 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Order Simple Regret for Gaussian Process Bandits
Aug 20, 2021
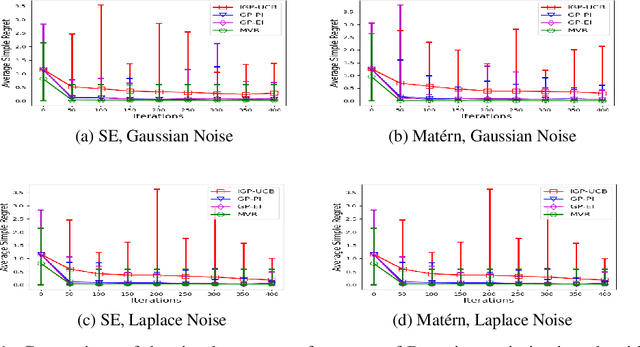
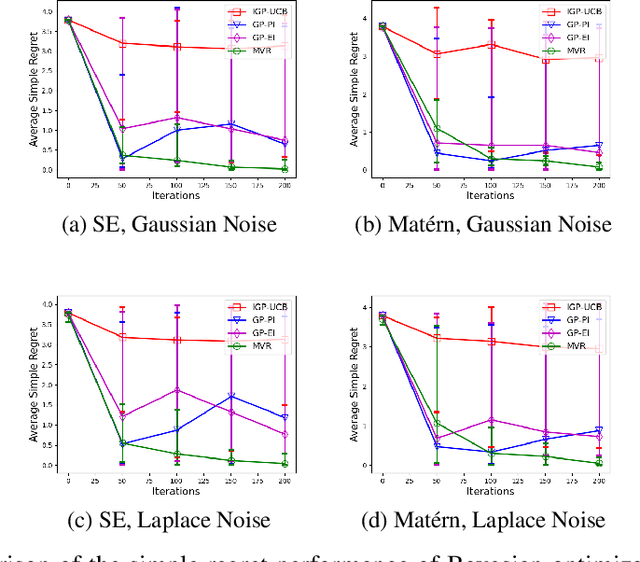
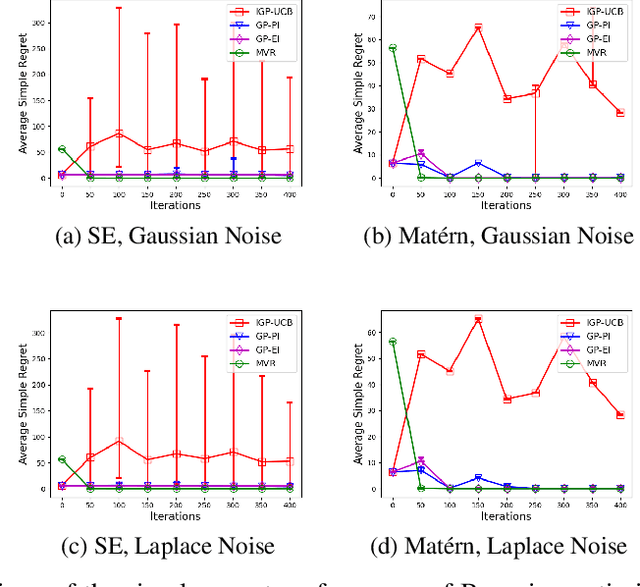
Consider the sequential optimization of a continuous, possibly non-convex, and expensive to evaluate objective function $f$. The problem can be cast as a Gaussian Process (GP) bandit where $f$ lives in a reproducing kernel Hilbert space (RKHS). The state of the art analysis of several learning algorithms shows a significant gap between the lower and upper bounds on the simple regret performance. When $N$ is the number of exploration trials and $\gamma_N$ is the maximal information gain, we prove an $\tilde{\mathcal{O}}(\sqrt{\gamma_N/N})$ bound on the simple regret performance of a pure exploration algorithm that is significantly tighter than the existing bounds. We show that this bound is order optimal up to logarithmic factors for the cases where a lower bound on regret is known. To establish these results, we prove novel and sharp confidence intervals for GP models applicable to RKHS elements which may be of broader interest.
