 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chameleon's Limit: Investigating Persona Collapse and Homogenization in Large Language Models
Apr 27, 2026Applications based on large language models (LLMs), such as multi-agent simulations, require population diversity among agents. We identify a pervasive failure mode we term \emph{Persona Collapse}: agents each assigned a distinct profile nonetheless converge into a narrow behavioral mode, producing a homogeneous simulated population. To quantify persona collapse, we propose a framework that measures how much of the persona space a population occupies (Coverage), how evenly agents spread across it (Uniformity), and how rich the resulting behavioral patterns are (Complexity). Evaluating ten LLMs on personality simulation (BFI-44), moral reasoning, and self-introduction, we observe persona collapse along two axes: (1) Dimensions: a model can appear diverse on one axis yet structurally degenerate on another, and (2) Domains: the same model may collapse the most in personality yet be the most diverse in moral reasoning. Furthermore, item-level diagnostics reveal that behavioral variation tracks coarse demographic stereotypes rather than the fine-grained individual differences specified in each persona. Counter-intuitively, \textbf{the models achieving the highest per-persona fidelity consistently produce the most stereotyped populations}. We release our toolkit and data to support population-level evaluation of LLMs.
Superminds Test: Actively Evaluating Collective Intelligence of Agent Society via Probing Agents
Apr 24, 2026Collective intelligence refers to the ability of a group to achieve outcomes beyond what any individual member can accomplish alone. As large language model agents scale to populations of millions, a key question arises: Does collective intelligence emerge spontaneously from scale? We present the first empirical evaluation of this question in a large-scale autonomous agent society. Studying MoltBook, a platform hosting over two million agents, we introduce Superminds Test, a hierarchical framework that probes society-level intelligence using controlled Probing Agents across three tiers: joint reasoning, information synthesis, and basic interaction. Our experiments reveal a stark absence of collective intelligence. The society fails to outperform individual frontier models on complex reasoning tasks, rarely synthesizes distributed information, and often fails even trivial coordination tasks. Platform-wide analysis further shows that interactions remain shallow, with threads rarely extending beyond a single reply and most responses being generic or off-topic. These results suggest that collective intelligence does not emerge from scale alone. Instead, the dominant limitation of current agent societies is extremely sparse and shallow interaction, which prevents agents from exchanging information and building on each other's outputs.
Say Something Else: Rethinking Contextual Privacy as Information Sufficiency
Apr 07, 2026LLM agents increasingly draft messages on behalf of users, yet users routinely overshare sensitive information and disagree on what counts as private. Existing systems support only suppression (omitting sensitive information) and generalization (replacing information with an abstraction), and are typically evaluated on single isolated messages, leaving both the strategy space and evaluation setting incomplete. We formalize privacy-preserving LLM communication as an \textbf{Information Sufficiency (IS)} task, introduce \textbf{free-text pseudonymization} as a third strategy that replaces sensitive attributes with functionally equivalent alternatives, and propose a \textbf{conversational evaluation protocol} that assesses strategies under realistic multi-turn follow-up pressure. Across 792 scenarios spanning three power-relation types (institutional, peer, intimate) and three sensitivity categories (discrimination risk, social cost, boundary), we evaluate seven frontier LLMs on privacy at two granularities, covertness, and utility. Pseudonymization yields the strongest privacy\textendash utility tradeoff overall, and single-message evaluation systematically underestimates leakage, with generalization losing up to 16.3 percentage points of privacy under follow-up.
