 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed Facial Geometry Recovery from Multi-view Images by Learning an Implicit Function
Paper and Code

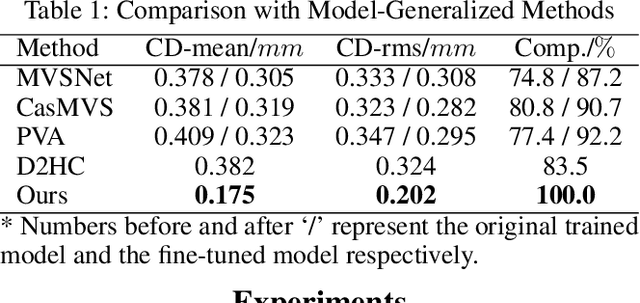

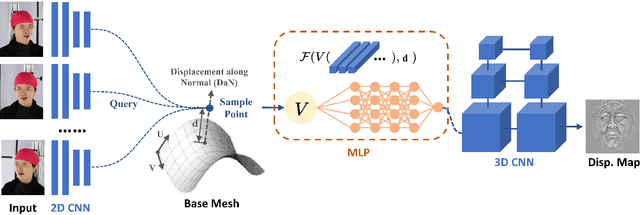
Recovering detailed facial geometry from a set of calibrated multi-view images is valuable for its wide range of applications. Traditional multi-view stereo (MVS) methods adopt optimization methods to regularize the matching cost. Recently, learning-based methods integrate all these into an end-to-end neural network and show superiority of efficiency. In this paper, we propose a novel architecture to recover extremely detailed 3D faces in roughly 10 seconds. Unlike previous learning-based methods that regularize the cost volume via 3D CNN, we propose to learn an implicit function for regressing the matching cost. By fitting a 3D morphable model from multi-view images, the features of multiple images are extracted and aggregated in the mesh-attached UV space, which makes the implicit function more effective in recovering detailed facial shape. Our method outperforms SOTA learning-based MVS in accuracy by a large margin on the FaceScape dataset. The code and data will be released soon.