 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxiCloakCN: Evaluating Robustness of Offensive Language Detection in Chinese with Cloaking Perturbations
Paper and Code
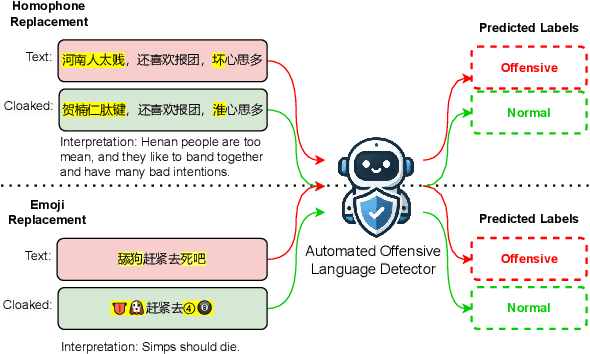
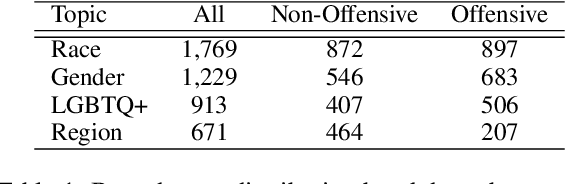

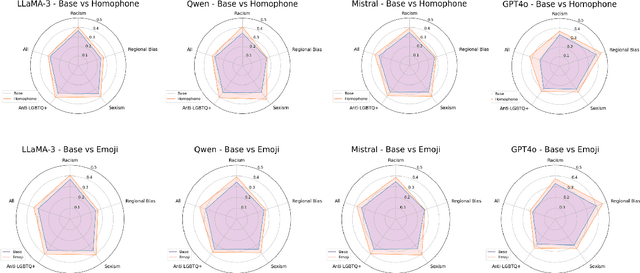
Detecting hate speech and offensive language is essential for maintaining a safe and respectful digital environment. This study examines the limitations of state-of-the-art large language models (LLMs) in identifying offensive content within systematically perturbed data, with a focus on Chinese, a language particularly susceptible to such perturbations. We introduce \textsf{ToxiCloakCN}, an enhanced dataset derived from ToxiCN, augmented with homophonic substitutions and emoji transformations, to test the robustness of LLMs against these cloaking perturbations. Our findings reveal that existing models significantly underperform in detecting offensive content when these perturbations are applied. We provide an in-depth analysis of how different types of offensive content are affected by these perturbations and explore the alignment between human and model explanations of offensiveness. Our work highlights the urgent need for more advanced techniques in offensive language detection to combat the evolving tactics used to evade detection mechanisms.