 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Aug 12, 2025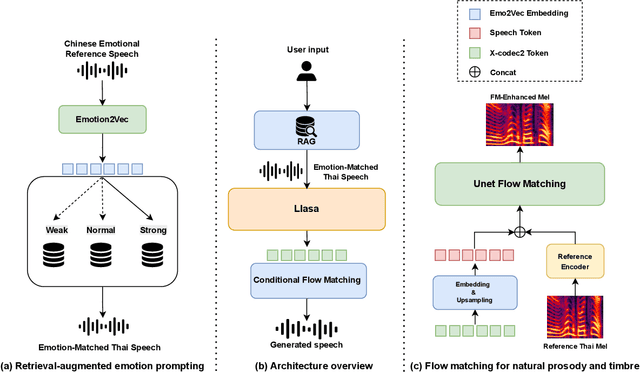
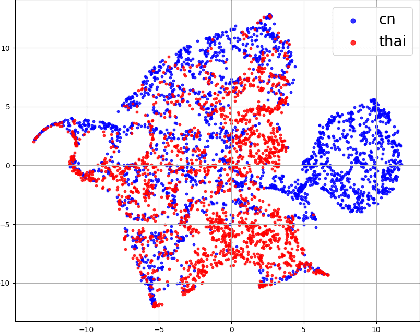
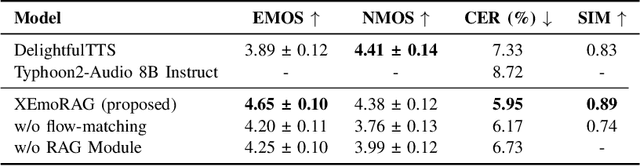
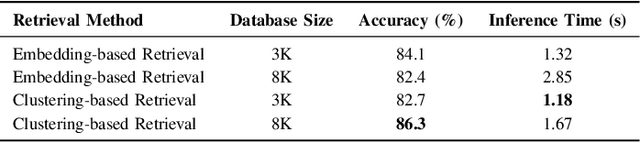
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language. However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features. In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data. XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency. Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels. These results highlight XEmoRAG's capability to achieve flexible and low-resource emotional transfer across languages. Our demo is available at https://tlzuo-lesley.github.io/Demo-page/ .
Weakly Supervised Data Refinement and Flexible Sequence Compression for Efficient Thai LLM-based ASR
May 28, 2025Despite remarkable achievements, automatic speech recognition (ASR) in low-resource scenarios still faces two challenges: high-quality data scarcity and high computational demands. This paper proposes EThai-ASR, the first to apply large language models (LLMs) to Thai ASR and create an efficient LLM-based ASR system. EThai-ASR comprises a speech encoder, a connection module and a Thai LLM decoder. To address the data scarcity and obtain a powerful speech encoder, EThai-ASR introduces a self-evolving data refinement strategy to refine weak labels, yielding an enhanced speech encoder. Moreover, we propose a pluggable sequence compression module used in the connection module with three modes designed to reduce the sequence length, thus decreasing computational demands while maintaining decent performance. Extensive experiments demonstrate that EThai-ASR has achieved state-of-the-art accuracy in multiple datasets. We release our refined text transcripts to promote further research.
FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter
Jun 12, 2024



Vocoders reconstruct speech waveforms from acoustic features and play a pivotal role in modern TTS systems. Frequent-domain GAN vocoders like Vocos and APNet2 have recently seen rapid advancements, outperforming time-domain models in inference speed while achieving comparable audio quality. However, these frequency-domain vocoders suffer from large parameter sizes, thus introducing extra memory burden. Inspired by PriorGrad and SpecGrad, we employ pseudo-inverse to estimate the amplitude spectrum as the initialization roughly. This simple initialization significantly mitigates the parameter demand for vocoder. Based on APNet2 and our streamlined Amplitude prediction branch, we propose our FreeV, compared with its counterpart APNet2, our FreeV achieves 1.8 times inference speed improvement with nearly half parameters. Meanwhile, our FreeV outperforms APNet2 in resynthesis quality, marking a step forward in pursuing real-time, high-fidelity speech synthesis. Code and checkpoints is available at: https://github.com/BakerBunker/FreeV
