 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Think: Multiple Concurrent Reasoning Agents Collaborating at Token Level Granularity
May 16, 2025Recent advances in large language models (LLMs) have demonstrated the power of reasoning through self-generated chains of thought. Multiple reasoning agents can collaborate to raise joint reasoning quality above individual outcomes. However, such agents typically interact in a turn-based manner, trading increased latency for improved quality. In this paper, we propose Group Think--a single LLM that acts as multiple concurrent reasoning agents, or thinkers. With shared visibility into each other's partial generation progress, Group Think introduces a new concurrent-reasoning paradigm in which multiple reasoning trajectories adapt dynamically to one another at the token level. For example, a reasoning thread may shift its generation mid-sentence upon detecting that another thread is better positioned to continue. This fine-grained, token-level collaboration enables Group Think to reduce redundant reasoning and improve quality while achieving significantly lower latency. Moreover, its concurrent nature allows for efficient utilization of idle computational resources, making it especially suitable for edge inference, where very small batch size often underutilizes local~GPUs. We give a simple and generalizable modification that enables any existing LLM to perform Group Think on a local GPU. We also present an evaluation strategy to benchmark reasoning latency and empirically demonstrate latency improvements using open-source LLMs that were not explicitly trained for Group Think. We hope this work paves the way for future LLMs to exhibit more sophisticated and more efficient collaborative behavior for higher quality generation.
Efficient Model Compression Techniques with FishLeg
Dec 03, 2024



In many domains, the most successful AI models tend to be the largest, indeed often too large to be handled by AI players with limited computational resources. To mitigate this, a number of compression methods have been developed, including methods that prune the network down to high sparsity whilst retaining performance. The best-performing pruning techniques are often those that use second-order curvature information (such as an estimate of the Fisher information matrix) to score the importance of each weight and to predict the optimal compensation for weight deletion. However, these methods are difficult to scale to high-dimensional parameter spaces without making heavy approximations. Here, we propose the FishLeg surgeon (FLS), a new second-order pruning method based on the Fisher-Legendre (FishLeg) optimizer. At the heart of FishLeg is a meta-learning approach to amortising the action of the inverse FIM, which brings a number of advantages. Firstly, the parameterisation enables the use of flexible tensor factorisation techniques to improve computational and memory efficiency without sacrificing much accuracy, alleviating challenges associated with scalability of most second-order pruning methods. Secondly, directly estimating the inverse FIM leads to less sensitivity to the amplification of stochasticity during inversion, thereby resulting in more precise estimates. Thirdly, our approach also allows for progressive assimilation of the curvature into the parameterisation. In the gradual pruning regime, this results in a more efficient estimate refinement as opposed to re-estimation. We find that FishLeg achieves higher or comparable performance against two common baselines in the area, most notably in the high sparsity regime when considering a ResNet18 model on CIFAR-10 (84% accuracy at 95% sparsity vs 60% for OBS) and TinyIM (53% accuracy at 80% sparsity vs 48% for OBS).
Exact, Tractable Gauss-Newton Optimization in Deep Reversible Architectures Reveal Poor Generalization
Nov 13, 2024


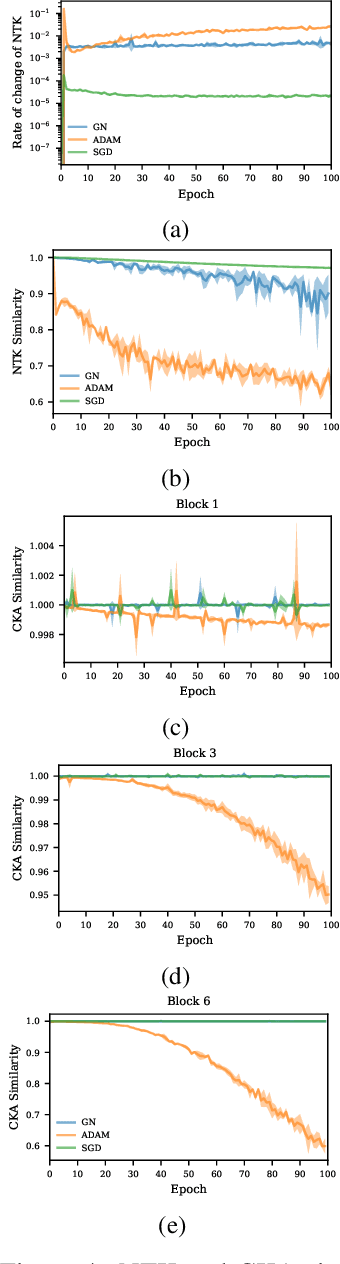
Second-order optimization has been shown to accelerate the training of deep neural networks in many applications, often yielding faster progress per iteration on the training loss compared to first-order optimizers. However, the generalization properties of second-order methods are still being debated. Theoretical investigations have proved difficult to carry out outside the tractable settings of heavily simplified model classes -- thus, the relevance of existing theories to practical deep learning applications remains unclear. Similarly, empirical studies in large-scale models and real datasets are significantly confounded by the necessity to approximate second-order updates in practice. It is often unclear whether the observed generalization behaviour arises specifically from the second-order nature of the parameter updates, or instead reflects the specific structured (e.g.\ Kronecker) approximations used or any damping-based interpolation towards first-order updates. Here, we show for the first time that exact Gauss-Newton (GN) updates take on a tractable form in a class of deep reversible architectures that are sufficiently expressive to be meaningfully applied to common benchmark datasets. We exploit this novel setting to study the training and generalization properties of the GN optimizer. We find that exact GN generalizes poorly. In the mini-batch training setting, this manifests as rapidly saturating progress even on the \emph{training} loss, with parameter updates found to overfit each mini-batchatch without producing the features that would support generalization to other mini-batches. We show that our experiments run in the ``lazy'' regime, in which the neural tangent kernel (NTK) changes very little during the course of training. This behaviour is associated with having no significant changes in neural representations, explaining the lack of generalization.
A Dataset for Learning Graph Representations to Predict Customer Returns in Fashion Retail
Mar 12, 2023We present a novel dataset collected by ASOS (a major online fashion retailer) to address the challenge of predicting customer returns in a fashion retail ecosystem. With the release of this substantial dataset we hope to motivate further collaboration between research communities and the fashion industry. We first explore the structure of this dataset with a focus on the application of Graph Representation Learning in order to exploit the natural data structure and provide statistical insights into particular features within the data. In addition to this, we show examples of a return prediction classification task with a selection of baseline models (i.e. with no intermediate representation learning step) and a graph representation based model. We show that in a downstream return prediction classification task, an F1-score of 0.792 can be found using a Graph Neural Network (GNN), improving upon other models discussed in this work. Alongside this increased F1-score, we also present a lower cross-entropy loss by recasting the data into a graph structure, indicating more robust predictions from a GNN based solution. These results provide evidence that GNNs could provide more impactful and usable classifications than other baseline models on the presented dataset and with this motivation, we hope to encourage further research into graph-based approaches using the ASOS GraphReturns dataset.
* The ASOS GraphReturns dataset can be found at https://osf.io/c793h/. Accepted at FashionXRecSys 2022 workshop. Published Version
Meta-Learning with MAML on Trees
Mar 08, 2021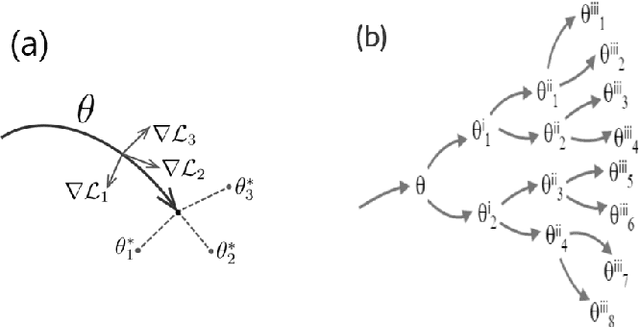

