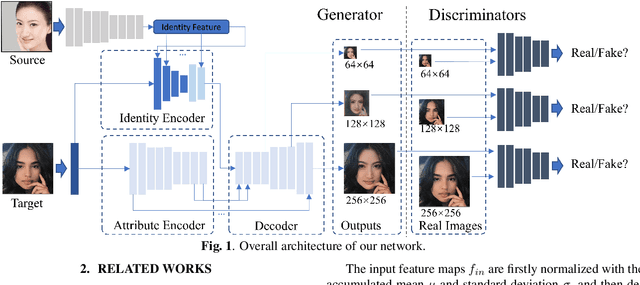
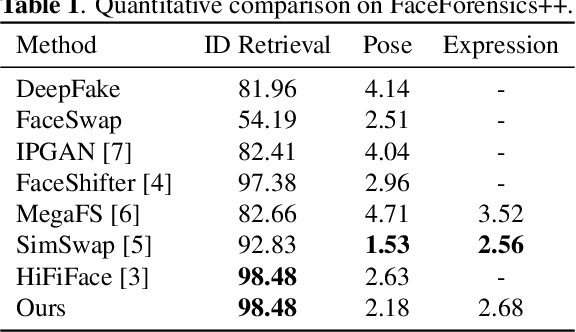
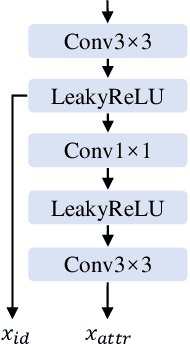
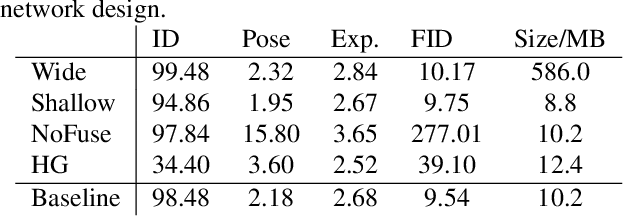
Existing face swap methods rely heavily on large-scale networks for adequate capacity to generate visually plausible results, which inhibits its applications on resource-constraint platforms. In this work, we propose MobileFSGAN, a novel lightweight GAN for face swap that can run on mobile devices with much fewer parameters while achieving competitive performance. A lightweight encoder-decoder structure is designed especially for image synthesis tasks, which is only 10.2MB and can run on mobile devices at a real-time speed. To tackle the unstability of training such a small network, we construct the FSTriplets dataset utilizing facial attribute editing techniques. FSTriplets provides source-target-result training triplets, yielding pixel-level labels thus for the first time making the training process supervised. We also designed multi-scale gradient losses for efficient back-propagation, resulting in faster and better convergence. Experimental results show that our model reaches comparable performance towards state-of-the-art methods, while significantly reducing the number of network parameters. Codes and the dataset have been released.
Detailed Facial Geometry Recovery from Multi-view Images by Learning an Implicit Function
Jan 04, 2022
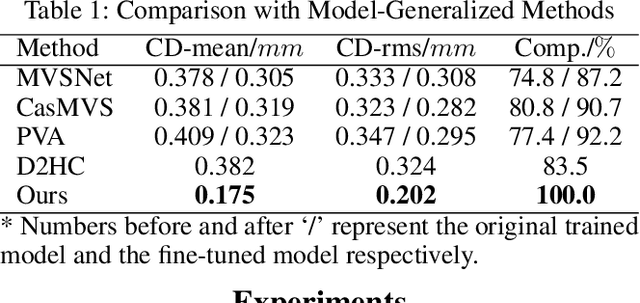

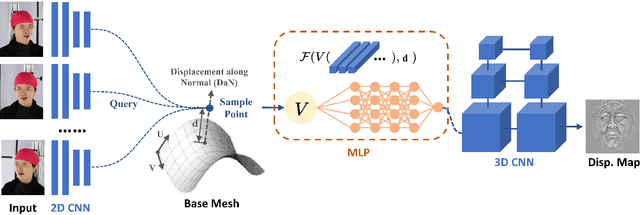
Recovering detailed facial geometry from a set of calibrated multi-view images is valuable for its wide range of applications. Traditional multi-view stereo (MVS) methods adopt optimization methods to regularize the matching cost. Recently, learning-based methods integrate all these into an end-to-end neural network and show superiority of efficiency. In this paper, we propose a novel architecture to recover extremely detailed 3D faces in roughly 10 seconds. Unlike previous learning-based methods that regularize the cost volume via 3D CNN, we propose to learn an implicit function for regressing the matching cost. By fitting a 3D morphable model from multi-view images, the features of multiple images are extracted and aggregated in the mesh-attached UV space, which makes the implicit function more effective in recovering detailed facial shape. Our method outperforms SOTA learning-based MVS in accuracy by a large margin on the FaceScape dataset. The code and data will be released soon.
Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition
Oct 24, 2019
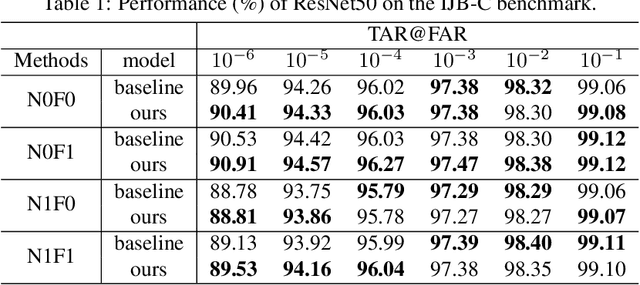

