 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic World Models: Efficient Exploration in Model-Based Deep Reinforcement Learning
Feb 10, 2026Efficient exploration remains a central challenge in reinforcement learning (RL), particularly in sparse-reward environments. We introduce Optimistic World Models (OWMs), a principled and scalable framework for optimistic exploration that brings classical reward-biased maximum likelihood estimation (RBMLE) from adaptive control into deep RL. In contrast to upper confidence bound (UCB)-style exploration methods, OWMs incorporate optimism directly into model learning by augmentation with an optimistic dynamics loss that biases imagined transitions toward higher-reward outcomes. This fully gradient-based loss requires neither uncertainty estimates nor constrained optimization. Our approach is plug-and-play with existing world model frameworks, preserving scalability while requiring only minimal modifications to standard training procedures. We instantiate OWMs within two state-of-the-art world model architectures, leading to Optimistic DreamerV3 and Optimistic STORM, which demonstrate significant improvements in sample efficiency and cumulative return compared to their baseline counterparts.
On Task-Adaptive Pretraining for Dialogue Response Selection
Oct 08, 2022
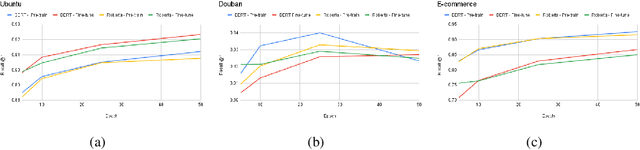
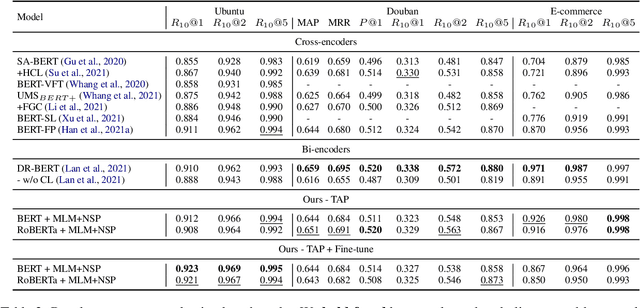
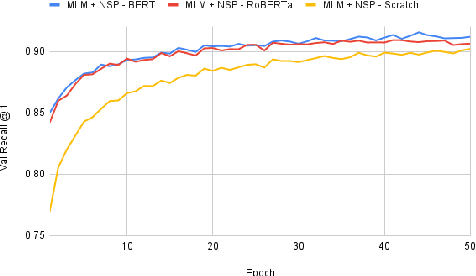
Recent advancements in dialogue response selection (DRS) are based on the \textit{task-adaptive pre-training (TAP)} approach, by first initializing their model with BERT~\cite{devlin-etal-2019-bert}, and adapt to dialogue data with dialogue-specific or fine-grained pre-training tasks. However, it is uncertain whether BERT is the best initialization choice, or whether the proposed dialogue-specific fine-grained learning tasks are actually better than MLM+NSP. This paper aims to verify assumptions made in previous works and understand the source of improvements for DRS. We show that initializing with RoBERTa achieve similar performance as BERT, and MLM+NSP can outperform all previously proposed TAP tasks, during which we also contribute a new state-of-the-art on the Ubuntu corpus. Additional analyses shows that the main source of improvements comes from the TAP step, and that the NSP task is crucial to DRS, different from common NLU tasks.
Silent Tracker: In-band Beam Management for Soft Handover for mm-Wave Networks
Jul 18, 2021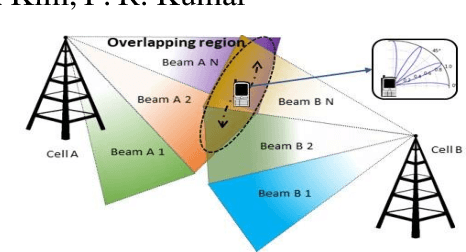
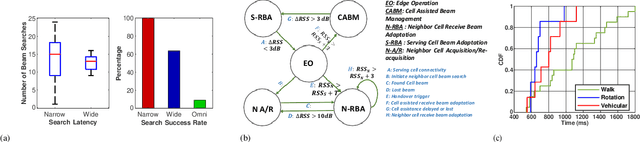
In mm-wave networks, cell sizes are small due to high path and penetration losses. Mobiles need to frequently switch softly from one cell to another to preserve network connections and context. Each soft handover involves the mobile performing directional neighbor cell search, tracking cell beam, completing cell access request, and finally, context switching. The mobile must independently discover cell beams, derive timing information, and maintain beam alignment throughout the process to avoid packet loss and hard handover. We propose Silent tracker which enables a mobile to reliably manage handover events by maintaining an aligned beam until the successful handover completion. It is entirely in-band beam mechanism that does not need any side information. Experimental evaluations show that Silent Tracker maintains the mobile's receive beam aligned to the potential target base station's transmit beam till the successful conclusion of handover in three mobility scenarios: human walk, device rotation, and 20 mph vehicular speed.