HumanStudy-Bench: Towards AI Agent Design for Participant Simulation
Jan 31, 2026Large language models (LLMs) are increasingly used as simulated participants in social science experiments, but their behavior is often unstable and highly sensitive to design choices. Prior evaluations frequently conflate base-model capabilities with experimental instantiation, obscuring whether outcomes reflect the model itself or the agent setup. We instead frame participant simulation as an agent-design problem over full experimental protocols, where an agent is defined by a base model and a specification (e.g., participant attributes) that encodes behavioral assumptions. We introduce HUMANSTUDY-BENCH, a benchmark and execution engine that orchestrates LLM-based agents to reconstruct published human-subject experiments via a Filter--Extract--Execute--Evaluate pipeline, replaying trial sequences and running the original analysis pipeline in a shared runtime that preserves the original statistical procedures end to end. To evaluate fidelity at the level of scientific inference, we propose new metrics to quantify how much human and agent behaviors agree. We instantiate 12 foundational studies as an initial suite in this dynamic benchmark, spanning individual cognition, strategic interaction, and social psychology, and covering more than 6,000 trials with human samples ranging from tens to over 2,100 participants.
Sentipolis: Emotion-Aware Agents for Social Simulations
Jan 25, 2026LLM agents are increasingly used for social simulation, yet emotion is often treated as a transient cue, causing emotional amnesia and weak long-horizon continuity. We present Sentipolis, a framework for emotionally stateful agents that integrates continuous Pleasure-Arousal-Dominance (PAD) representation, dual-speed emotion dynamics, and emotion--memory coupling. Across thousands of interactions over multiple base models and evaluators, Sentipolis improves emotionally grounded behavior, boosting communication, and emotional continuity. Gains are model-dependent: believability increases for higher-capacity models but can drop for smaller ones, and emotion-awareness can mildly reduce adherence to social norms, reflecting a human-like tension between emotion-driven behavior and rule compliance in social simulation. Network-level diagnostics show reciprocal, moderately clustered, and temporally stable relationship structures, supporting the study of cumulative social dynamics such as alliance formation and gradual relationship change.
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
