 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIA-SEC: Improved Actor-Critic Framework for Multi-UAV Collaborative Control in Smart Agriculture
Dec 21, 2025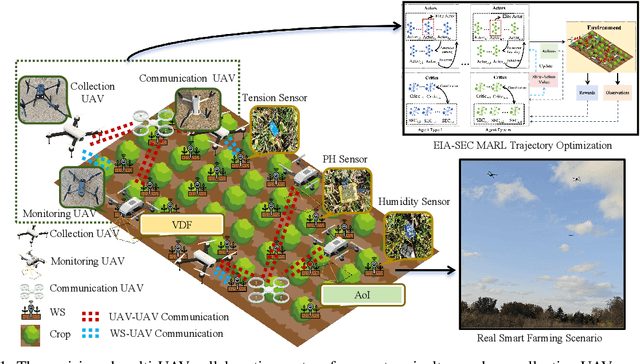
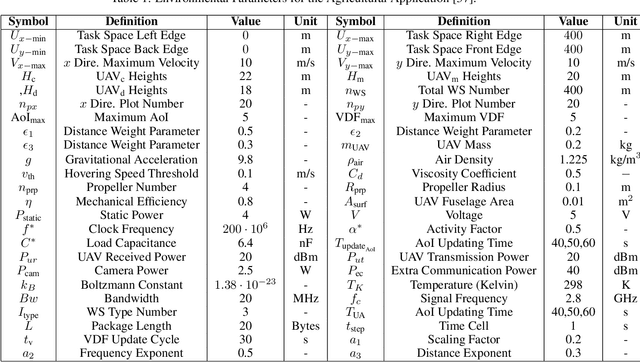
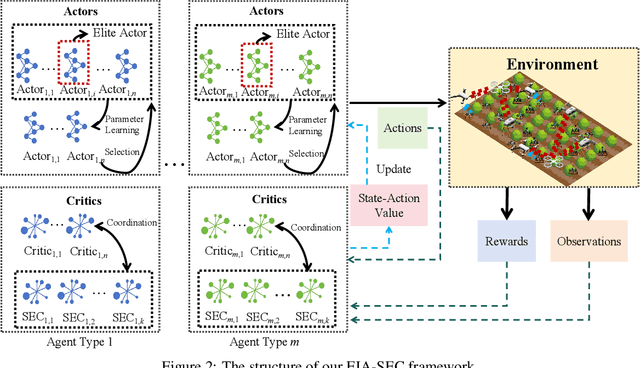
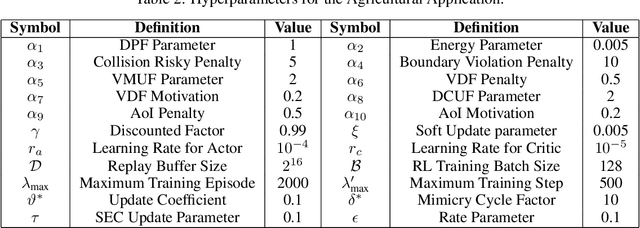
The widespread application of wireless communication technology has promoted the development of smart agriculture, where unmanned aerial vehicles (UAVs) play a multifunctional role. We target a multi-UAV smart agriculture system where UAVs cooperatively perform data collection, image acquisition, and communication tasks. In this context, we model a Markov decision process to solve the multi-UAV trajectory planning problem. Moreover, we propose a novel Elite Imitation Actor-Shared Ensemble Critic (EIA-SEC) framework, where agents adaptively learn from the elite agent to reduce trial-and-error costs, and a shared ensemble critic collaborates with each agent's local critic to ensure unbiased objective value estimates and prevent overestimation. Experimental results demonstrate that EIA-SEC outperforms state-of-the-art baselines in terms of reward performance, training stability, and convergence speed.
Efficient Model Compression Techniques with FishLeg
Dec 03, 2024



In many domains, the most successful AI models tend to be the largest, indeed often too large to be handled by AI players with limited computational resources. To mitigate this, a number of compression methods have been developed, including methods that prune the network down to high sparsity whilst retaining performance. The best-performing pruning techniques are often those that use second-order curvature information (such as an estimate of the Fisher information matrix) to score the importance of each weight and to predict the optimal compensation for weight deletion. However, these methods are difficult to scale to high-dimensional parameter spaces without making heavy approximations. Here, we propose the FishLeg surgeon (FLS), a new second-order pruning method based on the Fisher-Legendre (FishLeg) optimizer. At the heart of FishLeg is a meta-learning approach to amortising the action of the inverse FIM, which brings a number of advantages. Firstly, the parameterisation enables the use of flexible tensor factorisation techniques to improve computational and memory efficiency without sacrificing much accuracy, alleviating challenges associated with scalability of most second-order pruning methods. Secondly, directly estimating the inverse FIM leads to less sensitivity to the amplification of stochasticity during inversion, thereby resulting in more precise estimates. Thirdly, our approach also allows for progressive assimilation of the curvature into the parameterisation. In the gradual pruning regime, this results in a more efficient estimate refinement as opposed to re-estimation. We find that FishLeg achieves higher or comparable performance against two common baselines in the area, most notably in the high sparsity regime when considering a ResNet18 model on CIFAR-10 (84% accuracy at 95% sparsity vs 60% for OBS) and TinyIM (53% accuracy at 80% sparsity vs 48% for OBS).