Towards a Universal NLG for Dialogue Systems and Simulators with Future Bridging
May 24, 2021
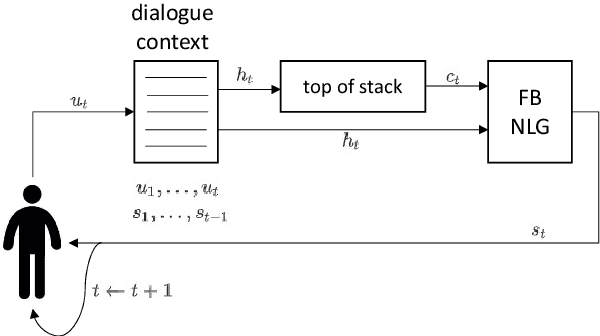


In a dialogue system pipeline, a natural language generation (NLG) unit converts the dialogue direction and content to a corresponding natural language realization. A recent trend for dialogue systems is to first pre-train on large datasets and then fine-tune in a supervised manner using datasets annotated with application-specific features. Though novel behaviours can be learned from custom annotation, the required effort severely bounds the quantity of the training set, and the application-specific nature limits the reuse. In light of the recent success of data-driven approaches, we propose the novel future bridging NLG (FBNLG) concept for dialogue systems and simulators. The critical step is for an FBNLG to accept a future user or system utterance to bridge the present context towards. Future bridging enables self supervised training over annotation-free datasets, decoupled the training of NLG from the rest of the system. An FBNLG, pre-trained with massive datasets, is expected to apply in classical or new dialogue scenarios with minimal adaptation effort. We evaluate a prototype FBNLG to show that future bridging can be a viable approach to a universal few-shot NLG for task-oriented and chit-chat dialogues.
Relationship-based Neural Baby Talk
Mar 08, 2021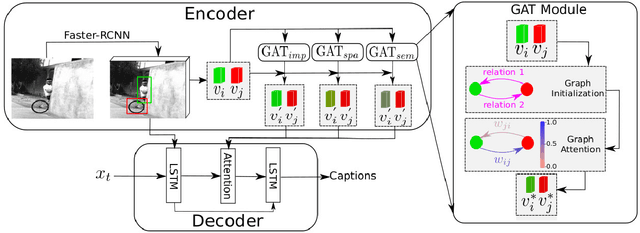
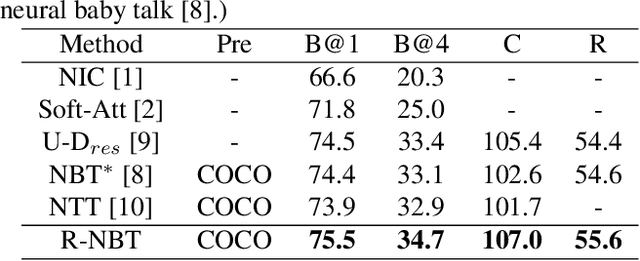
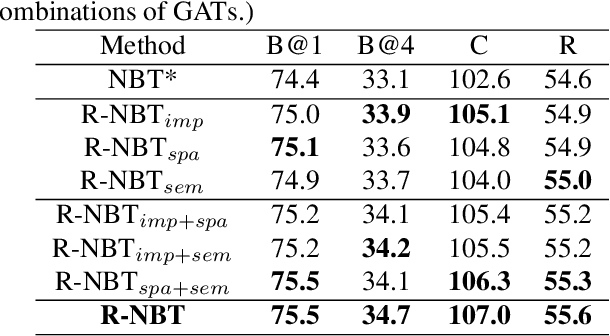

Understanding interactions between objects in an image is an important element for generating captions. In this paper, we propose a relationship-based neural baby talk (R-NBT) model to comprehensively investigate several types of pairwise object interactions by encoding each image via three different relationship-based graph attention networks (GATs). We study three main relationships: \textit{spatial relationships} to explore geometric interactions, \textit{semantic relationships} to extract semantic interactions, and \textit{implicit relationships} to capture hidden information that could not be modelled explicitly as above. We construct three relationship graphs with the objects in an image as nodes, and the mutual relationships of pairwise objects as edges. By exploring features of neighbouring regions individually via GATs, we integrate different types of relationships into visual features of each node. Experiments on COCO dataset show that our proposed R-NBT model outperforms state-of-the-art models trained on COCO dataset in three image caption generation tasks.