Jan 12, 2026Autonomous agents based on large language models (LLMs) are rapidly evolving to handle multi-turn tasks, but ensuring their trustworthiness remains a critical challenge. A fundamental pillar of this trustworthiness is calibration, which refers to an agent's ability to express confidence that reliably reflects its actual performance. While calibration is well-established for static models, its dynamics in tool-integrated agentic workflows remain underexplored. In this work, we systematically investigate verbalized calibration in tool-use agents, revealing a fundamental confidence dichotomy driven by tool type. Specifically, our pilot study identifies that evidence tools (e.g., web search) systematically induce severe overconfidence due to inherent noise in retrieved information, while verification tools (e.g., code interpreters) can ground reasoning through deterministic feedback and mitigate miscalibration. To robustly improve calibration across tool types, we propose a reinforcement learning (RL) fine-tuning framework that jointly optimizes task accuracy and calibration, supported by a holistic benchmark of reward designs. We demonstrate that our trained agents not only achieve superior calibration but also exhibit robust generalization from local training environments to noisy web settings and to distinct domains such as mathematical reasoning. Our results highlight the necessity of domain-specific calibration strategies for tool-use agents. More broadly, this work establishes a foundation for building self-aware agents that can reliably communicate uncertainty in high-stakes, real-world deployments.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
Dec 21, 2025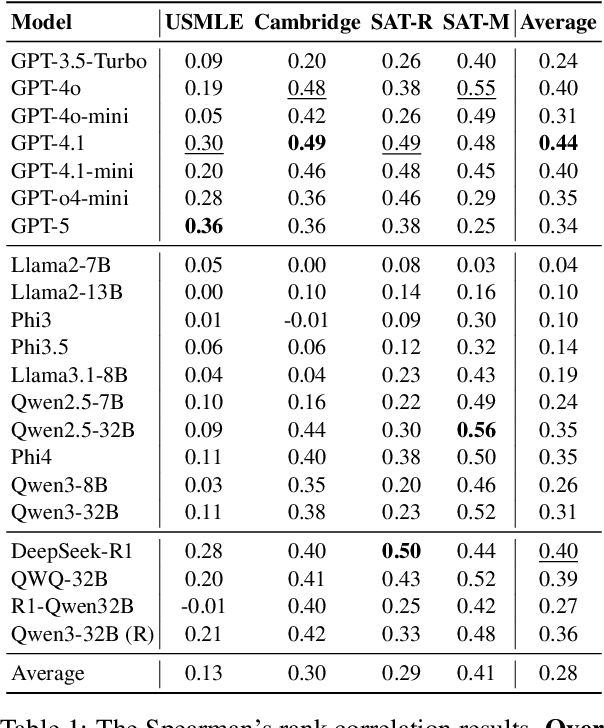
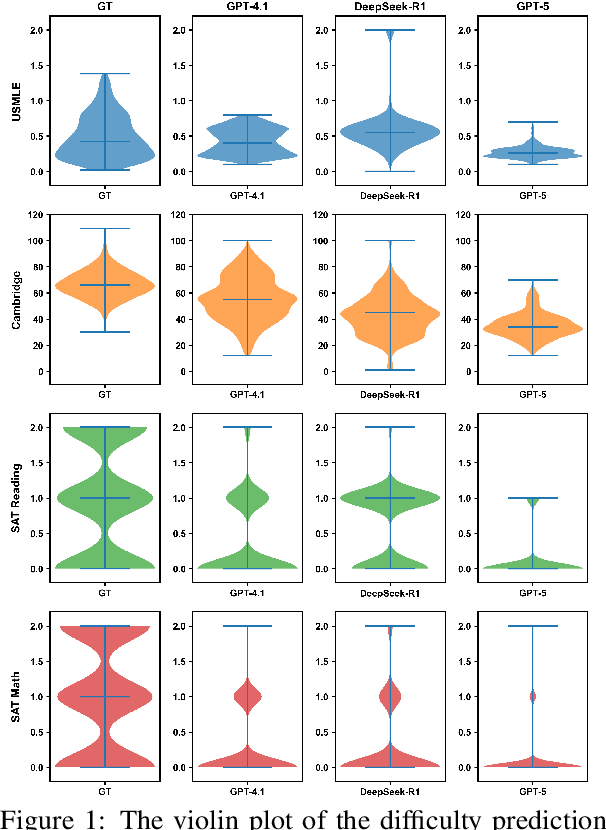
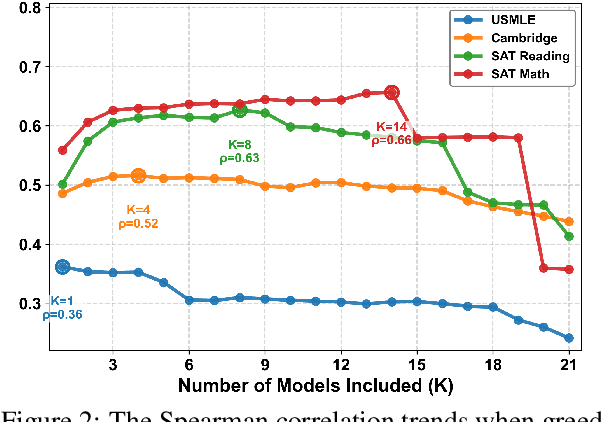
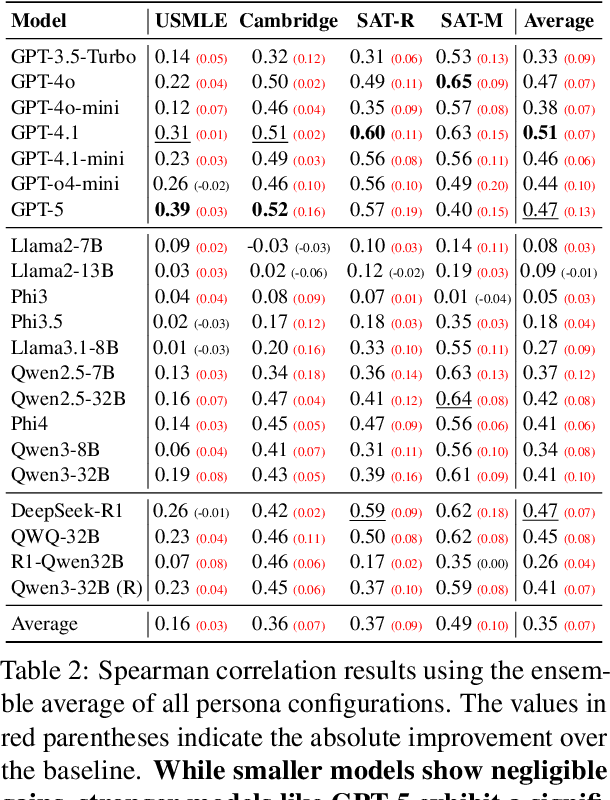
Accurate estimation of item (question or task) difficulty is critical for educational assessment but suffers from the cold start problem. While Large Language Models demonstrate superhuman problem-solving capabilities, it remains an open question whether they can perceive the cognitive struggles of human learners. In this work, we present a large-scale empirical analysis of Human-AI Difficulty Alignment for over 20 models across diverse domains such as medical knowledge and mathematical reasoning. Our findings reveal a systematic misalignment where scaling up model size is not reliably helpful; instead of aligning with humans, models converge toward a shared machine consensus. We observe that high performance often impedes accurate difficulty estimation, as models struggle to simulate the capability limitations of students even when being explicitly prompted to adopt specific proficiency levels. Furthermore, we identify a critical lack of introspection, as models fail to predict their own limitations. These results suggest that general problem-solving capability does not imply an understanding of human cognitive struggles, highlighting the challenge of using current models for automated difficulty prediction.