Robust Handwriting Recognition with Limited and Noisy Data
Aug 18, 2020

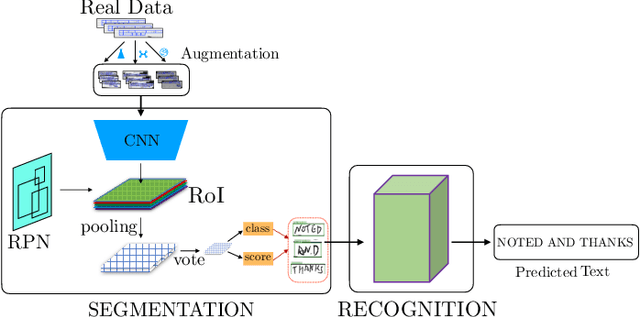
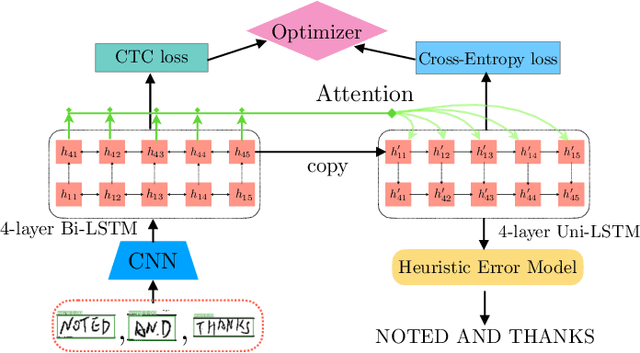
Despite the advent of deep learning in computer vision, the general handwriting recognition problem is far from solved. Most existing approaches focus on handwriting datasets that have clearly written text and carefully segmented labels. In this paper, we instead focus on learning handwritten characters from maintenance logs, a constrained setting where data is very limited and noisy. We break the problem into two consecutive stages of word segmentation and word recognition respectively and utilize data augmentation techniques to train both stages. Extensive comparisons with popular baselines for scene-text detection and word recognition show that our system achieves a lower error rate and is more suited to handle noisy and difficult documents
A Multimodal Dialogue System for Conversational Image Editing
Feb 16, 2020
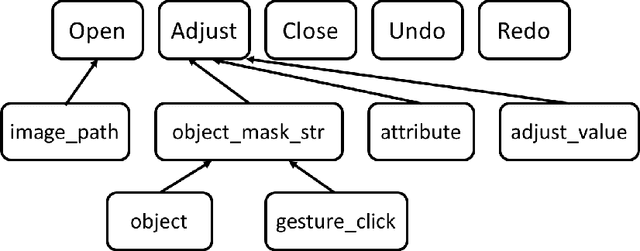
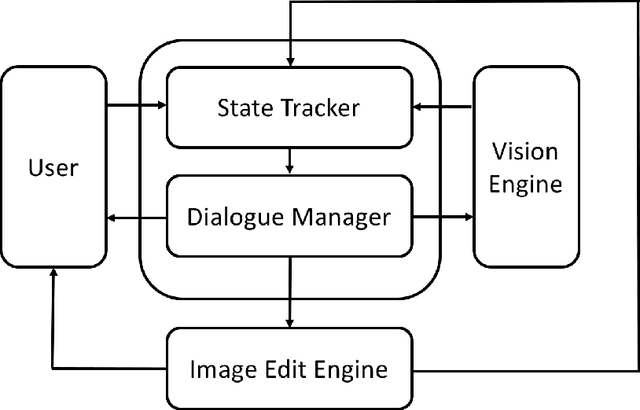
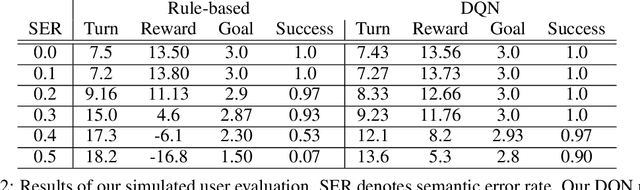
In this paper, we present a multimodal dialogue system for Conversational Image Editing. We formulate our multimodal dialogue system as a Partially Observed Markov Decision Process (POMDP) and trained it with Deep Q-Network (DQN) and a user simulator. Our evaluation shows that the DQN policy outperforms a rule-based baseline policy, achieving 90\% success rate under high error rates. We also conducted a real user study and analyzed real user behavior.