Cyclic orthogonal convolutions for long-range integration of features
Dec 11, 2020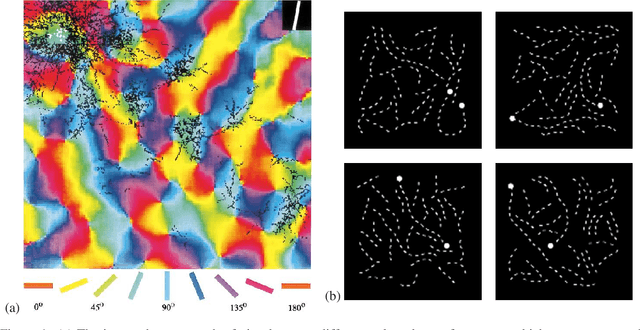

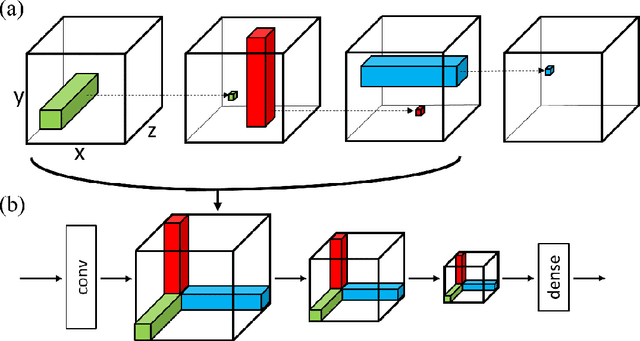
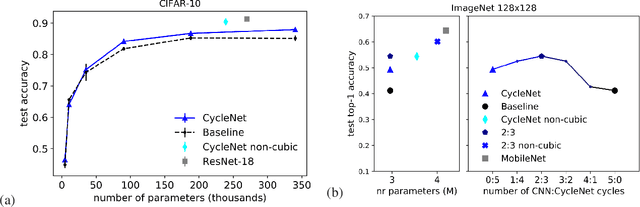
In Convolutional Neural Networks (CNNs) information flows across a small neighbourhood of each pixel of an image, preventing long-range integration of features before reaching deep layers in the network. We propose a novel architecture that allows flexible information flow between features $z$ and locations $(x,y)$ across the entire image with a small number of layers. This architecture uses a cycle of three orthogonal convolutions, not only in $(x,y)$ coordinates, but also in $(x,z)$ and $(y,z)$ coordinates. We stack a sequence of such cycles to obtain our deep network, named CycleNet. As this only requires a permutation of the axes of a standard convolution, its performance can be directly compared to a CNN. Our model obtains competitive results at image classification on CIFAR-10 and ImageNet datasets, when compared to CNNs of similar size. We hypothesise that long-range integration favours recognition of objects by shape rather than texture, and we show that CycleNet transfers better than CNNs to stylised images. On the Pathfinder challenge, where integration of distant features is crucial, CycleNet outperforms CNNs by a large margin. We also show that even when employing a small convolutional kernel, the size of receptive fields of CycleNet reaches its maximum after one cycle, while conventional CNNs require a large number of layers.