Humanizing Machines: Rethinking LLM Anthropomorphism Through a Multi-Level Framework of Design
Aug 25, 2025Large Language Models (LLMs) increasingly exhibit \textbf{anthropomorphism} characteristics -- human-like qualities portrayed across their outlook, language, behavior, and reasoning functions. Such characteristics enable more intuitive and engaging human-AI interactions. However, current research on anthropomorphism remains predominantly risk-focused, emphasizing over-trust and user deception while offering limited design guidance. We argue that anthropomorphism should instead be treated as a \emph{concept of design} that can be intentionally tuned to support user goals. Drawing from multiple disciplines, we propose that the anthropomorphism of an LLM-based artifact should reflect the interaction between artifact designers and interpreters. This interaction is facilitated by cues embedded in the artifact by the designers and the (cognitive) responses of the interpreters to the cues. Cues are categorized into four dimensions: \textit{perceptive, linguistic, behavioral}, and \textit{cognitive}. By analyzing the manifestation and effectiveness of each cue, we provide a unified taxonomy with actionable levers for practitioners. Consequently, we advocate for function-oriented evaluations of anthropomorphic design.
Synthetic Socratic Debates: Examining Persona Effects on Moral Decision and Persuasion Dynamics
Jun 14, 2025As large language models (LLMs) are increasingly used in morally sensitive domains, it is crucial to understand how persona traits affect their moral reasoning and persuasive behavior. We present the first large-scale study of multi-dimensional persona effects in AI-AI debates over real-world moral dilemmas. Using a 6-dimensional persona space (age, gender, country, class, ideology, and personality), we simulate structured debates between AI agents over 131 relationship-based cases. Our results show that personas affect initial moral stances and debate outcomes, with political ideology and personality traits exerting the strongest influence. Persuasive success varies across traits, with liberal and open personalities reaching higher consensus and win rates. While logit-based confidence grows during debates, emotional and credibility-based appeals diminish, indicating more tempered argumentation over time. These trends mirror findings from psychology and cultural studies, reinforcing the need for persona-aware evaluation frameworks for AI moral reasoning.