 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning with MAML on Trees
Mar 08, 2021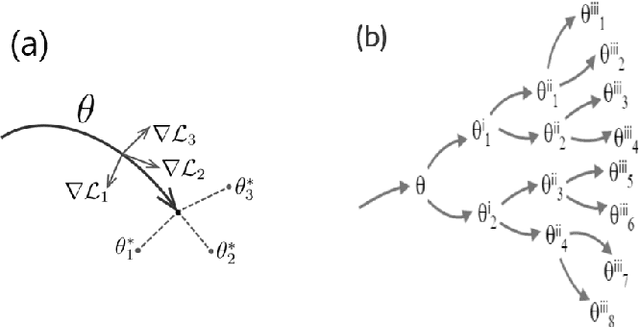

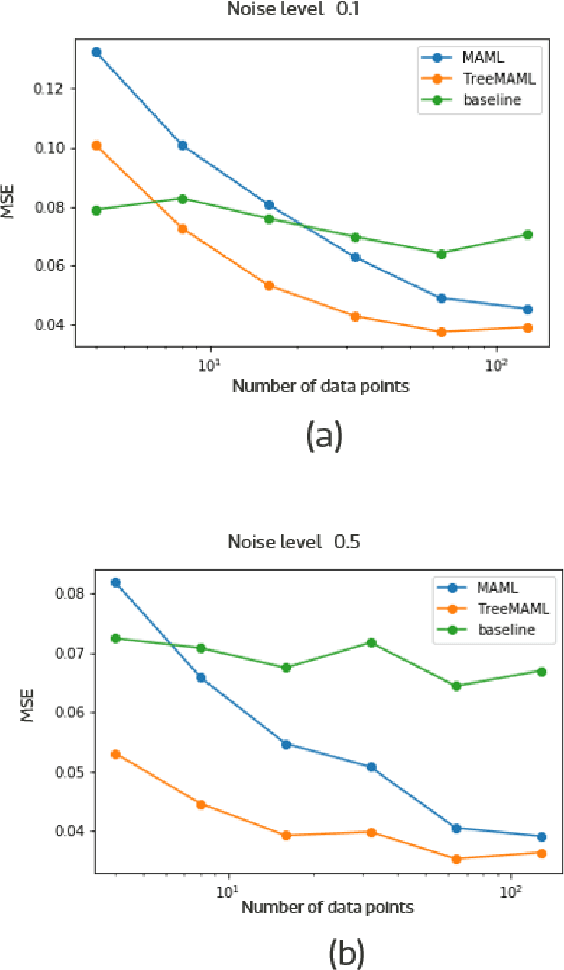
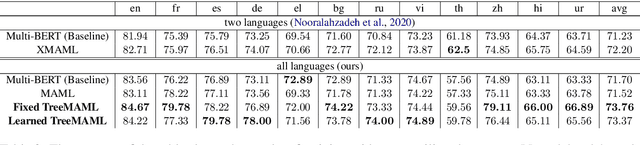
In meta-learning, the knowledge learned from previous tasks is transferred to new ones, but this transfer only works if tasks are related. Sharing information between unrelated tasks might hurt performance, and it is unclear how to transfer knowledge across tasks with a hierarchical structure. Our research extends a model agnostic meta-learning model, MAML, by exploiting hierarchical task relationships. Our algorithm, TreeMAML, adapts the model to each task with a few gradient steps, but the adaptation follows the hierarchical tree structure: in each step, gradients are pooled across tasks clusters, and subsequent steps follow down the tree. We also implement a clustering algorithm that generates the tasks tree without previous knowledge of the task structure, allowing us to make use of implicit relationships between the tasks. We show that the new algorithm, which we term TreeMAML, performs better than MAML when the task structure is hierarchical for synthetic experiments. To study the performance of the method in real-world data, we apply this method to Natural Language Understanding, we use our algorithm to finetune Language Models taking advantage of the language phylogenetic tree. We show that TreeMAML improves the state of the art results for cross-lingual Natural Language Inference. This result is useful, since most languages in the world are under-resourced and the improvement on cross-lingual transfer allows the internationalization of NLP models. This results open the window to use this algorithm in other real-world hierarchical datasets.
Cyclic orthogonal convolutions for long-range integration of features
Dec 11, 2020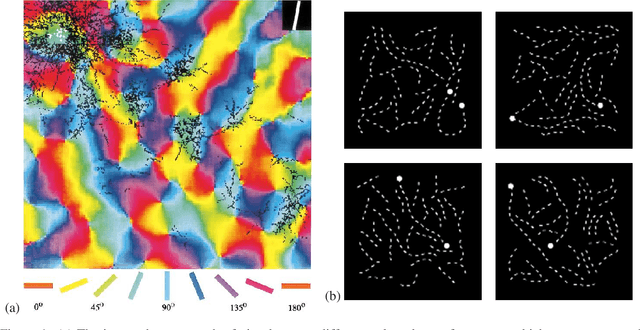

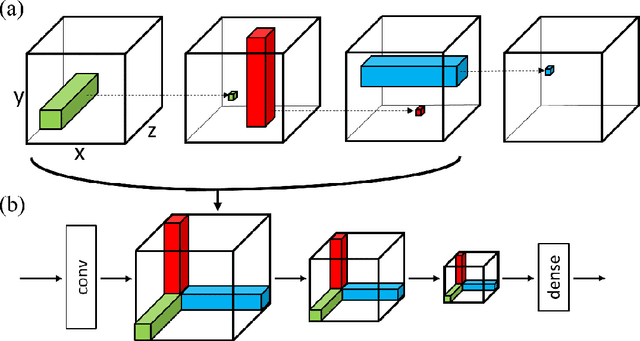
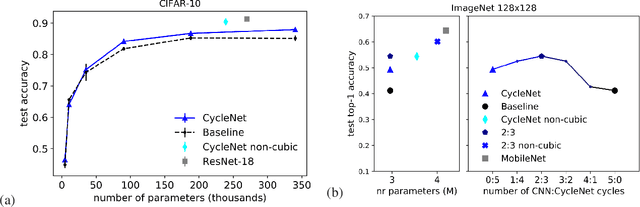
In Convolutional Neural Networks (CNNs) information flows across a small neighbourhood of each pixel of an image, preventing long-range integration of features before reaching deep layers in the network. We propose a novel architecture that allows flexible information flow between features $z$ and locations $(x,y)$ across the entire image with a small number of layers. This architecture uses a cycle of three orthogonal convolutions, not only in $(x,y)$ coordinates, but also in $(x,z)$ and $(y,z)$ coordinates. We stack a sequence of such cycles to obtain our deep network, named CycleNet. As this only requires a permutation of the axes of a standard convolution, its performance can be directly compared to a CNN. Our model obtains competitive results at image classification on CIFAR-10 and ImageNet datasets, when compared to CNNs of similar size. We hypothesise that long-range integration favours recognition of objects by shape rather than texture, and we show that CycleNet transfers better than CNNs to stylised images. On the Pathfinder challenge, where integration of distant features is crucial, CycleNet outperforms CNNs by a large margin. We also show that even when employing a small convolutional kernel, the size of receptive fields of CycleNet reaches its maximum after one cycle, while conventional CNNs require a large number of layers.