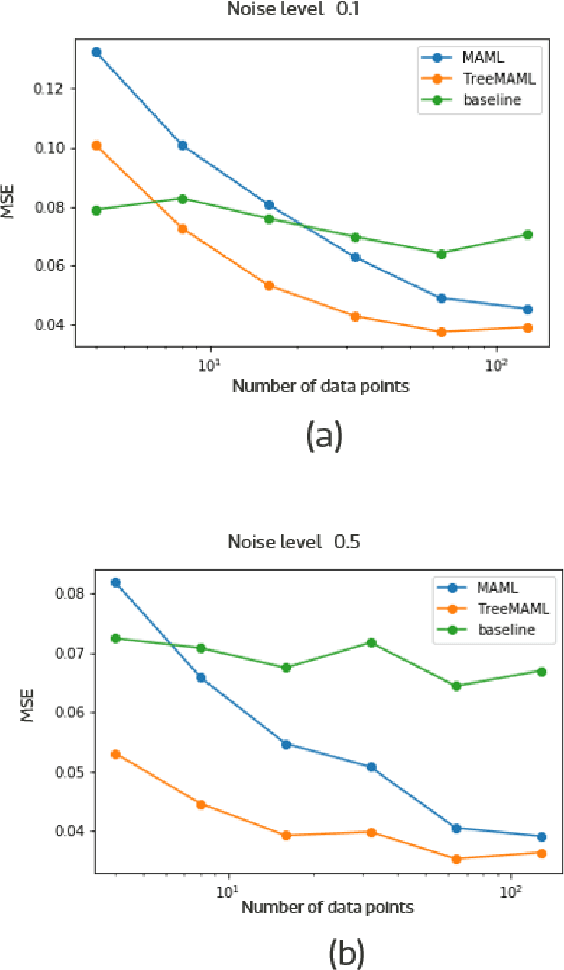
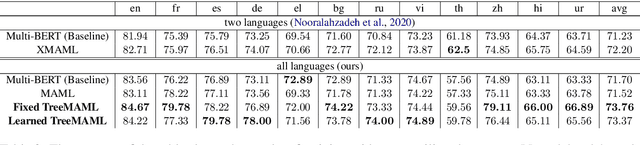
In meta-learning, the knowledge learned from previous tasks is transferred to new ones, but this transfer only works if tasks are related. Sharing information between unrelated tasks might hurt performance, and it is unclear how to transfer knowledge across tasks with a hierarchical structure. Our research extends a model agnostic meta-learning model, MAML, by exploiting hierarchical task relationships. Our algorithm, TreeMAML, adapts the model to each task with a few gradient steps, but the adaptation follows the hierarchical tree structure: in each step, gradients are pooled across tasks clusters, and subsequent steps follow down the tree. We also implement a clustering algorithm that generates the tasks tree without previous knowledge of the task structure, allowing us to make use of implicit relationships between the tasks. We show that the new algorithm, which we term TreeMAML, performs better than MAML when the task structure is hierarchical for synthetic experiments. To study the performance of the method in real-world data, we apply this method to Natural Language Understanding, we use our algorithm to finetune Language Models taking advantage of the language phylogenetic tree. We show that TreeMAML improves the state of the art results for cross-lingual Natural Language Inference. This result is useful, since most languages in the world are under-resourced and the improvement on cross-lingual transfer allows the internationalization of NLP models. This results open the window to use this algorithm in other real-world hierarchical datasets.