 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
MSU-Bench: Towards Understanding the Conversational Multi-talker Scenarios
Aug 11, 2025Spoken Language Understanding (SLU) has progressed from traditional single-task methods to large audio language model (LALM) solutions. Yet, most existing speech benchmarks focus on single-speaker or isolated tasks, overlooking the challenges posed by multi-speaker conversations that are common in real-world scenarios. We introduce MSU-Bench, a comprehensive benchmark for evaluating multi-speaker conversational understanding with a speaker-centric design. Our hierarchical framework covers four progressive tiers: single-speaker static attribute understanding, single-speaker dynamic attribute understanding, multi-speaker background understanding, and multi-speaker interaction understanding. This structure ensures all tasks are grounded in speaker-centric contexts, from basic perception to complex reasoning across multiple speakers. By evaluating state-of-the-art models on MSU-Bench, we demonstrate that as task complexity increases across the benchmark's tiers, all models exhibit a significant performance decline. We also observe a persistent capability gap between open-source models and closed-source commercial ones, particularly in multi-speaker interaction reasoning. These findings validate the effectiveness of MSU-Bench for assessing and advancing conversational understanding in realistic multi-speaker environments. Demos can be found in the supplementary material.
Weakly Supervised Data Refinement and Flexible Sequence Compression for Efficient Thai LLM-based ASR
May 28, 2025Despite remarkable achievements, automatic speech recognition (ASR) in low-resource scenarios still faces two challenges: high-quality data scarcity and high computational demands. This paper proposes EThai-ASR, the first to apply large language models (LLMs) to Thai ASR and create an efficient LLM-based ASR system. EThai-ASR comprises a speech encoder, a connection module and a Thai LLM decoder. To