 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Action Localization without Knowing Boundaries
Jun 08, 2021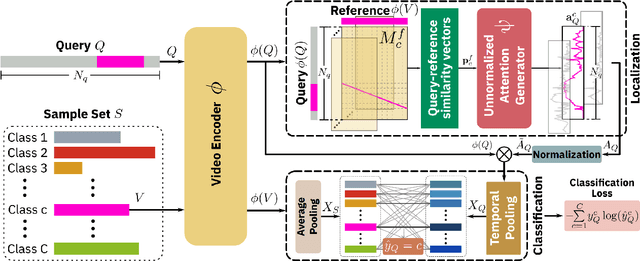

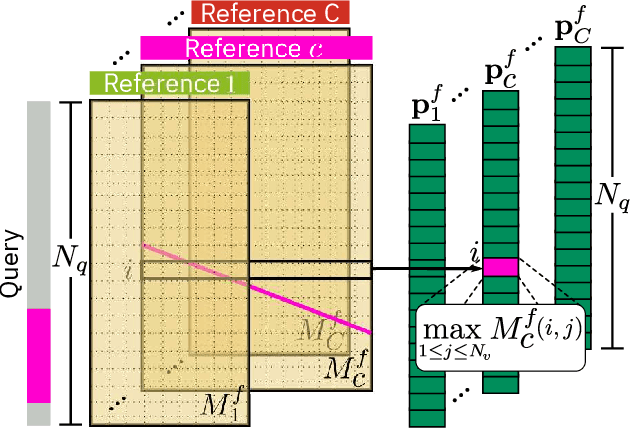
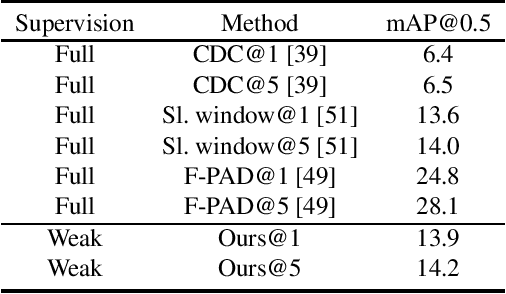
Learning to localize actions in long, cluttered, and untrimmed videos is a hard task, that in the literature has typically been addressed assuming the availability of large amounts of annotated training samples for each class -- either in a fully-supervised setting, where action boundaries are known, or in a weakly-supervised setting, where only class labels are known for each video. In this paper, we go a step further and show that it is possible to learn to localize actions in untrimmed videos when a) only one/few trimmed examples of the target action are available at test time, and b) when a large collection of videos with only class label annotation (some trimmed and some weakly annotated untrimmed ones) are available for training; with no overlap between the classes used during training and testing. To do so, we propose a network that learns to estimate Temporal Similarity Matrices (TSMs) that model a fine-grained similarity pattern between pairs of videos (trimmed or untrimmed), and uses them to generate Temporal Class Activation Maps (TCAMs) for seen or unseen classes. The TCAMs serve as temporal attention mechanisms to extract video-level representations of untrimmed videos, and to temporally localize actions at test time. To the best of our knowledge, we are the first to propose a weakly-supervised, one/few-shot action localization network that can be trained in an end-to-end fashion. Experimental results on THUMOS14 and ActivityNet1.2 datasets, show that our method achieves performance comparable or better to state-of-the-art fully-supervised, few-shot learning methods.
Relationship-based Neural Baby Talk
Mar 08, 2021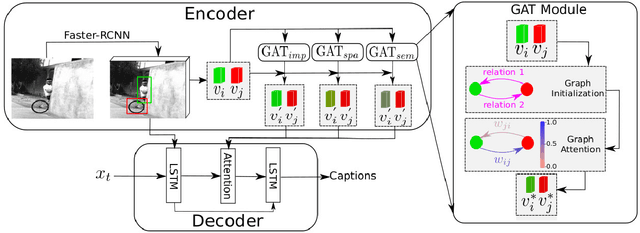
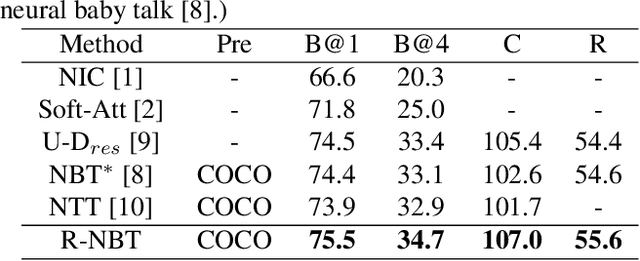
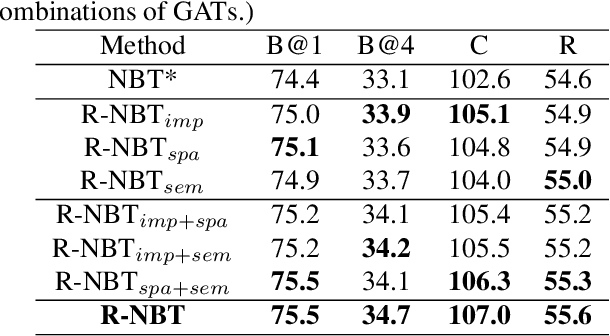

Understanding interactions between objects in an image is an important element for generating captions. In this paper, we propose a relationship-based neural baby talk (R-NBT) model to comprehensively investigate several types of pairwise object interactions by encoding each image via three different relationship-based graph attention networks (GATs). We study three main relationships: \textit{spatial relationships} to explore geometric interactions, \textit{semantic relationships} to extract semantic interactions, and \textit{implicit relationships} to capture hidden information that could not be modelled explicitly as above. We construct three relationship graphs with the objects in an image as nodes, and the mutual relationships of pairwise objects as edges. By exploring features of neighbouring regions individually via GATs, we integrate different types of relationships into visual features of each node. Experiments on COCO dataset show that our proposed R-NBT model outperforms state-of-the-art models trained on COCO dataset in three image caption generation tasks.