Zero-Shot Emotion Transfer For Cross-Lingual Speech Synthesis
Oct 06, 2023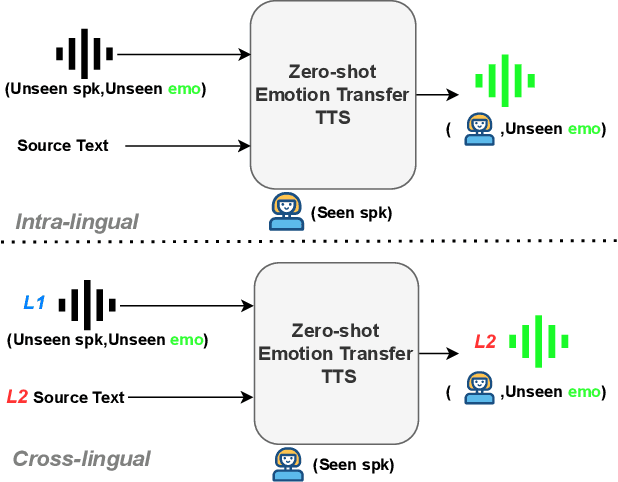
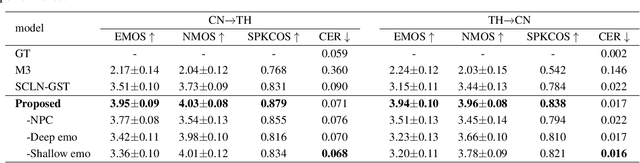
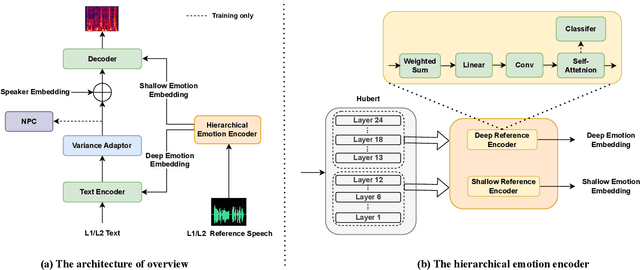
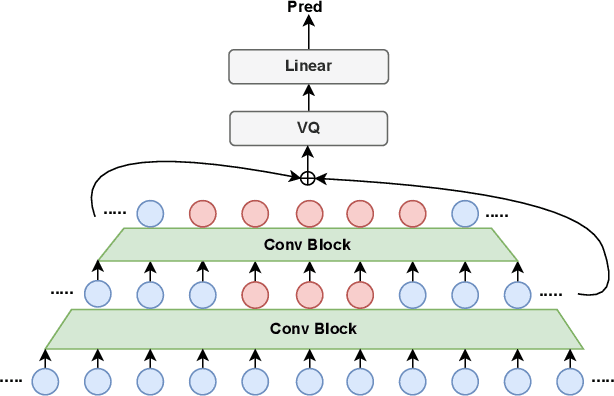
Zero-shot emotion transfer in cross-lingual speech synthesis aims to transfer emotion from an arbitrary speech reference in the source language to the synthetic speech in the target language. Building such a system faces challenges of unnatural foreign accents and difficulty in modeling the shared emotional expressions of different languages. Building on the DelightfulTTS neural architecture, this paper addresses these challenges by introducing specifically-designed modules to model the language-specific prosody features and language-shared emotional expressions separately. Specifically, the language-specific speech prosody is learned by a non-autoregressive predictive coding (NPC) module to improve the naturalness of the synthetic cross-lingual speech. The shared emotional expression between different languages is extracted from a pre-trained self-supervised model HuBERT with strong generalization capabilities. We further use hierarchical emotion modeling to capture more comprehensive emotions across different languages. Experimental results demonstrate the proposed framework's effectiveness in synthesizing bi-lingual emotional speech for the monolingual target speaker without emotional training data.
Preserving background sound in noise-robust voice conversion via multi-task learning
Nov 06, 2022Background sound is an informative form of art that is helpful in providing a more immersive experience in real-application voice conversion (VC) scenarios. However, prior research about VC, mainly focusing on clean voices, pay rare attention to VC with background sound. The critical problem for preserving background sound in VC is inevitable speech distortion by the neural separation model and the cascade mismatch between the source separation model and the VC model. In this paper, we propose an end-to-end framework via multi-task learning which sequentially cascades a source separation (SS) module, a bottleneck feature extraction module and a VC module. Specifically, the source separation task explicitly considers critical phase information and confines the distortion caused by the imperfect separation process. The source separation task, the typical VC task and the unified task shares a uniform reconstruction loss constrained by joint training to reduce the mismatch between the SS and VC modules. Experimental results demonstrate that our proposed framework significantly outperforms the baseline systems while achieving comparable quality and speaker similarity to the VC models trained with clean data.
Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition
Oct 24, 2019
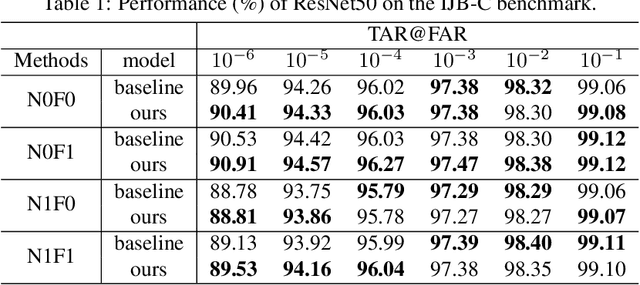

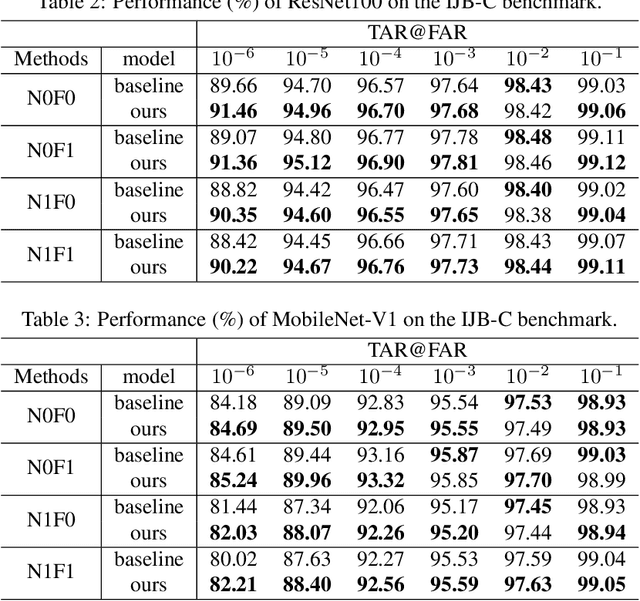
Face recognition has advanced considerably with the availability of large-scale labeled datasets. However, how to further improve the performance with the easily accessible unlabeled dataset remains a challenge. In this paper, we propose the novel Unknown Identity Rejection (UIR) loss to utilize the unlabeled data. We categorize identities in unconstrained environment into the known set and the unknown set. The former corresponds to the identities that appear in the labeled training dataset while the latter is its complementary set. Besides training the model to accurately classify the known identities, we also force the model to reject unknown identities provided by the unlabeled dataset via our proposed UIR loss. In order to 'reject' faces of unknown identities, centers of the known identities are forced to keep enough margin from centers of unknown identities which are assumed to be approximated by the features of their samples. By this means, the discriminativeness of the face representations can be enhanced. Experimental results demonstrate that our approach can provide obvious performance improvement by utilizing the unlabeled data.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018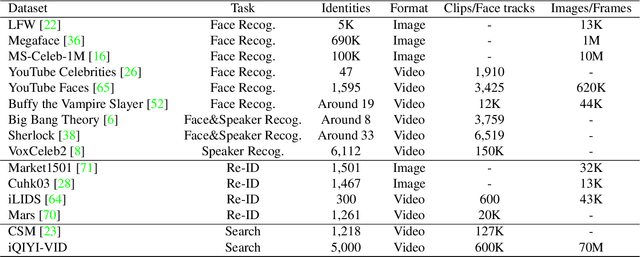

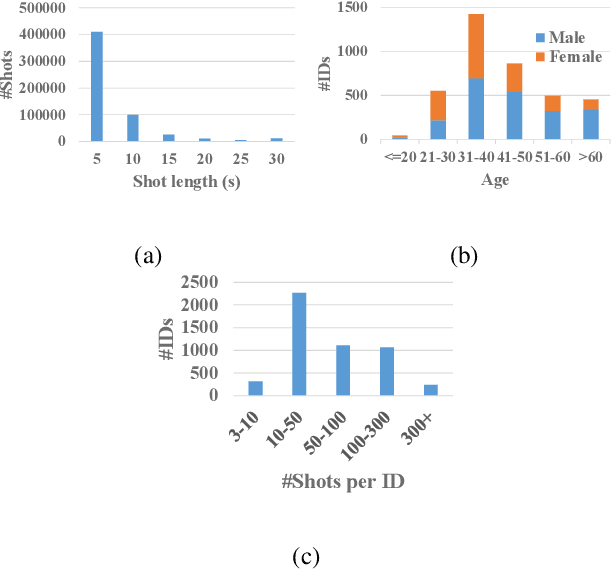
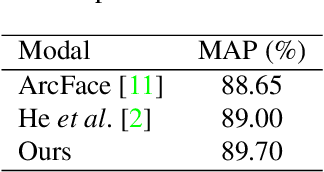
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.