address the data scarcity and obtain a powerful speech encoder, EThai-ASR introduces a self-evolving data refinement strategy to refine weak labels, yielding an enhanced speech encoder. Moreover, we propose a pluggable sequence compression module used in the connection module with three modes designed to reduce the sequence length, thus decreasing computational demands while maintaining decent performance. Extensive experiments demonstrate that EThai-ASR has achieved state-of-the-art accuracy in multiple datasets. We release our refined text transcripts to promote further research.
Copy-Move Image Forgery Detection Based on Evolving Circular Domains Coverage
Sep 09, 2021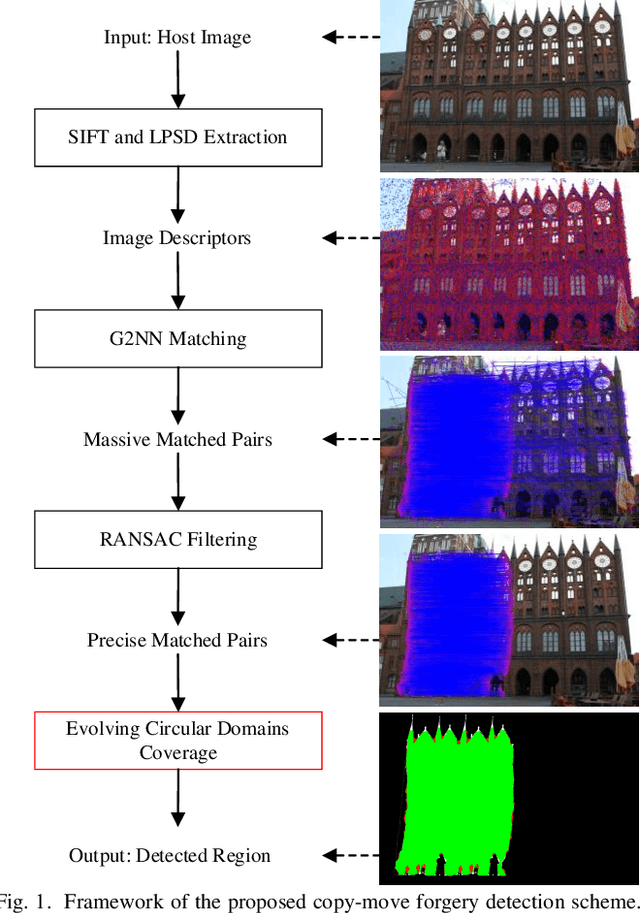
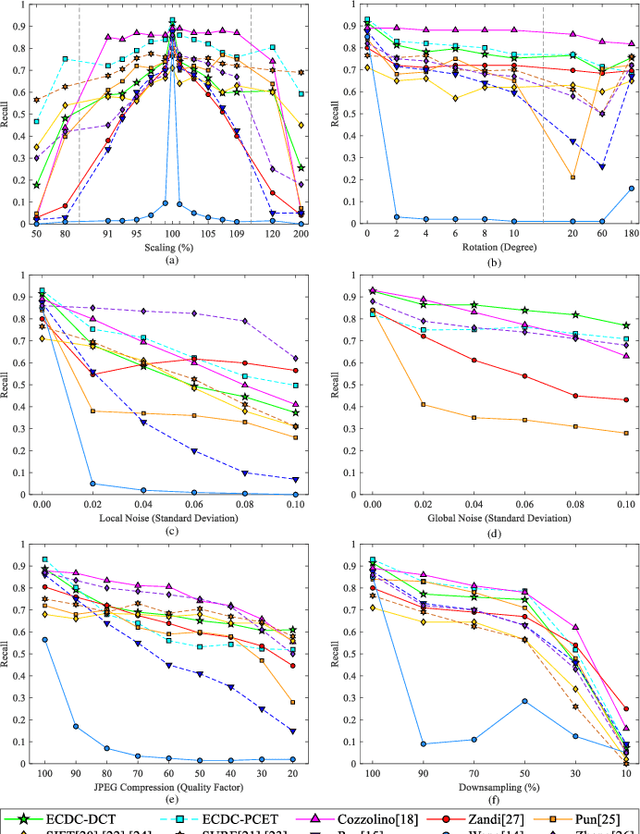
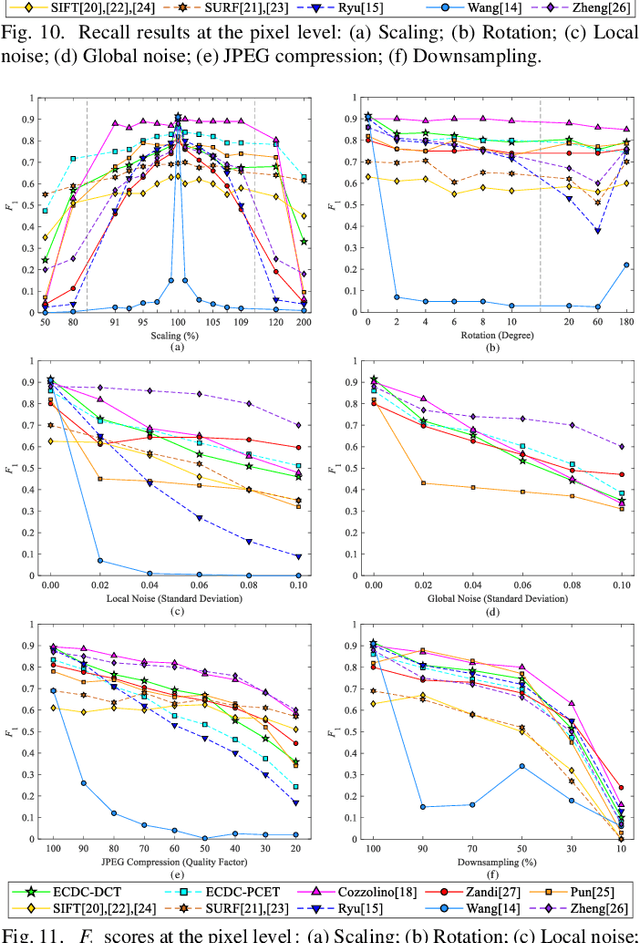

The aim of this paper is to improve the accuracy of copy-move forgery detection (CMFD) in image forensics by proposing a novel scheme. The proposed scheme integrates both block-based and keypoint-based forgery detection methods. Firstly, speed-up robust feature (SURF) descriptor in log-polar space and scale invariant feature transform (SIFT) descriptor are extracted from an entire forged image. Secondly, generalized 2 nearest neighbor (g2NN) is employed to get massive matched pairs. Then, random sample consensus (RANSAC) algorithm is employed to filter out mismatched pairs, thus allowing rough localization of the counterfeit areas. To present more accurately these forgery areas more accurately, we propose an efficient and accurate algorithm, evolving circular domains coverage (ECDC), to cover present them. This algorithm aims to find satisfactory threshold areas by extracting block features from jointly evolving circular domains, which are centered on the matched pairs. Finally, morphological operation is applied to refine the detected forgery areas. The experimental results indicate that the proposed CMFD scheme can achieve better detection performance under various attacks compared with other state-of-the-art CMFD schemes.