 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFBench: Evaluating the Instruction Following Performance and Stability of Large Language Models in Long-Context Scenarios
Paper and Code
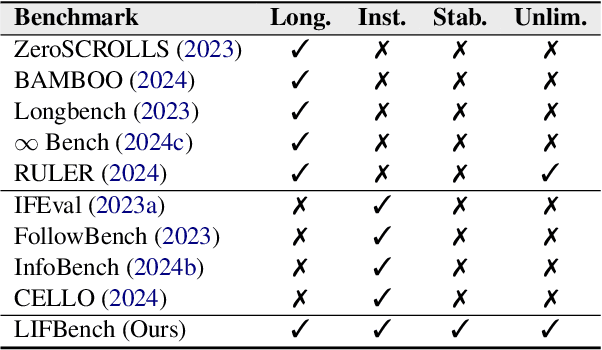
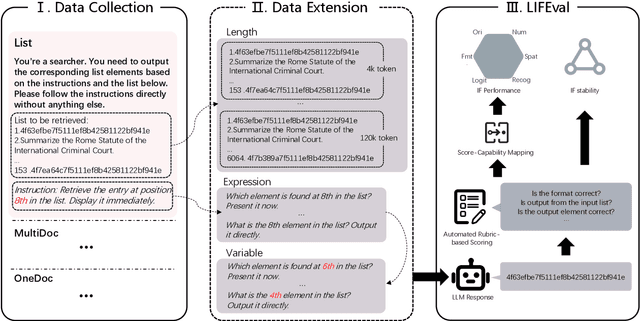
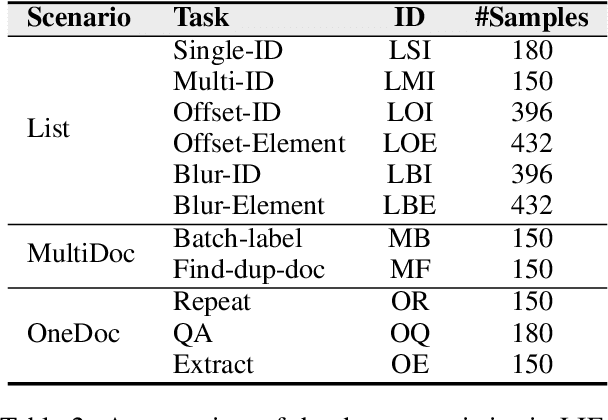
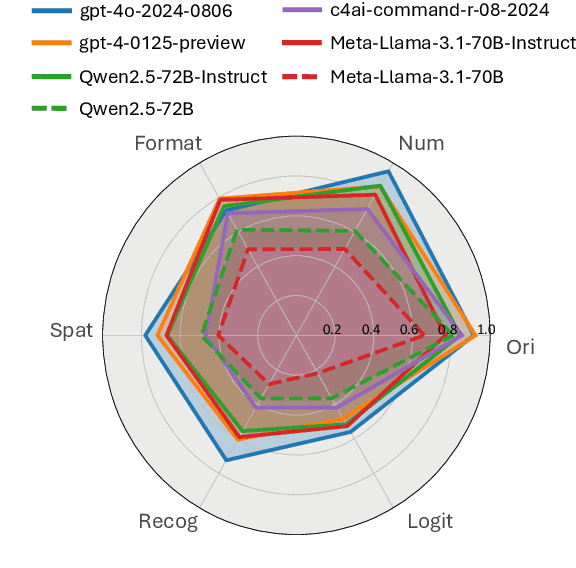
As Large Language Models (LLMs) continue to advance in natural language processing (NLP), their ability to stably follow instructions in long-context inputs has become crucial for real-world applications. While existing benchmarks assess various LLM capabilities, they rarely focus on instruction-following in long-context scenarios or stability on different inputs. In response, we introduce the Long-context Instruction-Following Benchmark (LIFBench), a scalable dataset designed to evaluate LLMs' instruction-following capabilities and stability across long contexts. LIFBench comprises three long-context scenarios and eleven diverse tasks, supported by 2,766 instructions generated through an automated expansion method across three dimensions: length, expression, and variables. For evaluation, we propose LIFEval, a rubric-based assessment framework that provides precise, automated scoring of complex LLM responses without relying on LLM-assisted evaluations or human judgments. This approach facilitates a comprehensive analysis of model performance and stability across various perspectives. We conduct extensive experiments on 20 notable LLMs across six length intervals, analyzing their instruction-following capabilities and stability. Our work contributes LIFBench and LIFEval as robust tools for assessing LLM performance in complex, long-context settings, providing insights that can inform future LLM development.