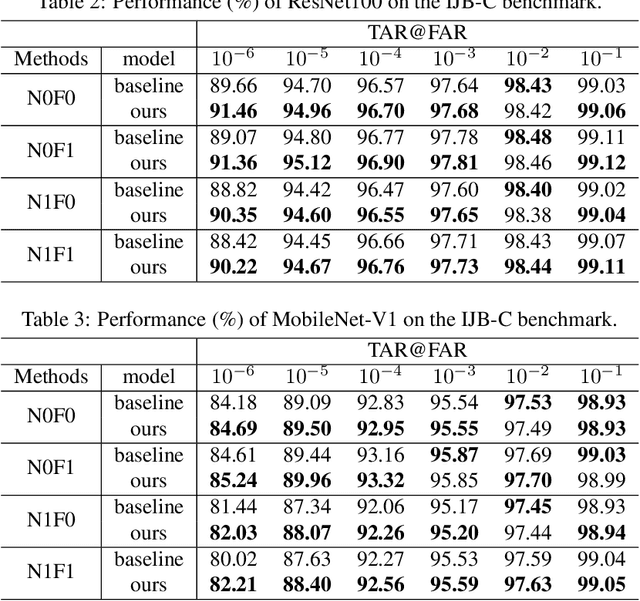
Face recognition has advanced considerably with the availability of large-scale labeled datasets. However, how to further improve the performance with the easily accessible unlabeled dataset remains a challenge. In this paper, we propose the novel Unknown Identity Rejection (UIR) loss to utilize the unlabeled data. We categorize identities in unconstrained environment into the known set and the unknown set. The former corresponds to the identities that appear in the labeled training dataset while the latter is its complementary set. Besides training the model to accurately classify the known identities, we also force the model to reject unknown identities provided by the unlabeled dataset via our proposed UIR loss. In order to 'reject' faces of unknown identities, centers of the known identities are forced to keep enough margin from centers of unknown identities which are assumed to be approximated by the features of their samples. By this means, the discriminativeness of the face representations can be enhanced. Experimental results demonstrate that our approach can provide obvious performance improvement by utilizing the unlabeled data.
iCartoonFace: A Benchmark of Cartoon Person Recognition
Aug 03, 2019


Cartoons receive increasingly attention and have a huge global market. Cartoon person recognition has a wealth of application scenarios. However, there is no large and high quality dataset for cartoon person recognition. It limit the development of recognition algorithms. In this paper, we propose the first large unconstrained cartoon database called iCartoonFace. We have released the dataset publicly available to promote cartoon person recognition research\footnote{The dataset can be applied by sending email to zhengyi01@qiyi.com}. The dataset contains 68,312 images of 2,639 identities. The dataset consists of persons which come from cartoon videos. The samples are extracted from public available images on website and online videos on iQiYi company. All images pass through a careful manual annotation process. We evaluated the state-of-the-art image classification and face recognition algorithms on the iCartoonFace dataset as a baseline. A dataset fusion method which utilize face feature to improve the performance of cartoon recognition task is proposed. Experimental performance show that the performance of baseline models much worse than human performance. The proposed dataset fusion method achieves a 4.74% improvement over the baseline model. In a word, state-of-the-art algorithms for classification and recognition are far from being perfect for unconstrained cartoon person recognition.
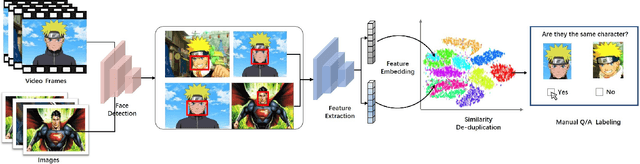
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018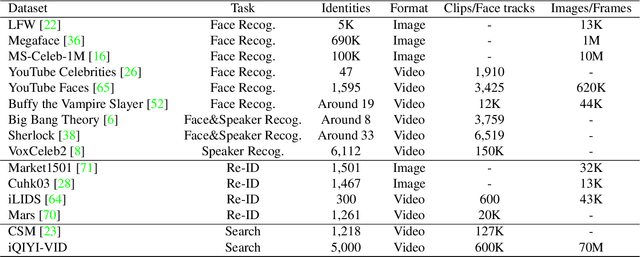

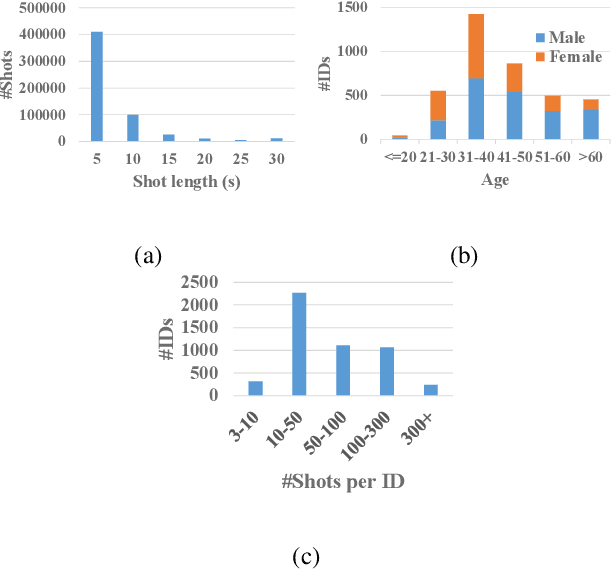
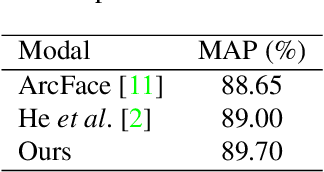
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.