M2U-Net: Effective and Efficient Retinal Vessel Segmentation for Resource-Constrained Environments
Dec 03, 2018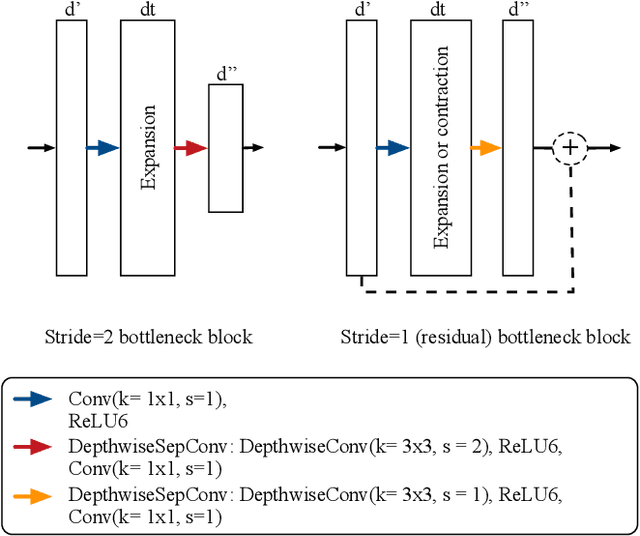
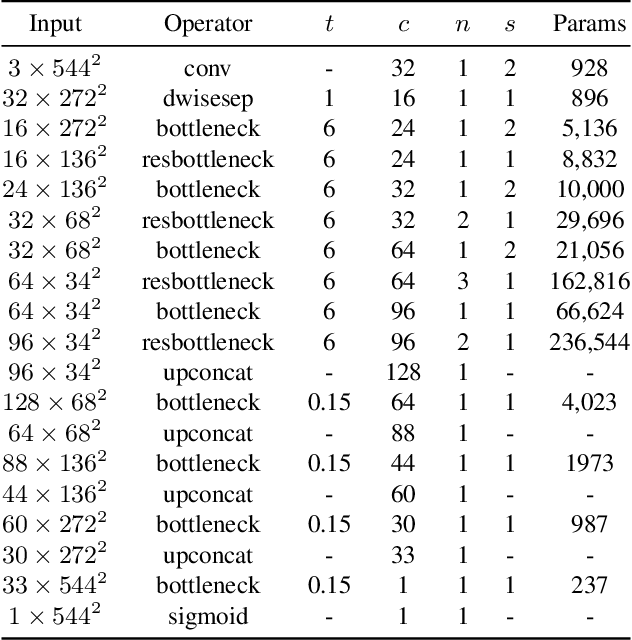
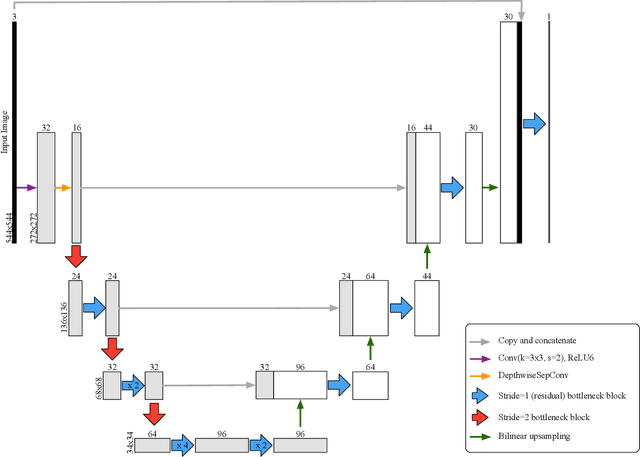

In this paper, we present a novel neural network architecture for retinal vessel segmentation that improves over the state of the art on two benchmark datasets, is the first to run in real time on high resolution images, and its small memory and processing requirements make it deployable in mobile and embedded systems. The M2U-Net has a new encoder-decoder architecture that is inspired by the U-Net. It adds pretrained components of MobileNetV2 in the encoder part and novel contractive bottleneck blocks in the decoder part that, combined with bilinear upsampling, drastically reduce the parameter count to 0.55M compared to 31.03M in the original U-Net. We have evaluated its performance against a wide body of previously published results on three public datasets. On two of them, the M2U-Net achieves new state-of-the-art performance by a considerable margin. When implemented on a GPU, our method is the first to achieve real-time inference speeds on high-resolution fundus images. We also implemented our proposed network on an ARM-based embedded system where it segments images in between 0.6 and 15 sec, depending on the resolution. Thus, the M2U-Net enables a number of applications of retinal vessel structure extraction, such as early diagnosis of eye diseases, retinal biometric authentication systems, and robot assisted microsurgery.