A Novel Framework of Horizontal-Vertical Hybrid Federated Learning for EdgeIoT
Oct 02, 2024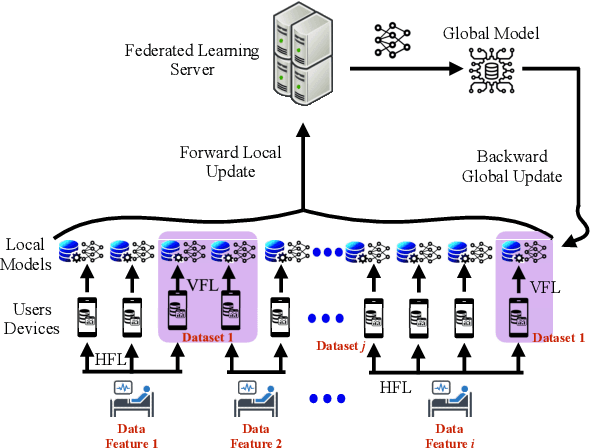
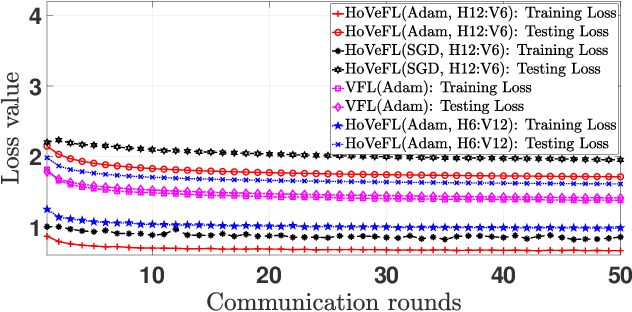
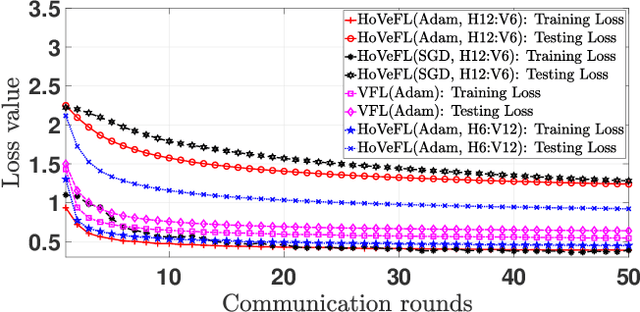
This letter puts forth a new hybrid horizontal-vertical federated learning (HoVeFL) for mobile edge computing-enabled Internet of Things (EdgeIoT). In this framework, certain EdgeIoT devices train local models using the same data samples but analyze disparate data features, while the others focus on the same features using non-independent and identically distributed (non-IID) data samples. Thus, even though the data features are consistent, the data samples vary across devices. The proposed HoVeFL formulates the training of local and global models to minimize the global loss function. Performance evaluations on CIFAR-10 and SVHN datasets reveal that the testing loss of HoVeFL with 12 horizontal FL devices and six vertical FL devices is 5.5% and 25.2% higher, respectively, compared to a setup with six horizontal FL devices and 12 vertical FL devices.
Federated Split GANs
Jul 04, 2022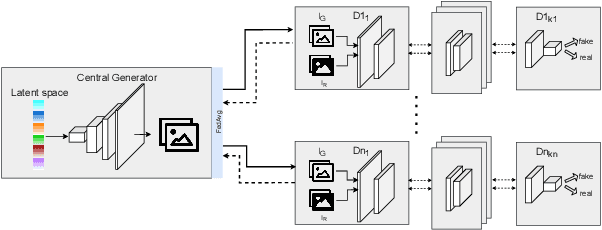
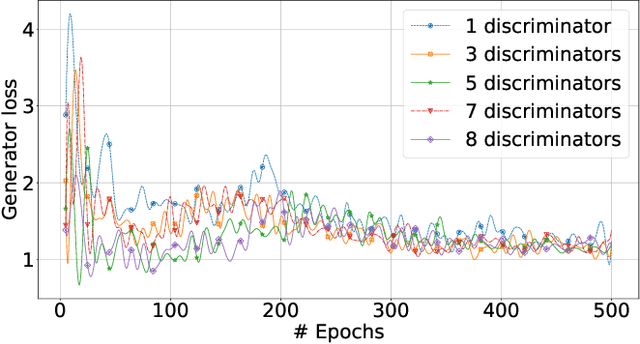

Mobile devices and the immense amount and variety of data they generate are key enablers of machine learning (ML)-based applications. Traditional ML techniques have shifted toward new paradigms such as federated (FL) and split learning (SL) to improve the protection of user's data privacy. However, these paradigms often rely on server(s) located in the edge or cloud to train computationally-heavy parts of a ML model to avoid draining the limited resource on client devices, resulting in exposing device data to such third parties. This work proposes an alternative approach to train computationally-heavy ML models in user's devices themselves, where corresponding device data resides. Specifically, we focus on GANs (generative adversarial networks) and leverage their inherent privacy-preserving attribute. We train the discriminative part of a GAN with raw data on user's devices, whereas the generative model is trained remotely (e.g., server) for which there is no need to access sensor true data. Moreover, our approach ensures that the computational load of training the discriminative model is shared among user's devices-proportional to their computation capabilities-by means of SL. We implement our proposed collaborative training scheme of a computationally-heavy GAN model in real resource-constrained devices. The results show that our system preserves data privacy, keeps a short training time, and yields same accuracy of model training in unconstrained devices (e.g., cloud). Our code can be found on https://github.com/YukariSonz/FSL-GAN