Adjusting Image Attributes of Localized Regions with Low-level Dialogue
Feb 11, 2020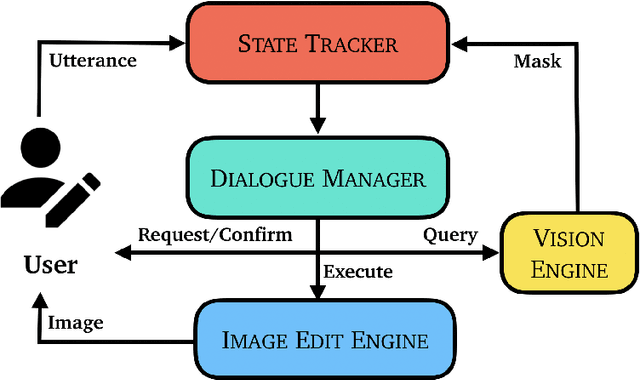

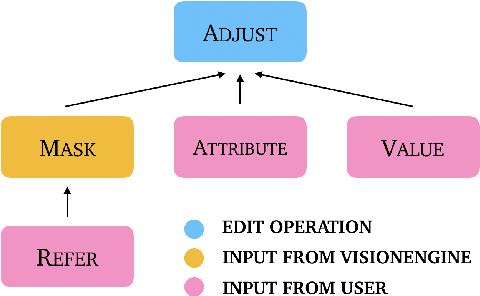

Natural Language Image Editing (NLIE) aims to use natural language instructions to edit images. Since novices are inexperienced with image editing techniques, their instructions are often ambiguous and contain high-level abstractions that tend to correspond to complex editing steps to accomplish. Motivated by this inexperience aspect, we aim to smooth the learning curve by teaching the novices to edit images using low-level commanding terminologies. Towards this end, we develop a task-oriented dialogue system to investigate low-level instructions for NLIE. Our system grounds language on the level of edit operations, and suggests options for a user to choose from. Though compelled to express in low-level terms, a user evaluation shows that 25% of users found our system easy-to-use, resonating with our motivation. An analysis shows that users generally adapt to utilizing the proposed low-level language interface. In this study, we identify that object segmentation as the key factor to the user satisfaction. Our work demonstrates the advantages of the low-level, direct language-action mapping approach that can be applied to other problem domains beyond image editing such as audio editing or industrial design.
Interactive Spoken Content Retrieval by Deep Reinforcement Learning
Sep 16, 2016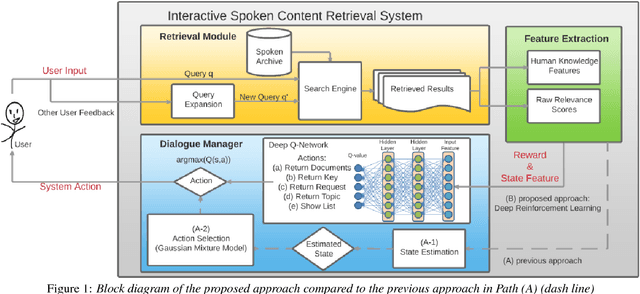
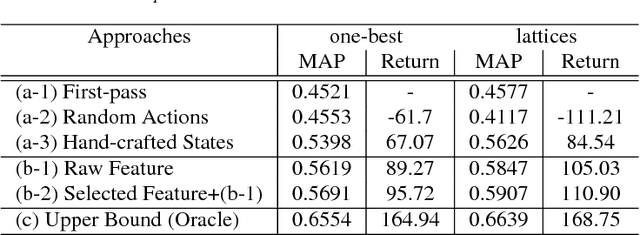
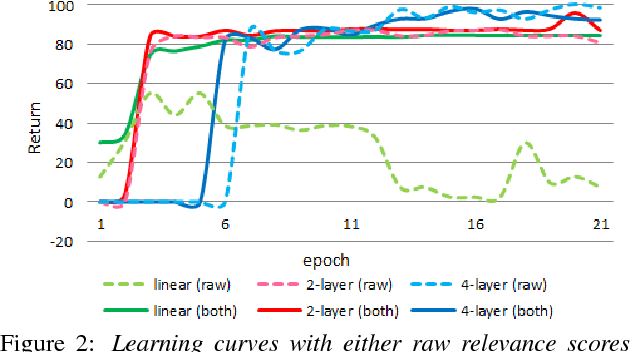
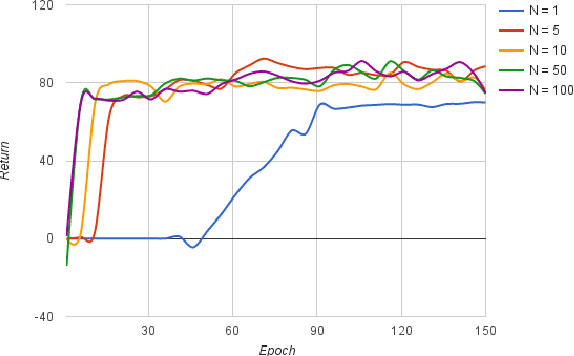
User-machine interaction is important for spoken content retrieval. For text content retrieval, the user can easily scan through and select on a list of retrieved item. This is impossible for spoken content retrieval, because the retrieved items are difficult to show on screen. Besides, due to the high degree of uncertainty for speech recognition, the retrieval results can be very noisy. One way to counter such difficulties is through user-machine interaction. The machine can take different actions to interact with the user to obtain better retrieval results before showing to the user. The suitable actions depend on the retrieval status, for example requesting for extra information from the user, returning a list of topics for user to select, etc. In our previous work, some hand-crafted states estimated from the present retrieval results are used to determine the proper actions. In this paper, we propose to use Deep-Q-Learning techniques instead to determine the machine actions for interactive spoken content retrieval. Deep-Q-Learning bypasses the need for estimation of the hand-crafted states, and directly determine the best action base on the present retrieval status even without any human knowledge. It is shown to achieve significantly better performance compared with the previous hand-crafted states.